 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDonors and Recipients: On Asymmetric Transfer Across Tasks and Languages with Parameter-Efficient Fine-Tuning
Nov 17, 2025
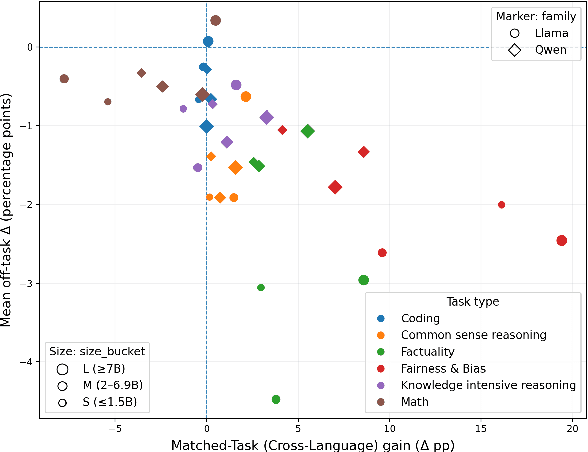
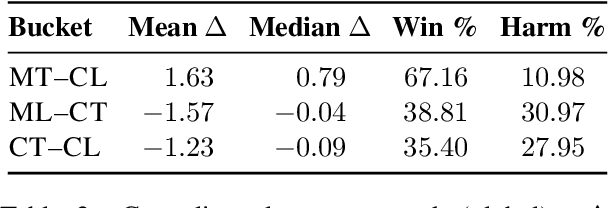
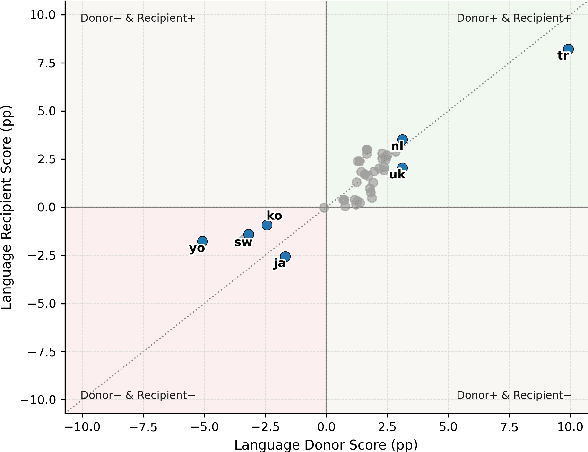
Large language models (LLMs) perform strongly across tasks and languages, yet how improvements in one task or language affect other tasks and languages and their combinations remains poorly understood. We conduct a controlled PEFT/LoRA study across multiple open-weight LLM families and sizes, treating task and language as transfer axes while conditioning on model family and size; we fine-tune each model on a single task-language source and measure transfer as the percentage-point change versus its baseline score when evaluated on all other task-language target pairs. We decompose transfer into (i) Matched-Task (Cross-Language), (ii) Matched-Language (Cross-Task), and (iii) Cross-Task (Cross-Language) regimes. We uncover two consistent general patterns. First, a pronounced on-task vs. off-task asymmetry: Matched-Task (Cross-Language) transfer is reliably positive, whereas off-task transfer often incurs collateral degradation. Second, a stable donor-recipient structure across languages and tasks (hub donors vs. brittle recipients). We outline implications for risk-aware fine-tuning and model specialisation.
Delving Deeper into Cross-lingual Visual Question Answering
Feb 15, 2022



Visual question answering (VQA) is one of the crucial vision-and-language tasks. Yet, the bulk of research until recently has focused only on the English language due to the lack of appropriate evaluation resources. Previous work on cross-lingual VQA has reported poor zero-shot transfer performance of current multilingual multimodal Transformers and large gaps to monolingual performance, attributed mostly to misalignment of text embeddings between the source and target languages, without providing any additional deeper analyses. In this work, we delve deeper and address different aspects of cross-lingual VQA holistically, aiming to understand the impact of input data, fine-tuning and evaluation regimes, and interactions between the two modalities in cross-lingual setups. 1) We tackle low transfer performance via novel methods that substantially reduce the gap to monolingual English performance, yielding +10 accuracy points over existing transfer methods. 2) We study and dissect cross-lingual VQA across different question types of varying complexity, across different multilingual multi-modal Transformers, and in zero-shot and few-shot scenarios. 3) We further conduct extensive analyses on modality biases in training data and models, aimed to further understand why zero-shot performance gaps remain for some question types and languages. We hope that the novel methods and detailed analyses will guide further progress in multilingual VQA.
How to Evaluate Cross-Lingual Word Embeddings: On Strong Baselines, Comparative Analyses, and Some Misconceptions
Feb 01, 2019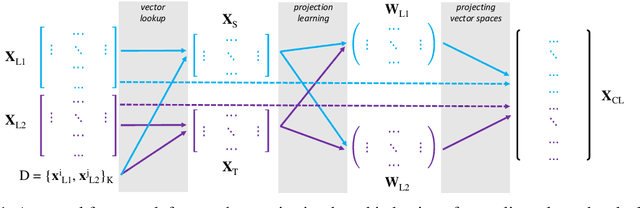
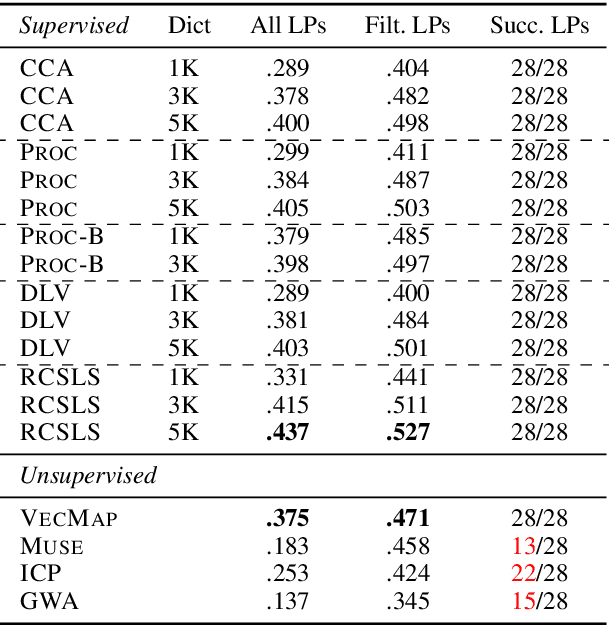
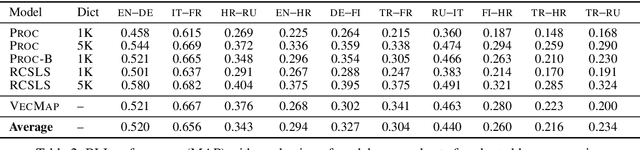
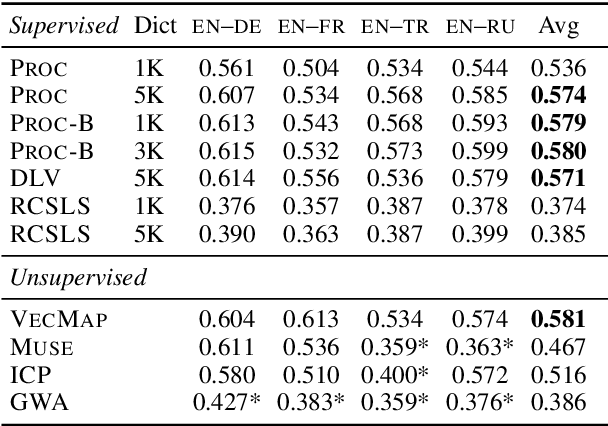
Cross-lingual word embeddings (CLEs) enable multilingual modeling of meaning and facilitate cross-lingual transfer of NLP models. Despite their ubiquitous usage in downstream tasks, recent increasingly popular projection-based CLE models are almost exclusively evaluated on a single task only: bilingual lexicon induction (BLI). Even BLI evaluations vary greatly, hindering our ability to correctly interpret performance and properties of different CLE models. In this work, we make the first step towards a comprehensive evaluation of cross-lingual word embeddings. We thoroughly evaluate both supervised and unsupervised CLE models on a large number of language pairs in the BLI task and three downstream tasks, providing new insights concerning the ability of cutting-edge CLE models to support cross-lingual NLP. We empirically demonstrate that the performance of CLE models largely depends on the task at hand and that optimizing CLE models for BLI can result in deteriorated downstream performance. We indicate the most robust supervised and unsupervised CLE models and emphasize the need to reassess existing baselines, which still display competitive performance across the board. We hope that our work will catalyze further work on CLE evaluation and model analysis.