 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALIGNet: Partial-Shape Agnostic Alignment via Unsupervised Learning
Oct 30, 2018
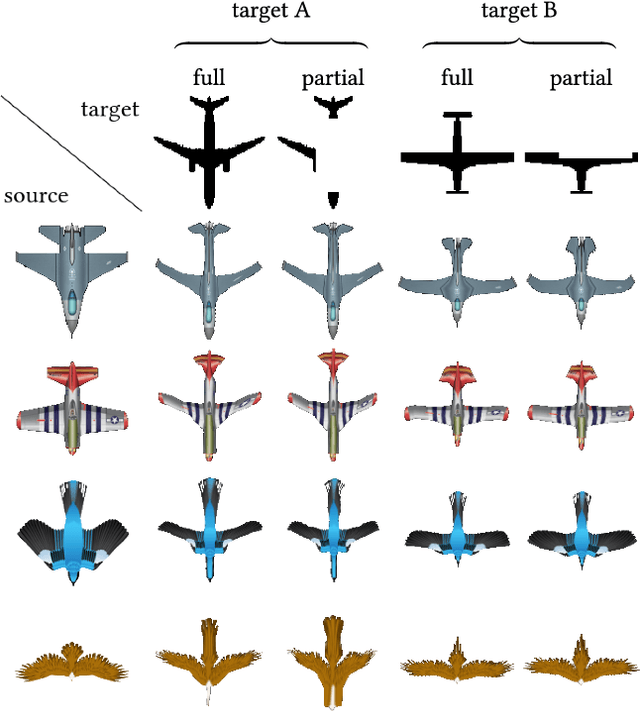

The process of aligning a pair of shapes is a fundamental operation in computer graphics. Traditional approaches rely heavily on matching corresponding points or features to guide the alignment, a paradigm that falters when significant shape portions are missing. These techniques generally do not incorporate prior knowledge about expected shape characteristics, which can help compensate for any misleading cues left by inaccuracies exhibited in the input shapes. We present an approach based on a deep neural network, leveraging shape datasets to learn a shape-aware prior for source-to-target alignment that is robust to shape incompleteness. In the absence of ground truth alignments for supervision, we train a network on the task of shape alignment using incomplete shapes generated from full shapes for self-supervision. Our network, called ALIGNet, is trained to warp complete source shapes to incomplete targets, as if the target shapes were complete, thus essentially rendering the alignment partial-shape agnostic. We aim for the network to develop specialized expertise over the common characteristics of the shapes in each dataset, thereby achieving a higher-level understanding of the expected shape space to which a local approach would be oblivious. We constrain ALIGNet through an anisotropic total variation identity regularization to promote piecewise smooth deformation fields, facilitating both partial-shape agnosticism and post-deformation applications. We demonstrate that ALIGNet learns to align geometrically distinct shapes, and is able to infer plausible mappings even when the target shape is significantly incomplete. We show that our network learns the common expected characteristics of shape collections, without over-fitting or memorization, enabling it to produce plausible deformations on unseen data during test time.
Generative Low-Shot Network Expansion
Oct 19, 2018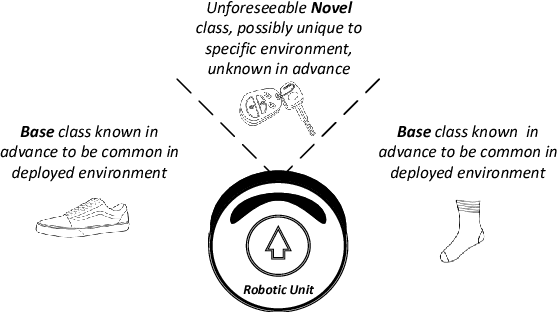
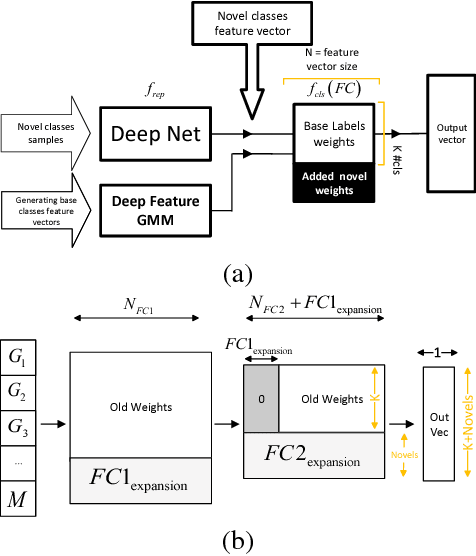
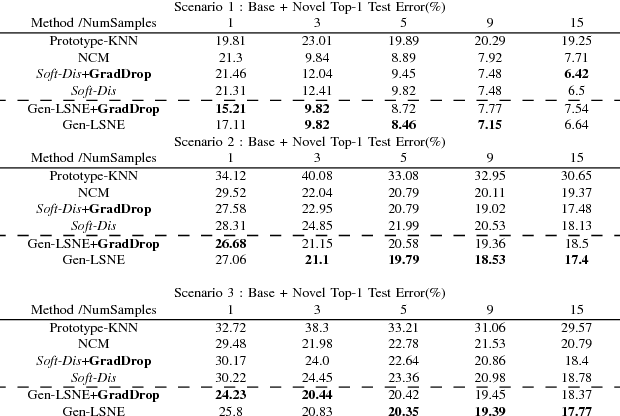
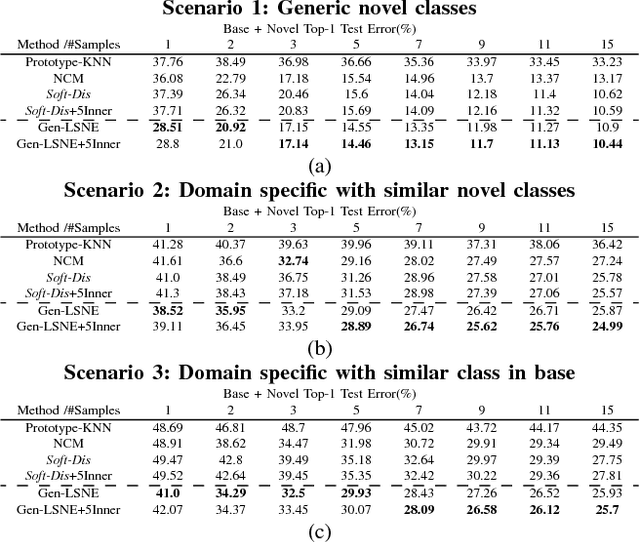
Conventional deep learning classifiers are static in the sense that they are trained on a predefined set of classes and learning to classify a novel class typically requires re-training. In this work, we address the problem of Low-Shot network expansion learning. We introduce a learning framework which enables expanding a pre-trained (base) deep network to classify novel classes when the number of examples for the novel classes is particularly small. We present a simple yet powerful hard distillation method where the base network is augmented with additional weights to classify the novel classes, while keeping the weights of the base network unchanged. We show that since only a small number of weights needs to be trained, the hard distillation excels in low-shot training scenarios. Furthermore, hard distillation avoids detriment to classification performance on the base classes. Finally, we show that low-shot network expansion can be done with a very small memory footprint by using a compact generative model of the base classes training data with only a negligible degradation relative to learning with the full training set.
MeshCNN: A Network with an Edge
Sep 16, 2018
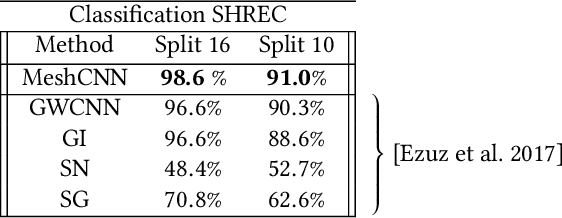
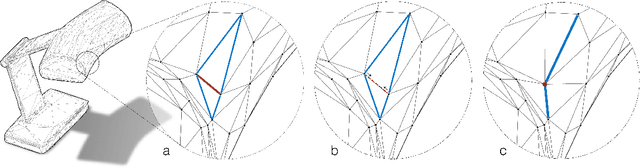
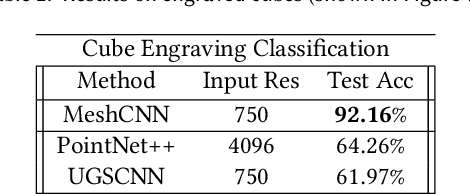
A polygonal mesh representation provides an efficient approximation for 3D shapes. It explicitly captures both shape surface and topology, and leverages non-uniformity to represent large flat regions as well as sharp, intricate features. This non-uniformity and irregularity, however, inhibits mesh analysis efforts using neural networks that combine convolution and pooling operations. In this paper, we utilize the unique properties of the mesh for a direct analysis of 3D shapes using MeshCNN, a convolutional neural network designed specifically for triangular meshes. Analogous to classic CNNs, MeshCNN combines specialized convolution and pooling layers that operate on the mesh edges, by leveraging their intrinsic geodesic connections. Convolutions are applied on edges and the four edges of their incident triangles, and pooling is applied via an edge collapse operation that retains surface topology, thereby, generating new mesh connectivity for the subsequent convolutions. MeshCNN learns which edges to collapse, thus forming a task-driven process where the network exposes and expands the important features while discarding the redundant ones. We demonstrate the effectiveness of our task-driven pooling on various learning tasks applied to 3D meshes.
Novelty Detection with GAN
Feb 28, 2018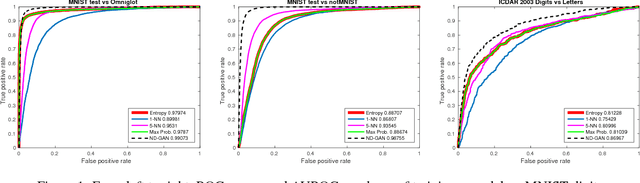

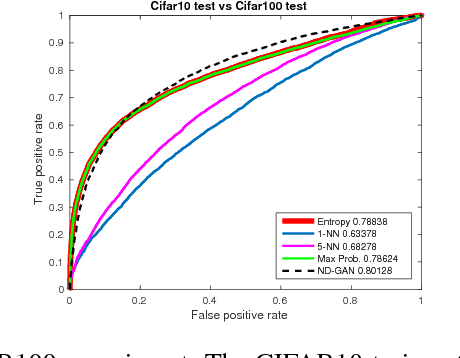
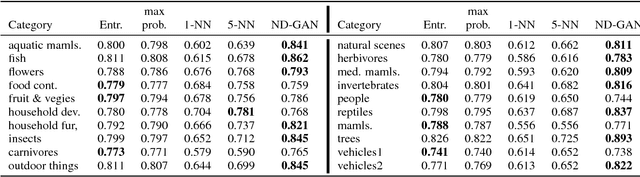
The ability of a classifier to recognize unknown inputs is important for many classification-based systems. We discuss the problem of simultaneous classification and novelty detection, i.e. determining whether an input is from the known set of classes and from which specific class, or from an unknown domain and does not belong to any of the known classes. We propose a method based on the Generative Adversarial Networks (GAN) framework. We show that a multi-class discriminator trained with a generator that generates samples from a mixture of nominal and novel data distributions is the optimal novelty detector. We approximate that generator with a mixture generator trained with the Feature Matching loss and empirically show that the proposed method outperforms conventional methods for novelty detection. Our findings demonstrate a simple, yet powerful new application of the GAN framework for the task of novelty detection.