 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswer-Me: Multi-Task Open-Vocabulary Visual Question Answering
Paper and Code
May 02, 2022
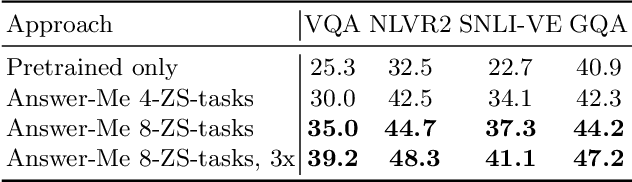
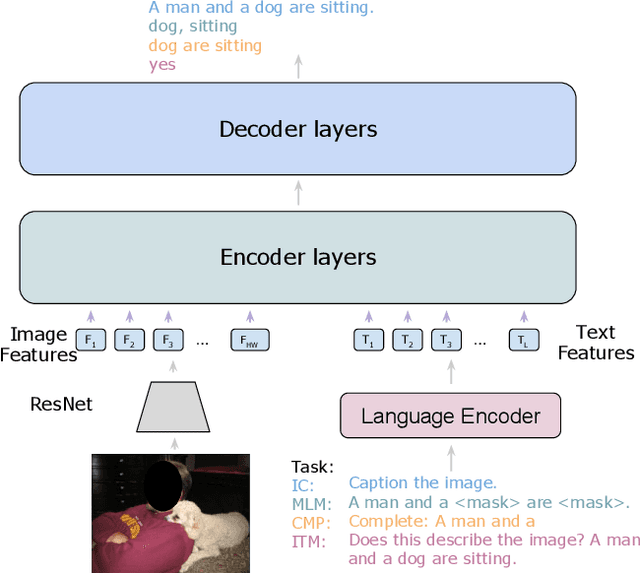
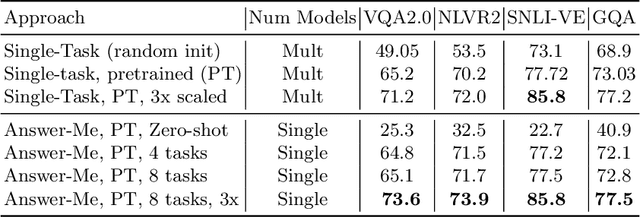
We present Answer-Me, a task-aware multi-task framework which unifies a variety of question answering tasks, such as, visual question answering, visual entailment, visual reasoning. In contrast to previous works using contrastive or generative captioning training, we propose a novel and simple recipe to pre-train a vision-language joint model, which is multi-task as well. The pre-training uses only noisy image captioning data, and is formulated to use the entire architecture end-to-end with both a strong language encoder and decoder. Our results show state-of-the-art performance, zero-shot generalization, robustness to forgetting, and competitive single-task results across a variety of question answering tasks. Our multi-task mixture training learns from tasks of various question intents and thus generalizes better, including on zero-shot vision-language tasks. We conduct experiments in the challenging multi-task and open-vocabulary settings and across a variety of datasets and tasks, such as VQA2.0, SNLI-VE, NLVR2, GQA, VizWiz. We observe that the proposed approach is able to generalize to unseen tasks and that more diverse mixtures lead to higher accuracy in both known and novel tasks.