 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil is in the Details: On Models and Training Regimes for Few-Shot Intent Classification
Oct 12, 2022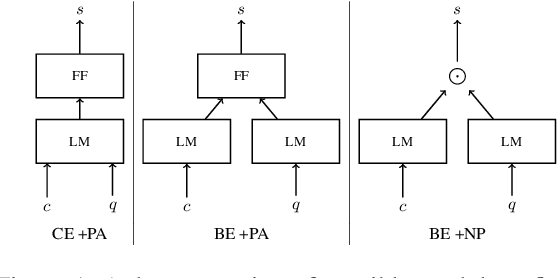
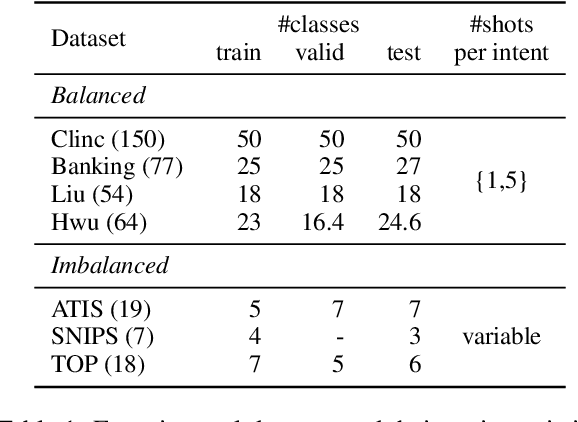
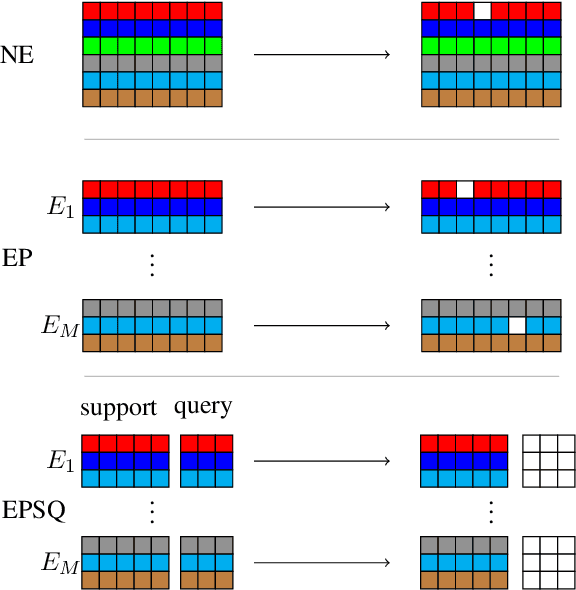
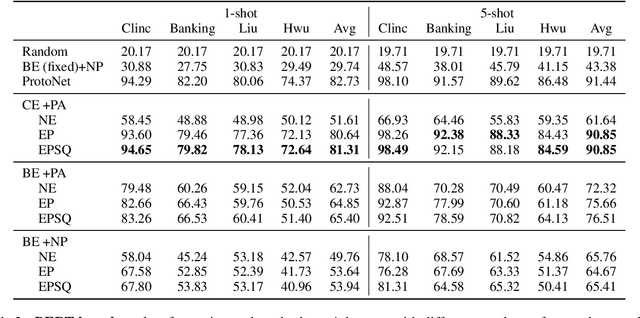
Few-shot Intent Classification (FSIC) is one of the key challenges in modular task-oriented dialog systems. While advanced FSIC methods are similar in using pretrained language models to encode texts and nearest neighbour-based inference for classification, these methods differ in details. They start from different pretrained text encoders, use different encoding architectures with varying similarity functions, and adopt different training regimes. Coupling these mostly independent design decisions and the lack of accompanying ablation studies are big obstacle to identify the factors that drive the reported FSIC performance. We study these details across three key dimensions: (1) Encoding architectures: Cross-Encoder vs Bi-Encoders; (2) Similarity function: Parameterized (i.e., trainable) functions vs non-parameterized function; (3) Training regimes: Episodic meta-learning vs the straightforward (i.e., non-episodic) training. Our experimental results on seven FSIC benchmarks reveal three important findings. First, the unexplored combination of the cross-encoder architecture (with parameterized similarity scoring function) and episodic meta-learning consistently yields the best FSIC performance. Second, Episodic training yields a more robust FSIC classifier than non-episodic one. Third, in meta-learning methods, splitting an episode to support and query sets is not a must. Our findings paves the way for conducting state-of-the-art research in FSIC and more importantly raise the community's attention to details of FSIC methods. We release our code and data publicly.
BenchIE: Open Information Extraction Evaluation Based on Facts, Not Tokens
Sep 14, 2021

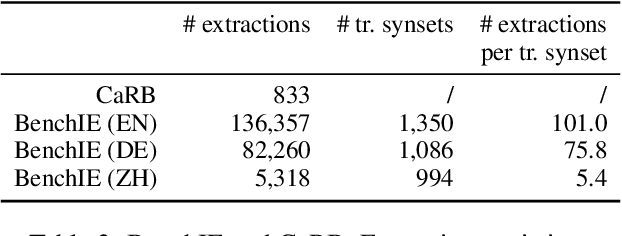
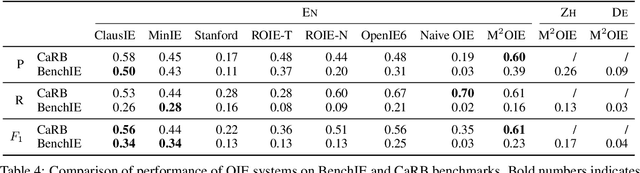
Intrinsic evaluations of OIE systems are carried out either manually -- with human evaluators judging the correctness of extractions -- or automatically, on standardized benchmarks. The latter, while much more cost-effective, is less reliable, primarily because of the incompleteness of the existing OIE benchmarks: the ground truth extractions do not include all acceptable variants of the same fact, leading to unreliable assessment of models' performance. Moreover, the existing OIE benchmarks are available for English only. In this work, we introduce BenchIE: a benchmark and evaluation framework for comprehensive evaluation of OIE systems for English, Chinese and German. In contrast to existing OIE benchmarks, BenchIE takes into account informational equivalence of extractions: our gold standard consists of fact synsets, clusters in which we exhaustively list all surface forms of the same fact. We benchmark several state-of-the-art OIE systems using BenchIE and demonstrate that these systems are significantly less effective than indicated by existing OIE benchmarks. We make BenchIE (data and evaluation code) publicly available.
Political Text Scaling Meets Computational Semantics
May 08, 2019
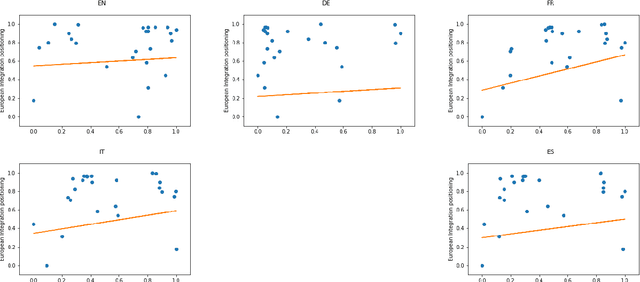
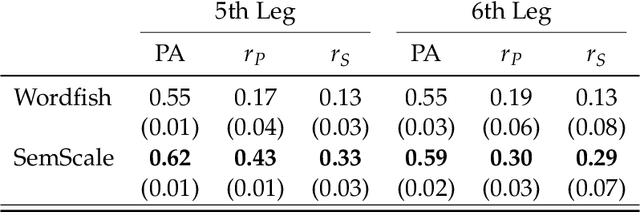
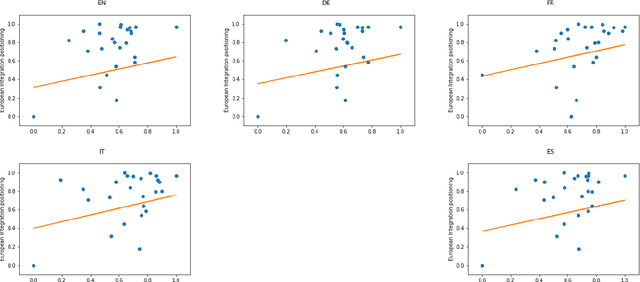
During the last fifteen years, text scaling approaches have become a central element for the text-as-data community. However, they are based on the assumption that latent positions can be captured just by modeling word-frequency information from the different documents under study. We challenge this by presenting a new semantically aware unsupervised scaling algorithm, SemScale, which relies upon distributional representations of the documents under study. We conduct an extensive quantitative analysis over a collection of speeches from the European Parliament in five different languages and from two different legislations, in order to understand whether a) an approach that is aware of semantics would better capture known underlying political dimensions compared to a frequency-based scaling method, b) such positioning correlates in particular with a specific subset of linguistic traits, compared to the use of the entire text, and c) these findings hold across different languages. To support further research on this new branch of text scaling approaches, we release the employed dataset and evaluation setting, an easy-to-use online demo, and a Python implementation of SemScale.
How to Evaluate Cross-Lingual Word Embeddings: On Strong Baselines, Comparative Analyses, and Some Misconceptions
Feb 01, 2019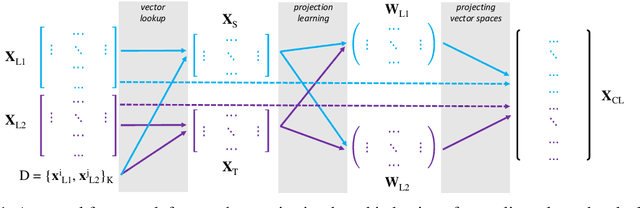
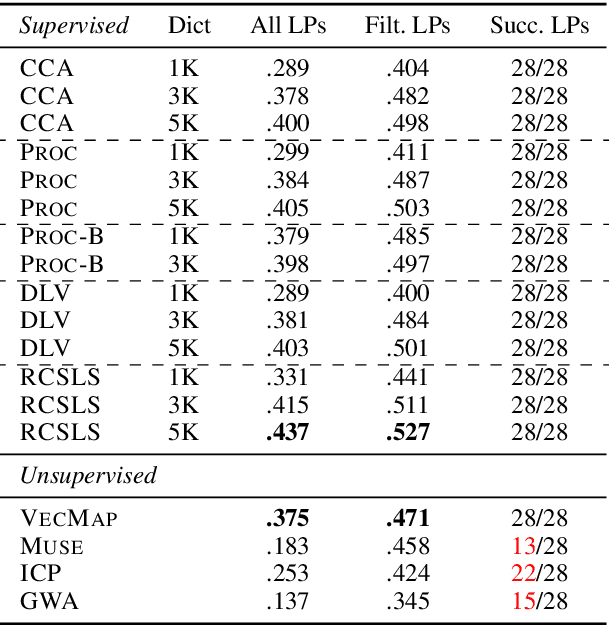
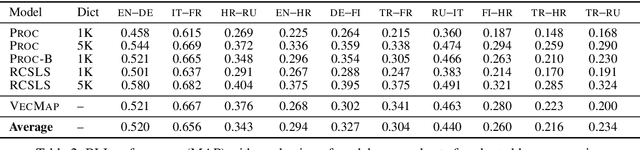
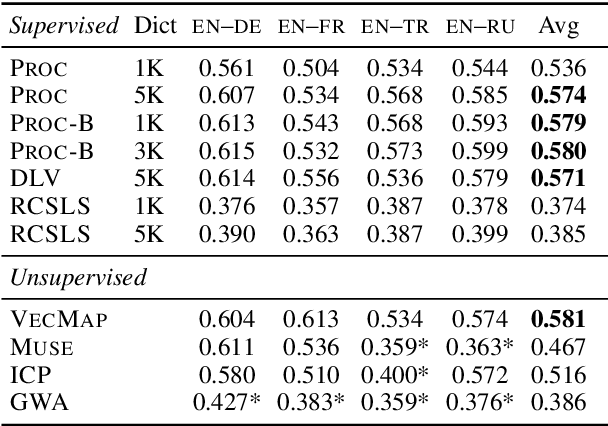
Cross-lingual word embeddings (CLEs) enable multilingual modeling of meaning and facilitate cross-lingual transfer of NLP models. Despite their ubiquitous usage in downstream tasks, recent increasingly popular projection-based CLE models are almost exclusively evaluated on a single task only: bilingual lexicon induction (BLI). Even BLI evaluations vary greatly, hindering our ability to correctly interpret performance and properties of different CLE models. In this work, we make the first step towards a comprehensive evaluation of cross-lingual word embeddings. We thoroughly evaluate both supervised and unsupervised CLE models on a large number of language pairs in the BLI task and three downstream tasks, providing new insights concerning the ability of cutting-edge CLE models to support cross-lingual NLP. We empirically demonstrate that the performance of CLE models largely depends on the task at hand and that optimizing CLE models for BLI can result in deteriorated downstream performance. We indicate the most robust supervised and unsupervised CLE models and emphasize the need to reassess existing baselines, which still display competitive performance across the board. We hope that our work will catalyze further work on CLE evaluation and model analysis.