 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Topic Pages for Scientific Concepts Using Scientific Publications
Apr 24, 2023In this paper, we describe Topic Pages, an inventory of scientific concepts and information around them extracted from a large collection of scientific books and journals. The main aim of Topic Pages is to provide all the necessary information to the readers to understand scientific concepts they come across while reading scholarly content in any scientific domain. Topic Pages are a collection of automatically generated information pages using NLP and ML, each corresponding to a scientific concept. Each page contains three pieces of information: a definition, related concepts, and the most relevant snippets, all extracted from scientific peer-reviewed publications. In this paper, we discuss the details of different components to extract each of these elements. The collection of pages in production contains over 360,000 Topic Pages across 20 different scientific domains with an average of 23 million unique visits per month, constituting it a popular source for scientific information.
Text Relatedness Based on a Word Thesaurus
Jan 15, 2014
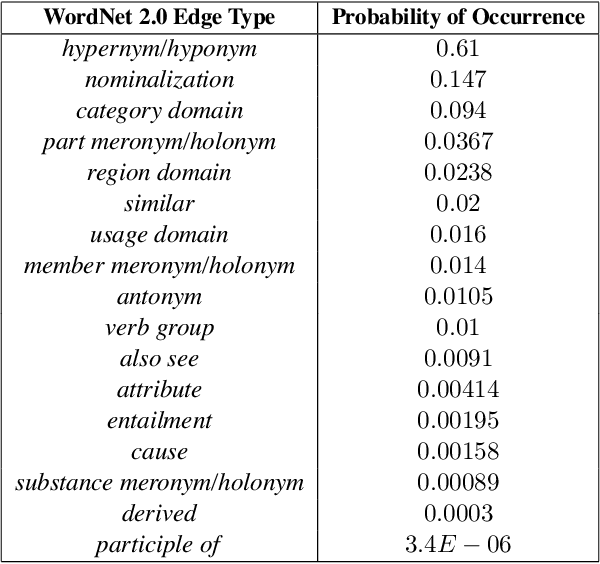


The computation of relatedness between two fragments of text in an automated manner requires taking into account a wide range of factors pertaining to the meaning the two fragments convey, and the pairwise relations between their words. Without doubt, a measure of relatedness between text segments must take into account both the lexical and the semantic relatedness between words. Such a measure that captures well both aspects of text relatedness may help in many tasks, such as text retrieval, classification and clustering. In this paper we present a new approach for measuring the semantic relatedness between words based on their implicit semantic links. The approach exploits only a word thesaurus in order to devise implicit semantic links between words. Based on this approach, we introduce Omiotis, a new measure of semantic relatedness between texts which capitalizes on the word-to-word semantic relatedness measure (SR) and extends it to measure the relatedness between texts. We gradually validate our method: we first evaluate the performance of the semantic relatedness measure between individual words, covering word-to-word similarity and relatedness, synonym identification and word analogy; then, we proceed with evaluating the performance of our method in measuring text-to-text semantic relatedness in two tasks, namely sentence-to-sentence similarity and paraphrase recognition. Experimental evaluation shows that the proposed method outperforms every lexicon-based method of semantic relatedness in the selected tasks and the used data sets, and competes well against corpus-based and hybrid approaches.
Quality Classifiers for Open Source Software Repositories
Apr 29, 2009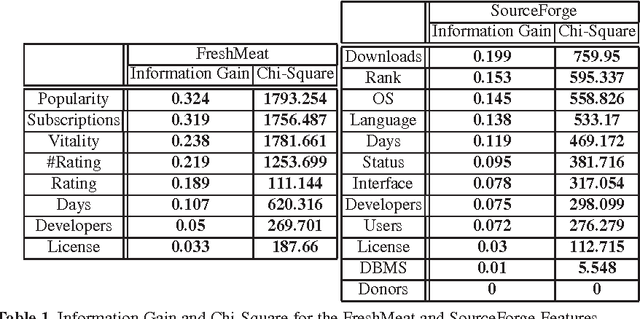
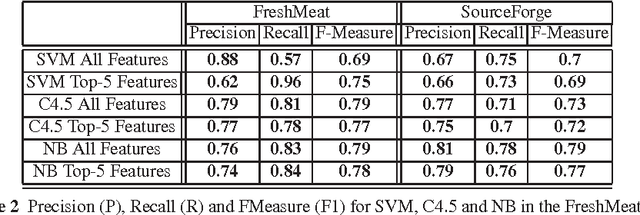
Open Source Software (OSS) often relies on large repositories, like SourceForge, for initial incubation. The OSS repositories offer a large variety of meta-data providing interesting information about projects and their success. In this paper we propose a data mining approach for training classifiers on the OSS meta-data provided by such data repositories. The classifiers learn to predict the successful continuation of an OSS project. The `successfulness' of projects is defined in terms of the classifier confidence with which it predicts that they could be ported in popular OSS projects (such as FreeBSD, Gentoo Portage).
* 10 pages, 2 Tables, 7 equations, 13 references. Appeared in 2nd Artificial Intelligence Techniques in Software Engineering Workshop, AIAI 2009