 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Embedding Guided Negative Sample Generation for Knowledge Graph Link Prediction
Apr 04, 2025Knowledge graph embedding (KGE) models encode the structural information of knowledge graphs to predicting new links. Effective training of these models requires distinguishing between positive and negative samples with high precision. Although prior research has shown that improving the quality of negative samples can significantly enhance model accuracy, identifying high-quality negative samples remains a challenging problem. This paper theoretically investigates the condition under which negative samples lead to optimal KG embedding and identifies a sufficient condition for an effective negative sample distribution. Based on this theoretical foundation, we propose \textbf{E}mbedding \textbf{MU}tation (\textsc{EMU}), a novel framework that \emph{generates} negative samples satisfying this condition, in contrast to conventional methods that focus on \emph{identifying} challenging negative samples within the training data. Importantly, the simplicity of \textsc{EMU} ensures seamless integration with existing KGE models and negative sampling methods. To evaluate its efficacy, we conducted comprehensive experiments across multiple datasets. The results consistently demonstrate significant improvements in link prediction performance across various KGE models and negative sampling methods. Notably, \textsc{EMU} enables performance improvements comparable to those achieved by models with embedding dimension five times larger. An implementation of the method and experiments are available at https://github.com/nec-research/EMU-KG.
A Relational-learning Perspective to Multi-label Chest X-ray Classification
Mar 10, 2021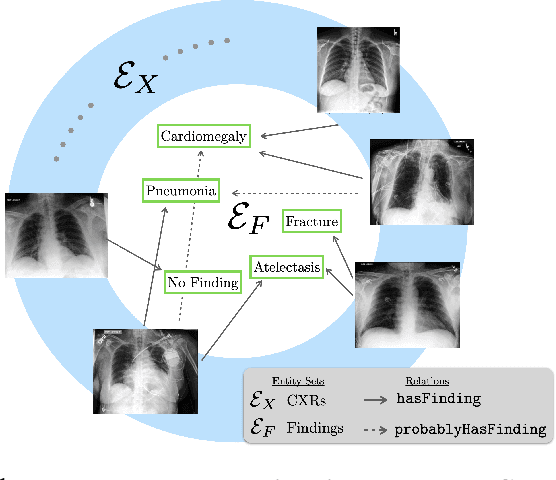
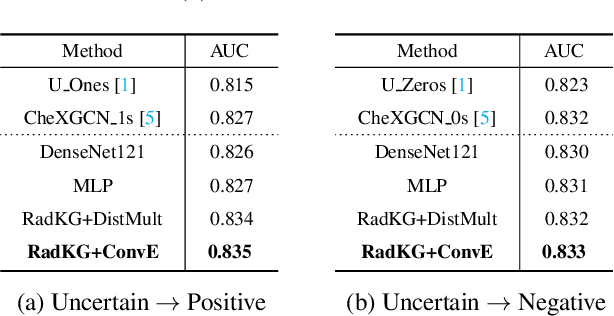
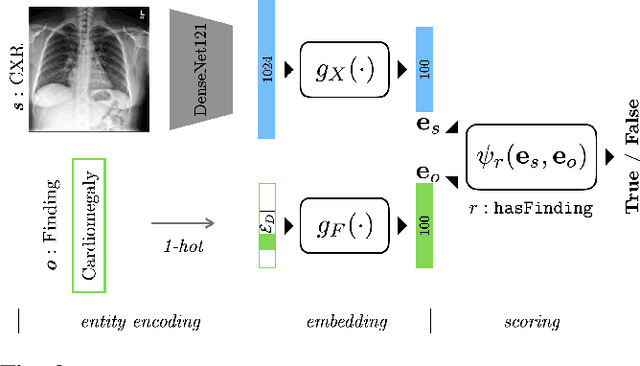
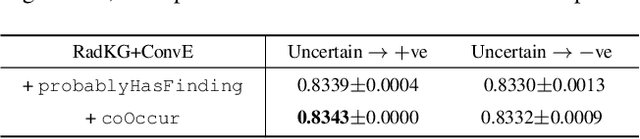
Multi-label classification of chest X-ray images is frequently performed using discriminative approaches, i.e. learning to map an image directly to its binary labels. Such approaches make it challenging to incorporate auxiliary information such as annotation uncertainty or a dependency among the labels. Building towards this, we propose a novel knowledge graph reformulation of multi-label classification, which not only readily increases predictive performance of an encoder but also serves as a general framework for introducing new domain knowledge. Specifically, we construct a multi-modal knowledge graph out of the chest X-ray images and its labels and pose multi-label classification as a link prediction problem. Incorporating auxiliary information can then simply be achieved by adding additional nodes and relations among them. When tested on a publicly-available radiograph dataset (CheXpert), our relational-reformulation using a naive knowledge graph outperforms the state-of-art by achieving an area-under-ROC curve of 83.5%, an improvement of "sim 1" over a purely discriminative approach.
Contextual Hourglass Networks for Segmentation and Density Estimation
Jun 08, 2018



Hourglass networks such as the U-Net and V-Net are popular neural architectures for medical image segmentation and counting problems. Typical instances of hourglass networks contain shortcut connections between mirroring layers. These shortcut connections improve the performance and it is hypothesized that this is due to mitigating effects on the vanishing gradient problem and the ability of the model to combine feature maps from earlier and later layers. We propose a method for not only combining feature maps of mirroring layers but also feature maps of layers with different spatial dimensions. For instance, the method enables the integration of the bottleneck feature map with those of the reconstruction layers. The proposed approach is applicable to any hourglass architecture. We evaluated the contextual hourglass networks on image segmentation and object counting problems in the medical domain. We achieve competitive results outperforming popular hourglass networks by up to 17 percentage points.
Learning Short-Cut Connections for Object Counting
May 08, 2018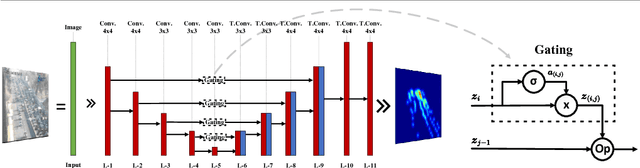


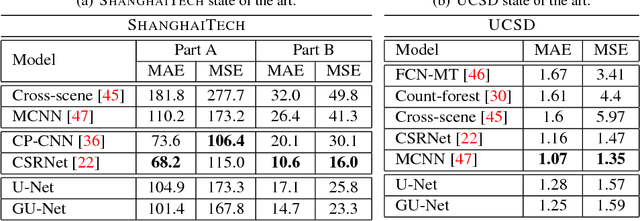
Object counting is an important task in computer vision due to its growing demand in applications such as traffic monitoring or surveillance. In this paper, we consider object counting as a learning problem of a joint feature extraction and pixel-wise object density estimation with Convolutional-Deconvolutional networks. We propose a novel counting model, named Gated U-Net (GU-Net). Specifically, we propose to enrich the U-Net architecture with the concept of learnable short-cut connections. Standard short-cut connections are connections between layers in deep neural networks which skip at least one intermediate layer. Instead of simply setting short-cut connections, we propose to learn these connections from data. Therefore, our short-cut can work as a gating unit, which optimizes the flow of information between convolutional and deconvolutional layers in the U-Net architecture. We evaluate the proposed GU-Net architecture on three commonly used benchmark data sets for object counting. GU-Nets consistently outperform the base U-Net architecture, and achieve state-of-the-art performance.
Representation Learning for Visual-Relational Knowledge Graphs
Mar 31, 2018

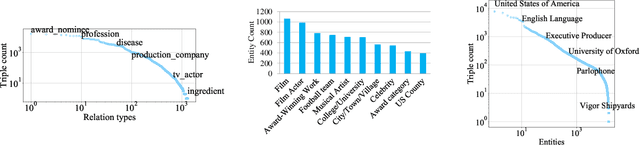

A visual-relational knowledge graph (KG) is a multi-relational graph whose entities are associated with images. We introduce ImageGraph, a KG with 1,330 relation types, 14,870 entities, and 829,931 images. Visual-relational KGs lead to novel probabilistic query types where images are treated as first-class citizens. Both the prediction of relations between unseen images and multi-relational image retrieval can be formulated as query types in a visual-relational KG. We approach the problem of answering such queries with a novel combination of deep convolutional networks and models for learning knowledge graph embeddings. The resulting models can answer queries such as "How are these two unseen images related to each other?" We also explore a zero-shot learning scenario where an image of an entirely new entity is linked with multiple relations to entities of an existing KG. The multi-relational grounding of unseen entity images into a knowledge graph serves as the description of such an entity. We conduct experiments to demonstrate that the proposed deep architectures in combination with KG embedding objectives can answer the visual-relational queries efficiently and accurately.
The challenge of simultaneous object detection and pose estimation: a comparative study
Jan 24, 2018

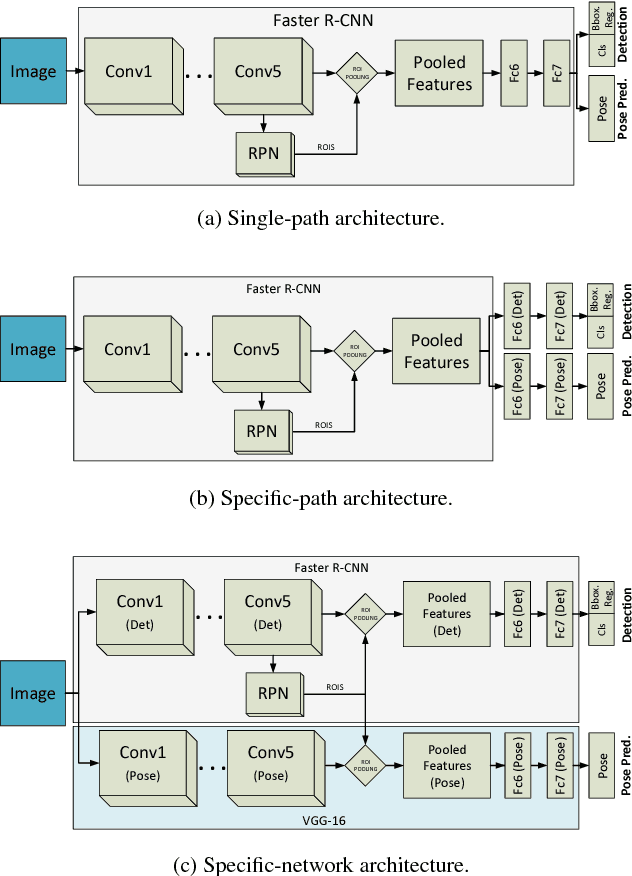

Detecting objects and estimating their pose remains as one of the major challenges of the computer vision research community. There exists a compromise between localizing the objects and estimating their viewpoints. The detector ideally needs to be view-invariant, while the pose estimation process should be able to generalize towards the category-level. This work is an exploration of using deep learning models for solving both problems simultaneously. For doing so, we propose three novel deep learning architectures, which are able to perform a joint detection and pose estimation, where we gradually decouple the two tasks. We also investigate whether the pose estimation problem should be solved as a classification or regression problem, being this still an open question in the computer vision community. We detail a comparative analysis of all our solutions and the methods that currently define the state of the art for this problem. We use PASCAL3D+ and ObjectNet3D datasets to present the thorough experimental evaluation and main results. With the proposed models we achieve the state-of-the-art performance in both datasets.