 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Evaluate Cross-Lingual Word Embeddings: On Strong Baselines, Comparative Analyses, and Some Misconceptions
Paper and Code
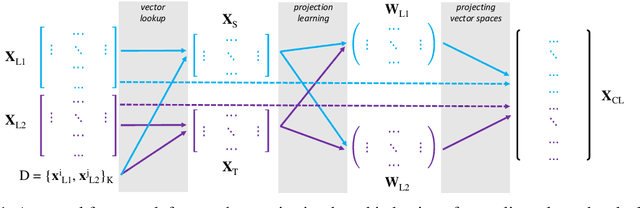
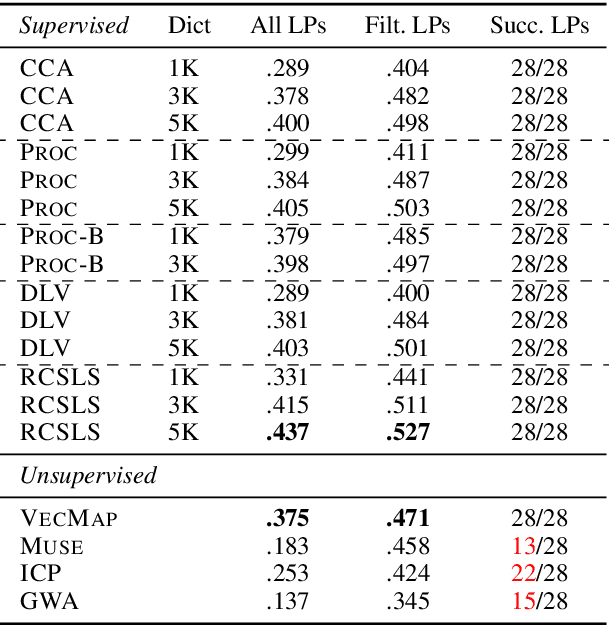
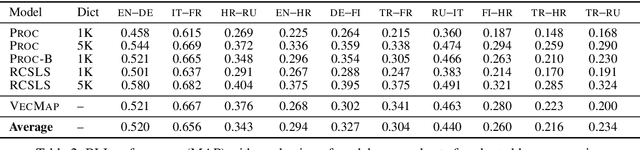
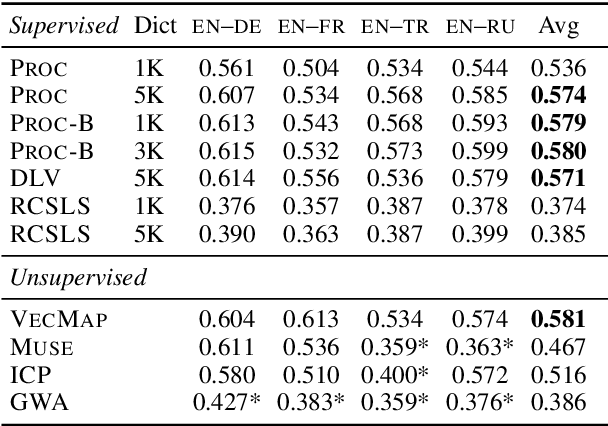
Cross-lingual word embeddings (CLEs) enable multilingual modeling of meaning and facilitate cross-lingual transfer of NLP models. Despite their ubiquitous usage in downstream tasks, recent increasingly popular projection-based CLE models are almost exclusively evaluated on a single task only: bilingual lexicon induction (BLI). Even BLI evaluations vary greatly, hindering our ability to correctly interpret performance and properties of different CLE models. In this work, we make the first step towards a comprehensive evaluation of cross-lingual word embeddings. We thoroughly evaluate both supervised and unsupervised CLE models on a large number of language pairs in the BLI task and three downstream tasks, providing new insights concerning the ability of cutting-edge CLE models to support cross-lingual NLP. We empirically demonstrate that the performance of CLE models largely depends on the task at hand and that optimizing CLE models for BLI can result in deteriorated downstream performance. We indicate the most robust supervised and unsupervised CLE models and emphasize the need to reassess existing baselines, which still display competitive performance across the board. We hope that our work will catalyze further work on CLE evaluation and model analysis.