 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Embedding Guided Negative Sample Generation for Knowledge Graph Link Prediction
Apr 04, 2025Knowledge graph embedding (KGE) models encode the structural information of knowledge graphs to predicting new links. Effective training of these models requires distinguishing between positive and negative samples with high precision. Although prior research has shown that improving the quality of negative samples can significantly enhance model accuracy, identifying high-quality negative samples remains a challenging problem. This paper theoretically investigates the condition under which negative samples lead to optimal KG embedding and identifies a sufficient condition for an effective negative sample distribution. Based on this theoretical foundation, we propose \textbf{E}mbedding \textbf{MU}tation (\textsc{EMU}), a novel framework that \emph{generates} negative samples satisfying this condition, in contrast to conventional methods that focus on \emph{identifying} challenging negative samples within the training data. Importantly, the simplicity of \textsc{EMU} ensures seamless integration with existing KGE models and negative sampling methods. To evaluate its efficacy, we conducted comprehensive experiments across multiple datasets. The results consistently demonstrate significant improvements in link prediction performance across various KGE models and negative sampling methods. Notably, \textsc{EMU} enables performance improvements comparable to those achieved by models with embedding dimension five times larger. An implementation of the method and experiments are available at https://github.com/nec-research/EMU-KG.
What Makes a Good Paraphrase: Do Automated Evaluations Work?
Jul 27, 2023
Paraphrasing is the task of expressing an essential idea or meaning in different words. But how different should the words be in order to be considered an acceptable paraphrase? And can we exclusively use automated metrics to evaluate the quality of a paraphrase? We attempt to answer these questions by conducting experiments on a German data set and performing automatic and expert linguistic evaluation.
Human-Centric Research for NLP: Towards a Definition and Guiding Questions
Jul 10, 2022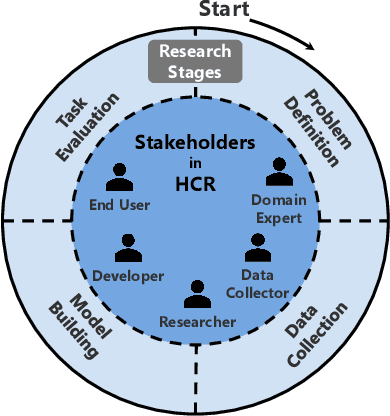

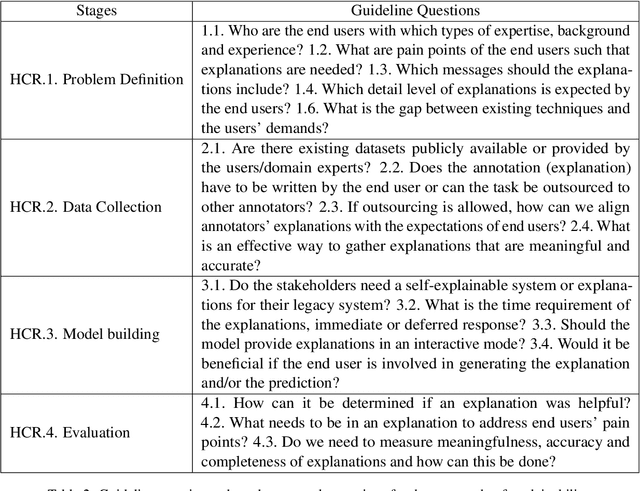
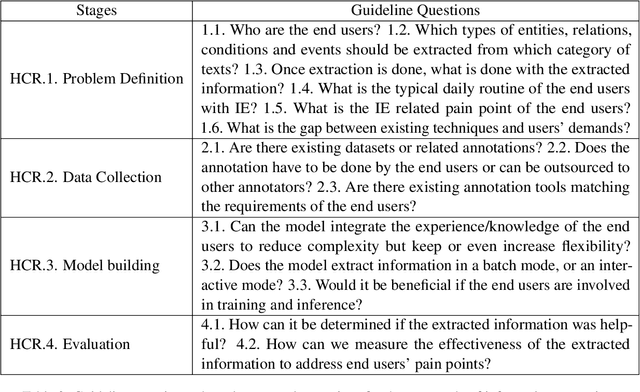
With Human-Centric Research (HCR) we can steer research activities so that the research outcome is beneficial for human stakeholders, such as end users. But what exactly makes research human-centric? We address this question by providing a working definition and define how a research pipeline can be split into different stages in which human-centric components can be added. Additionally, we discuss existing NLP with HCR components and define a series of guiding questions, which can serve as starting points for researchers interested in exploring human-centric research approaches. We hope that this work would inspire researchers to refine the proposed definition and to pose other questions that might be meaningful for achieving HCR.
A Human-Centric Assessment Framework for AI
May 25, 2022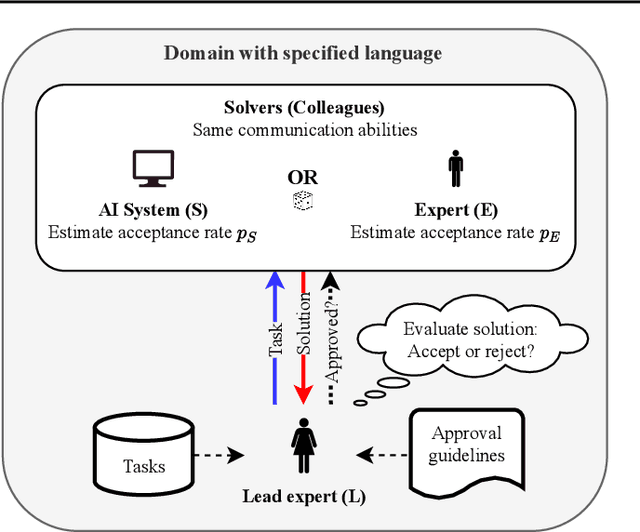
With the rise of AI systems in real-world applications comes the need for reliable and trustworthy AI. An important aspect for this are explainable AI systems. However, there is no agreed standard on how explainable AI systems should be assessed. Inspired by the Turing test, we introduce a human-centric assessment framework where a leading domain expert accepts or rejects the solutions of an AI system and another domain expert. By comparing the acceptance rates of provided solutions, we can assess how the AI system performs in comparison to the domain expert, and in turn whether or not the AI system's explanations (if provided) are human understandable. This setup -- comparable to the Turing test -- can serve as framework for a wide range of human-centric AI system assessments. We demonstrate this by presenting two instantiations: (1) an assessment that measures the classification accuracy of a system with the option to incorporate label uncertainties; (2) an assessment where the usefulness of provided explanations is determined in a human-centric manner.
Integrating diverse extraction pathways using iterative predictions for Multilingual Open Information Extraction
Oct 15, 2021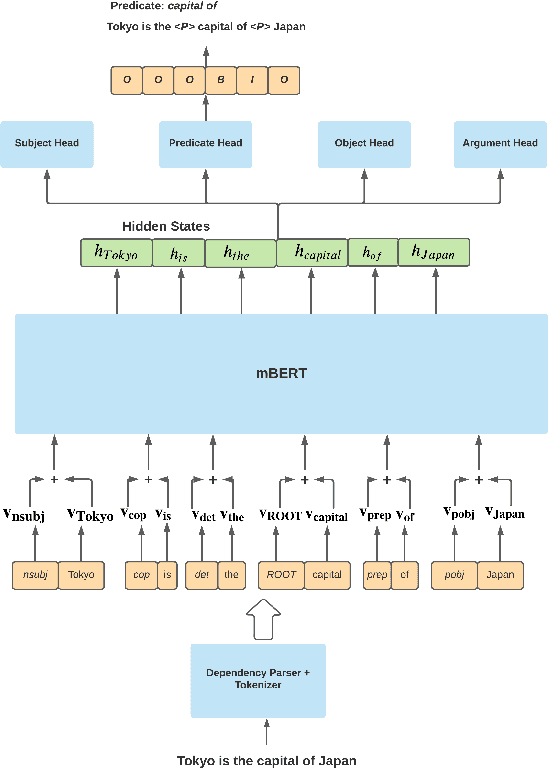

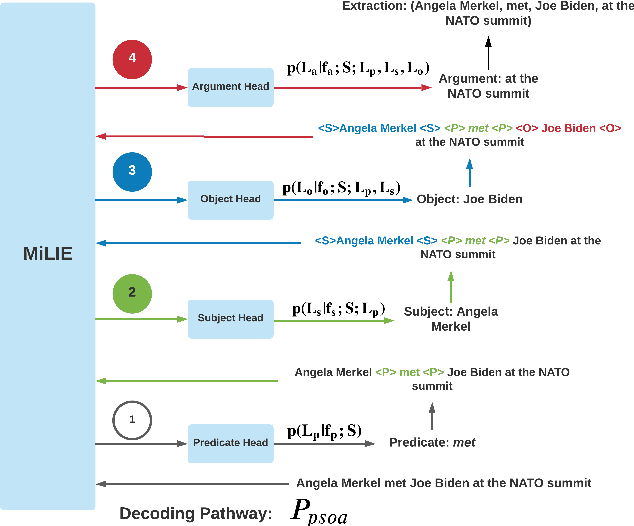

In this paper we investigate a simple hypothesis for the Open Information Extraction (OpenIE) task, that it may be easier to extract some elements of an triple if the extraction is conditioned on prior extractions which may be easier to extract. We successfully exploit this and propose a neural multilingual OpenIE system that iteratively extracts triples by conditioning extractions on different elements of the triple leading to a rich set of extractions. The iterative nature of MiLIE also allows for seamlessly integrating rule based extraction systems with a neural end-to-end system leading to improved performance. MiLIE outperforms SOTA systems on multiple languages ranging from Chinese to Galician thanks to it's ability of combining multiple extraction pathways. Our analysis confirms that it is indeed true that certain elements of an extraction are easier to extract than others. Finally, we introduce OpenIE evaluation datasets for two low resource languages namely Japanese and Galician.
AnnIE: An Annotation Platform for Constructing Complete Open Information Extraction Benchmark
Sep 15, 2021
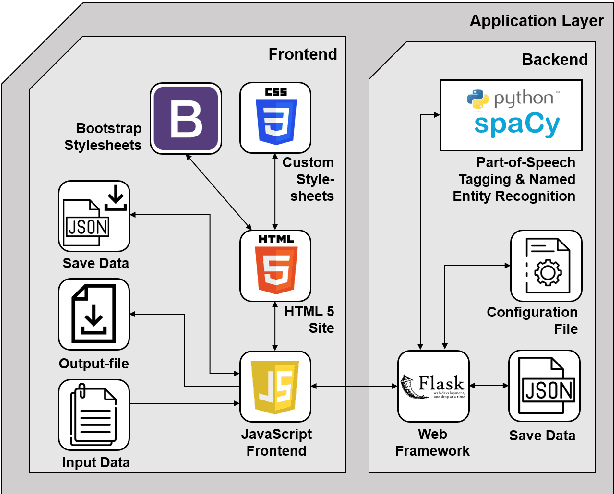

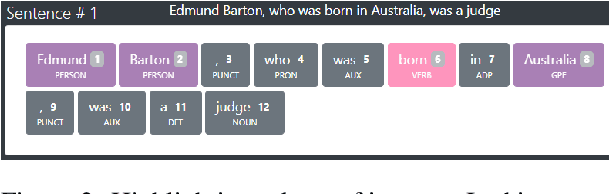
Open Information Extraction (OIE) is the task of extracting facts from sentences in the form of relations and their corresponding arguments in schema-free manner. Intrinsic performance of OIE systems is difficult to measure due to the incompleteness of existing OIE benchmarks: the ground truth extractions do not group all acceptable surface realizations of the same fact that can be extracted from a sentence. To measure performance of OIE systems more realistically, it is necessary to manually annotate complete facts (i.e., clusters of all acceptable surface realizations of the same fact) from input sentences. We propose AnnIE: an interactive annotation platform that facilitates such challenging annotation tasks and supports creation of complete fact-oriented OIE evaluation benchmarks. AnnIE is modular and flexible in order to support different use case scenarios (i.e., benchmarks covering different types of facts). We use AnnIE to build two complete OIE benchmarks: one with verb-mediated facts and another with facts encompassing named entities. Finally, we evaluate several OIE systems on our complete benchmarks created with AnnIE. Our results suggest that existing incomplete benchmarks are overly lenient, and that OIE systems are not as robust as previously reported. We publicly release AnnIE under non-restrictive license.
BenchIE: Open Information Extraction Evaluation Based on Facts, Not Tokens
Sep 14, 2021

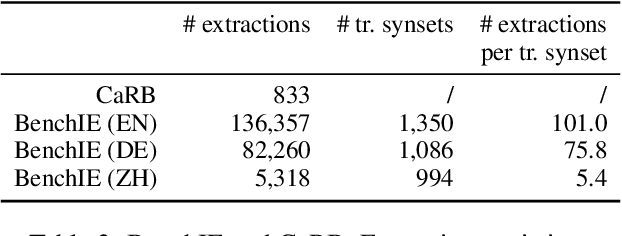
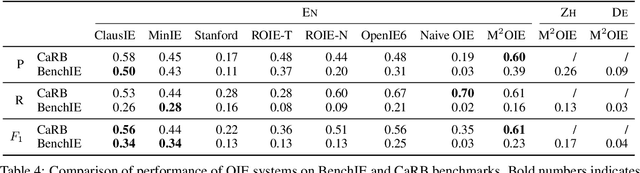
Intrinsic evaluations of OIE systems are carried out either manually -- with human evaluators judging the correctness of extractions -- or automatically, on standardized benchmarks. The latter, while much more cost-effective, is less reliable, primarily because of the incompleteness of the existing OIE benchmarks: the ground truth extractions do not include all acceptable variants of the same fact, leading to unreliable assessment of models' performance. Moreover, the existing OIE benchmarks are available for English only. In this work, we introduce BenchIE: a benchmark and evaluation framework for comprehensive evaluation of OIE systems for English, Chinese and German. In contrast to existing OIE benchmarks, BenchIE takes into account informational equivalence of extractions: our gold standard consists of fact synsets, clusters in which we exhaustively list all surface forms of the same fact. We benchmark several state-of-the-art OIE systems using BenchIE and demonstrate that these systems are significantly less effective than indicated by existing OIE benchmarks. We make BenchIE (data and evaluation code) publicly available.
Answering Complex Queries in Knowledge Graphs with Bidirectional Sequence Encoders
Apr 06, 2020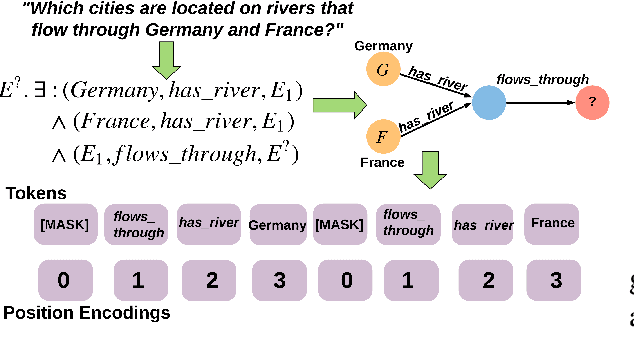
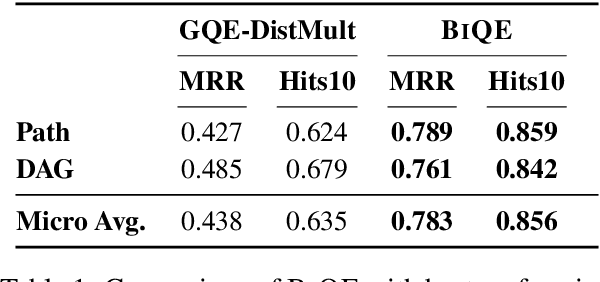
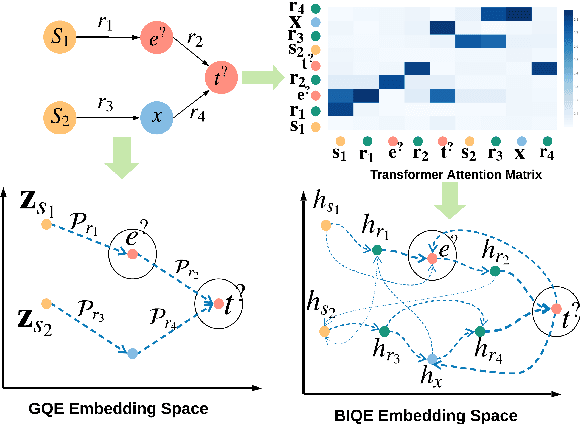

Representation learning for knowledge graphs (KGs) has focused on the problem of answering simple link prediction queries. In this work we address the more ambitious challenge of predicting the answers of conjunctive queries with multiple missing entities. We propose Bi-Directional Query Embedding (\textsc{BiQE}), a method that embeds conjunctive queries with models based on bi-directional attention mechanisms. Contrary to prior work, bidirectional self-attention can capture interactions among all the elements of a query graph. We introduce a new dataset for predicting the answer of conjunctive query and conduct experiments that show \textsc{BiQE} significantly outperforming state of the art baselines.
Attending to Future Tokens For Bidirectional Sequence Generation
Sep 17, 2019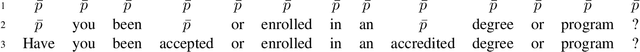
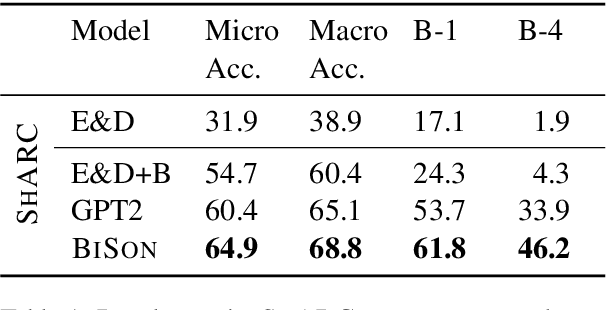
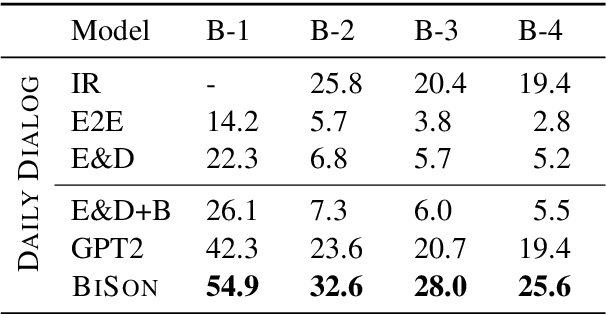
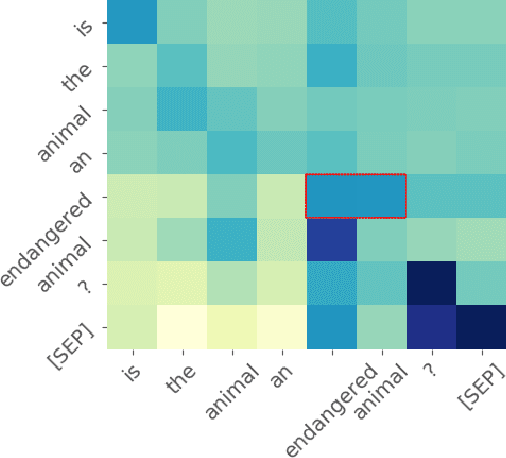
Neural sequence generation is typically performed token-by-token and left-to-right. Whenever a token is generated only previously produced tokens are taken into consideration. In contrast, for problems such as sequence classification, bidirectional attention, which takes both past and future tokens into consideration, has been shown to perform much better. We propose to make the sequence generation process bidirectional by employing special placeholder tokens. Treated as a node in a fully connected graph, a placeholder token can take past and future tokens into consideration when generating the actual output token. We verify the effectiveness of our approach experimentally on two conversational tasks where the proposed bidirectional model outperforms competitive baselines by a large margin.
Learning Knowledge Graph Embeddings with Type Regularizer
Mar 02, 2018
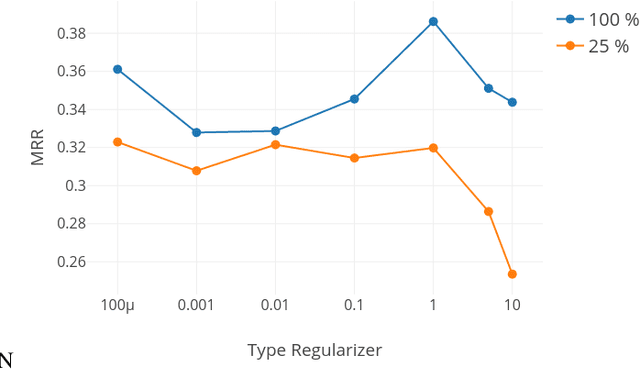
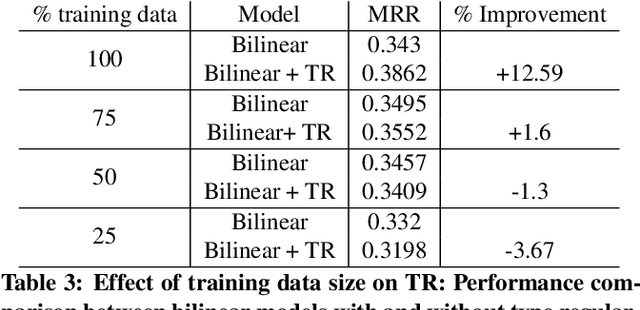
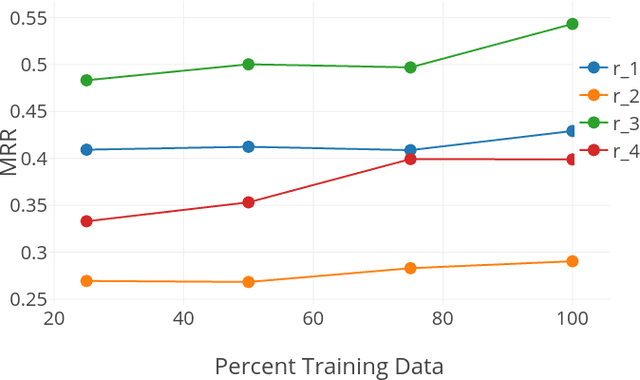
Learning relations based on evidence from knowledge bases relies on processing the available relation instances. Many relations, however, have clear domain and range, which we hypothesize could help learn a better, more generalizing, model. We include such information in the RESCAL model in the form of a regularization factor added to the loss function that takes into account the types (categories) of the entities that appear as arguments to relations in the knowledge base. We note increased performance compared to the baseline model in terms of mean reciprocal rank and hits@N, N = 1, 3, 10. Furthermore, we discover scenarios that significantly impact the effectiveness of the type regularizer.