 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchIE: Open Information Extraction Evaluation Based on Facts, Not Tokens
Paper and Code


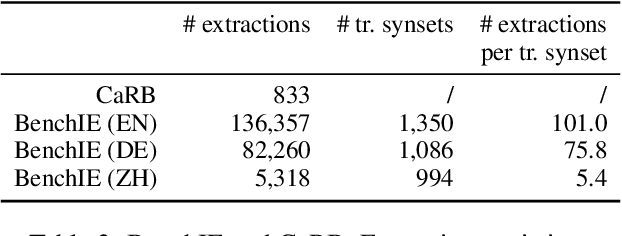
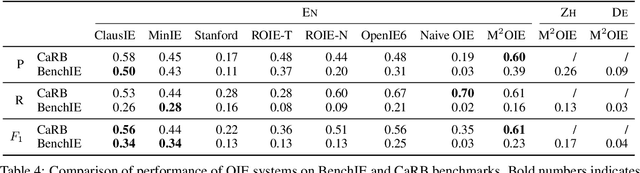
Intrinsic evaluations of OIE systems are carried out either manually -- with human evaluators judging the correctness of extractions -- or automatically, on standardized benchmarks. The latter, while much more cost-effective, is less reliable, primarily because of the incompleteness of the existing OIE benchmarks: the ground truth extractions do not include all acceptable variants of the same fact, leading to unreliable assessment of models' performance. Moreover, the existing OIE benchmarks are available for English only. In this work, we introduce BenchIE: a benchmark and evaluation framework for comprehensive evaluation of OIE systems for English, Chinese and German. In contrast to existing OIE benchmarks, BenchIE takes into account informational equivalence of extractions: our gold standard consists of fact synsets, clusters in which we exhaustively list all surface forms of the same fact. We benchmark several state-of-the-art OIE systems using BenchIE and demonstrate that these systems are significantly less effective than indicated by existing OIE benchmarks. We make BenchIE (data and evaluation code) publicly available.