 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrainformers: Trading Simplicity for Efficiency
May 29, 2023



Transformers are central to recent successes in natural language processing and computer vision. Transformers have a mostly uniform backbone where layers alternate between feed-forward and self-attention in order to build a deep network. Here we investigate this design choice and find that more complex blocks that have different permutations of layer primitives can be more efficient. Using this insight, we develop a complex block, named Brainformer, that consists of a diverse sets of layers such as sparsely gated feed-forward layers, dense feed-forward layers, attention layers, and various forms of layer normalization and activation functions. Brainformer consistently outperforms the state-of-the-art dense and sparse Transformers, in terms of both quality and efficiency. A Brainformer model with 8 billion activated parameters per token demonstrates 2x faster training convergence and 5x faster step time compared to its GLaM counterpart. In downstream task evaluation, Brainformer also demonstrates a 3% higher SuperGLUE score with fine-tuning compared to GLaM with a similar number of activated parameters. Finally, Brainformer largely outperforms a Primer dense model derived with NAS with similar computation per token on fewshot evaluations.
The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink
Apr 11, 2022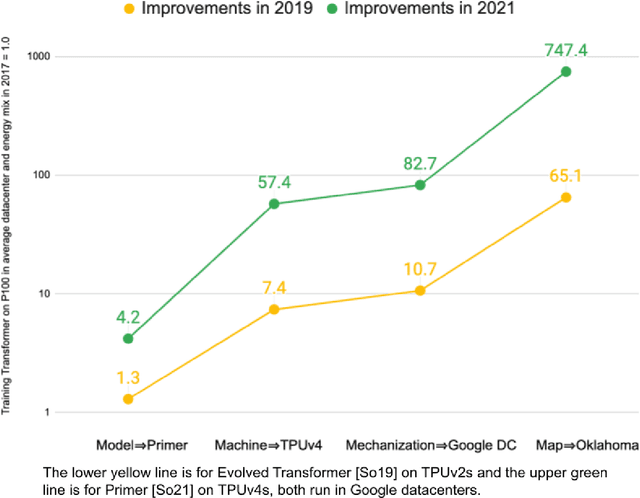
Machine Learning (ML) workloads have rapidly grown in importance, but raised concerns about their carbon footprint. Four best practices can reduce ML training energy by up to 100x and CO2 emissions up to 1000x. By following best practices, overall ML energy use (across research, development, and production) held steady at <15% of Google's total energy use for the past three years. If the whole ML field were to adopt best practices, total carbon emissions from training would reduce. Hence, we recommend that ML papers include emissions explicitly to foster competition on more than just model quality. Estimates of emissions in papers that omitted them have been off 100x-100,000x, so publishing emissions has the added benefit of ensuring accurate accounting. Given the importance of climate change, we must get the numbers right to make certain that we work on its biggest challenges.
Carbon Emissions and Large Neural Network Training
Apr 23, 2021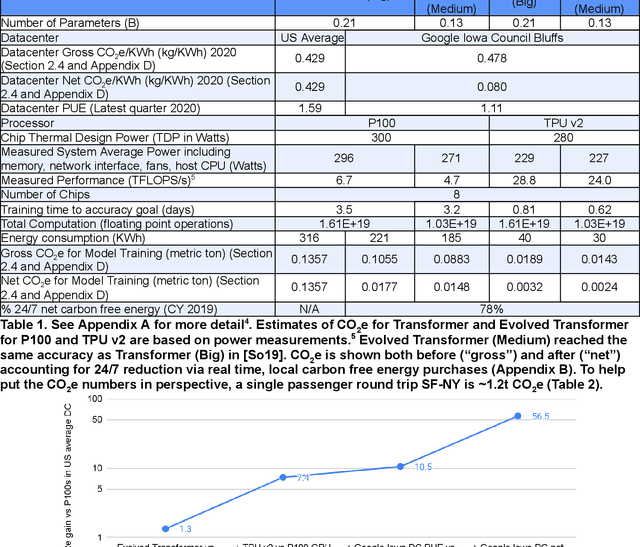

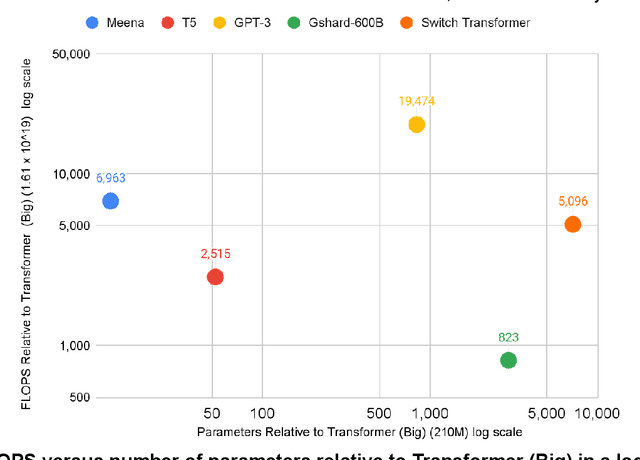
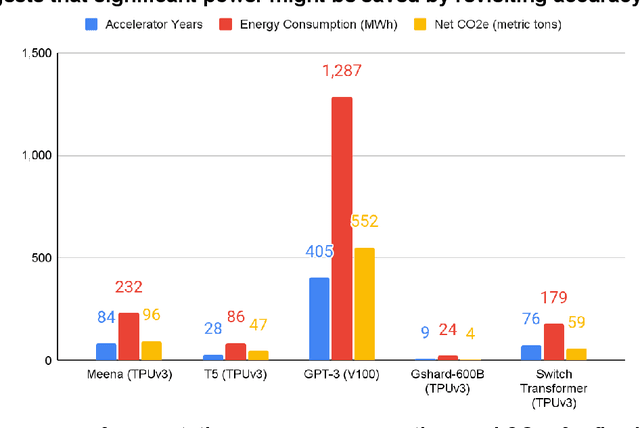
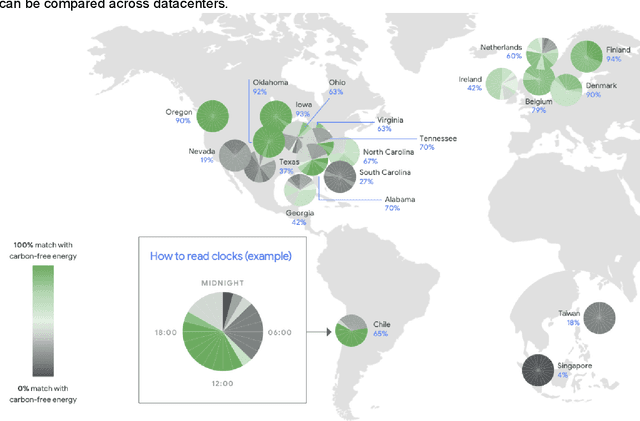
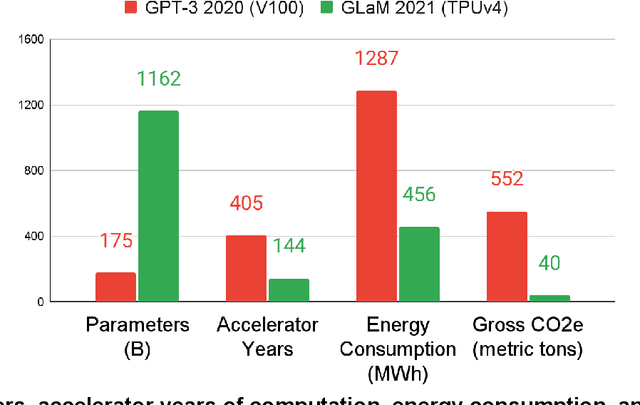
The computation demand for machine learning (ML) has grown rapidly recently, which comes with a number of costs. Estimating the energy cost helps measure its environmental impact and finding greener strategies, yet it is challenging without detailed information. We calculate the energy use and carbon footprint of several recent large models-T5, Meena, GShard, Switch Transformer, and GPT-3-and refine earlier estimates for the neural architecture search that found Evolved Transformer. We highlight the following opportunities to improve energy efficiency and CO2 equivalent emissions (CO2e): Large but sparsely activated DNNs can consume <1/10th the energy of large, dense DNNs without sacrificing accuracy despite using as many or even more parameters. Geographic location matters for ML workload scheduling since the fraction of carbon-free energy and resulting CO2e vary ~5X-10X, even within the same country and the same organization. We are now optimizing where and when large models are trained. Specific datacenter infrastructure matters, as Cloud datacenters can be ~1.4-2X more energy efficient than typical datacenters, and the ML-oriented accelerators inside them can be ~2-5X more effective than off-the-shelf systems. Remarkably, the choice of DNN, datacenter, and processor can reduce the carbon footprint up to ~100-1000X. These large factors also make retroactive estimates of energy cost difficult. To avoid miscalculations, we believe ML papers requiring large computational resources should make energy consumption and CO2e explicit when practical. We are working to be more transparent about energy use and CO2e in our future research. To help reduce the carbon footprint of ML, we believe energy usage and CO2e should be a key metric in evaluating models, and we are collaborating with MLPerf developers to include energy usage during training and inference in this industry standard benchmark.
Improving image generative models with human interactions
Sep 29, 2017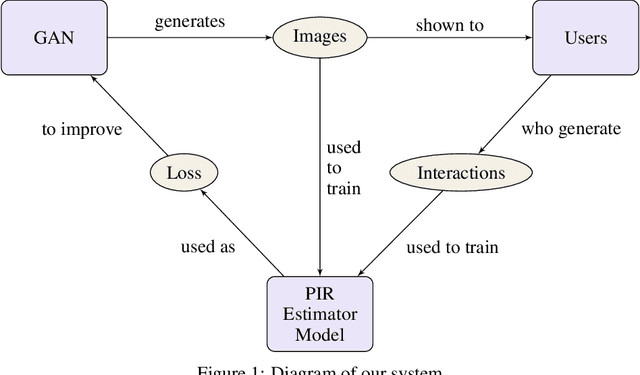
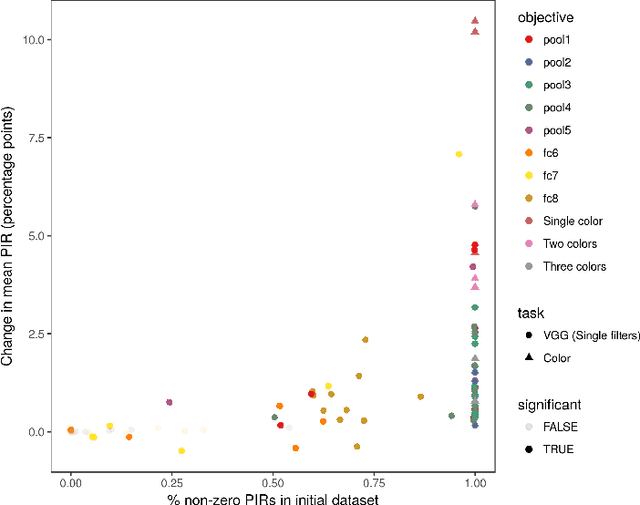

GANs provide a framework for training generative models which mimic a data distribution. However, in many cases we wish to train these generative models to optimize some auxiliary objective function within the data it generates, such as making more aesthetically pleasing images. In some cases, these objective functions are difficult to evaluate, e.g. they may require human interaction. Here, we develop a system for efficiently improving a GAN to target an objective involving human interaction, specifically generating images that increase rates of positive user interactions. To improve the generative model, we build a model of human behavior in the targeted domain from a relatively small set of interactions, and then use this behavioral model as an auxiliary loss function to improve the generative model. We show that this system is successful at improving positive interaction rates, at least on simulated data, and characterize some of the factors that affect its performance.