 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Video Captioning
Jun 20, 2024
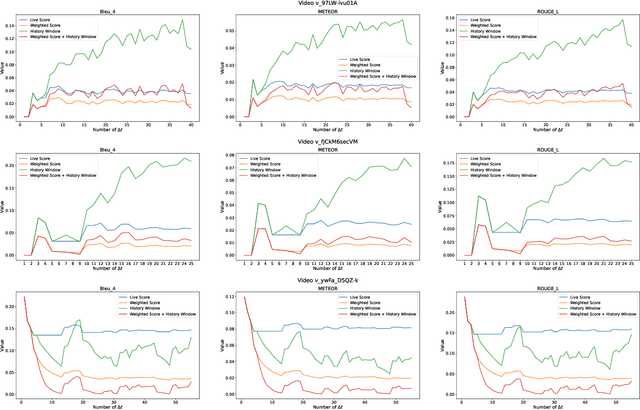
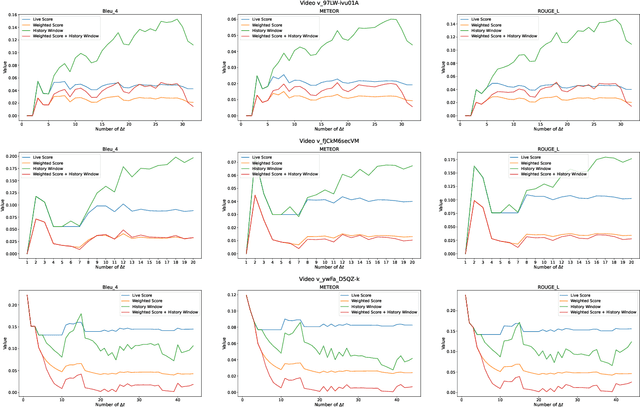

Dense video captioning is the task that involves the detection and description of events within video sequences. While traditional approaches focus on offline solutions where the entire video of analysis is available for the captioning model, in this work we introduce a paradigm shift towards Live Video Captioning (LVC). In LVC, dense video captioning models must generate captions for video streams in an online manner, facing important constraints such as having to work with partial observations of the video, the need for temporal anticipation and, of course, ensuring ideally a real-time response. In this work we formally introduce the novel problem of LVC and propose new evaluation metrics tailored for the online scenario, demonstrating their superiority over traditional metrics. We also propose an LVC model integrating deformable transformers and temporal filtering to address the LVC new challenges. Experimental evaluations on the ActivityNet Captions dataset validate the effectiveness of our approach, highlighting its performance in LVC compared to state-of-the-art offline methods. Results of our model as well as an evaluation kit with the novel metrics integrated are made publicly available to encourage further research on LVC.
Realistic Continual Learning Approach using Pre-trained Models
Apr 11, 2024
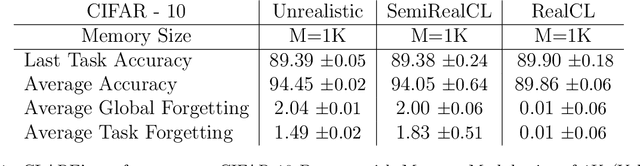


Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
Visual Semantic Navigation with Real Robots
Nov 28, 2023



Visual Semantic Navigation (VSN) is the ability of a robot to learn visual semantic information for navigating in unseen environments. These VSN models are typically tested in those virtual environments where they are trained, mainly using reinforcement learning based approaches. Therefore, we do not yet have an in-depth analysis of how these models would behave in the real world. In this work, we propose a new solution to integrate VSN models into real robots, so that we have true embodied agents. We also release a novel ROS-based framework for VSN, ROS4VSN, so that any VSN-model can be easily deployed in any ROS-compatible robot and tested in a real setting. Our experiments with two different robots, where we have embedded two state-of-the-art VSN agents, confirm that there is a noticeable performance difference of these VSN solutions when tested in real-world and simulation environments. We hope that this research will endeavor to provide a foundation for addressing this consequential issue, with the ultimate aim of advancing the performance and efficiency of embodied agents within authentic real-world scenarios. Code to reproduce all our experiments can be found at https://github.com/gramuah/ros4vsn.
Rethinking Online Action Detection in Untrimmed Videos: A Novel Online Evaluation Protocol
Mar 26, 2020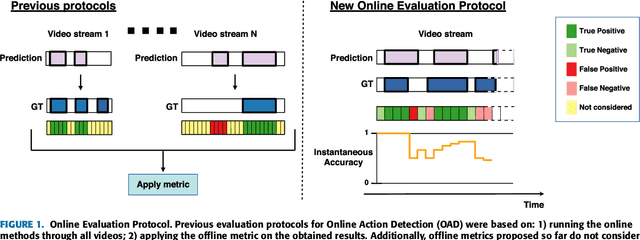
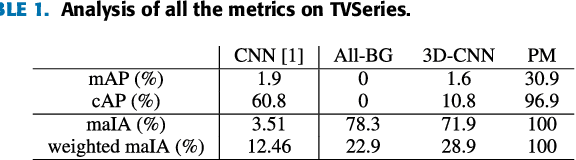
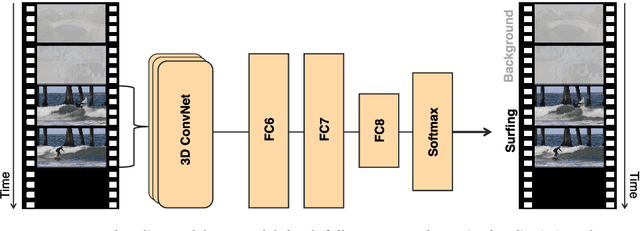
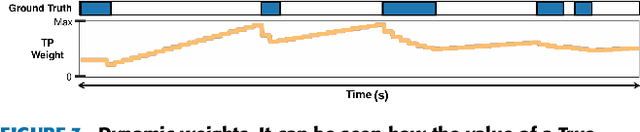
The Online Action Detection (OAD) problem needs to be revisited. Unlike traditional offline action detection approaches, where the evaluation metrics are clear and well established, in the OAD setting we find very few works and no consensus on the evaluation protocols to be used. In this work we propose to rethink the OAD scenario, clearly defining the problem itself and the main characteristics that the models which are considered online must comply with. We also introduce a novel metric: the Instantaneous Accuracy ($IA$). This new metric exhibits an \emph{online} nature and solves most of the limitations of the previous metrics. We conduct a thorough experimental evaluation on 3 challenging datasets, where the performance of various baseline methods is compared to that of the state-of-the-art. Our results confirm the problems of the previous evaluation protocols, and suggest that an IA-based protocol is more adequate to the online scenario. The baselines models and a development kit with the novel evaluation protocol are publicly available: https://github.com/gramuah/ia.
The Instantaneous Accuracy: a Novel Metric for the Problem of Online Human Behaviour Recognition in Untrimmed Videos
Mar 25, 2020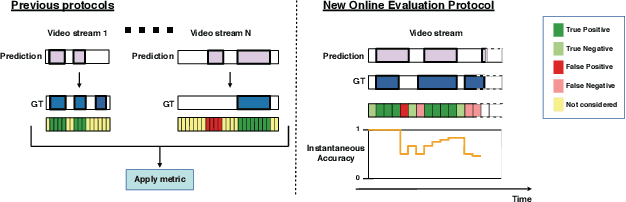
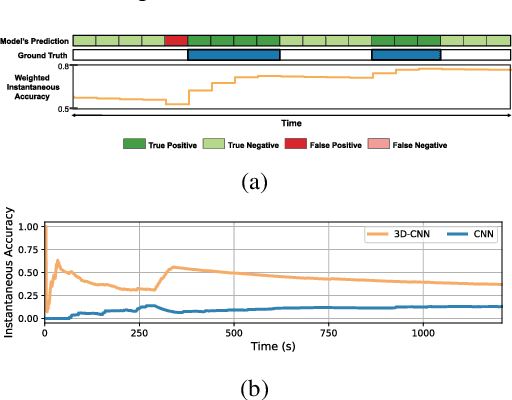
The problem of Online Human Behaviour Recognition in untrimmed videos, aka Online Action Detection (OAD), needs to be revisited. Unlike traditional offline action detection approaches, where the evaluation metrics are clear and well established, in the OAD setting we find few works and no consensus on the evaluation protocols to be used. In this paper we introduce a novel online metric, the Instantaneous Accuracy ($IA$), that exhibits an \emph{online} nature, solving most of the limitations of the previous (offline) metrics. We conduct a thorough experimental evaluation on TVSeries dataset, comparing the performance of various baseline methods to the state of the art. Our results confirm the problems of previous evaluation protocols, and suggest that an IA-based protocol is more adequate to the online scenario for human behaviour understanding. Code of the metric available https://github.com/gramuah/ia
Deep Anomaly Detection for Generalized Face Anti-Spoofing
Apr 17, 2019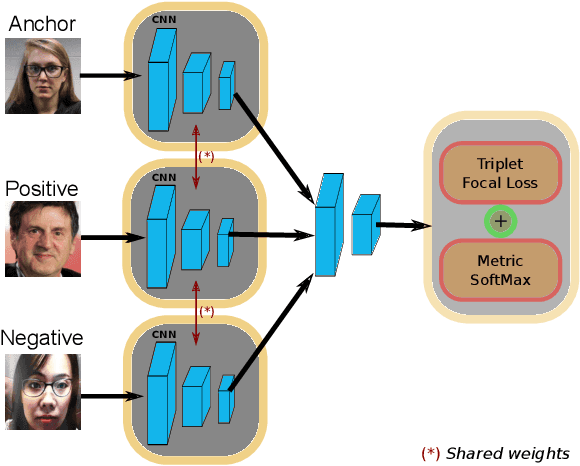
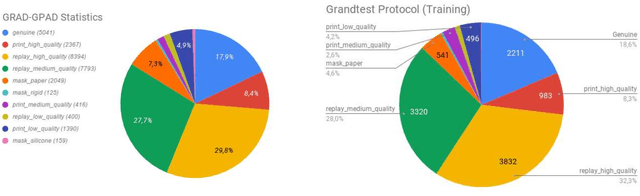
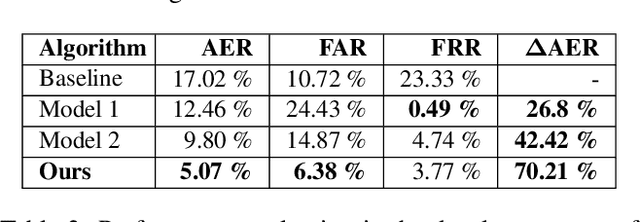
Face recognition has achieved unprecedented results, surpassing human capabilities in certain scenarios. However, these automatic solutions are not ready for production because they can be easily fooled by simple identity impersonation attacks. And although much effort has been devoted to develop face anti-spoofing models, their generalization capacity still remains a challenge in real scenarios. In this paper, we introduce a novel approach that reformulates the Generalized Presentation Attack Detection (GPAD) problem from an anomaly detection perspective. Technically, a deep metric learning model is proposed, where a triplet focal loss is used as a regularization for a novel loss coined "metric-softmax", which is in charge of guiding the learning process towards more discriminative feature representations in an embedding space. Finally, we demonstrate the benefits of our deep anomaly detection architecture, by introducing a few-shot a posteriori probability estimation that does not need any classifier to be trained on the learned features. We conduct extensive experiments using the GRAD-GPAD framework that provides the largest aggregated dataset for face GPAD. Results confirm that our approach is able to outperform all the state-of-the-art methods by a considerable margin.
Generalized Presentation Attack Detection: a face anti-spoofing evaluation proposal
Apr 12, 2019



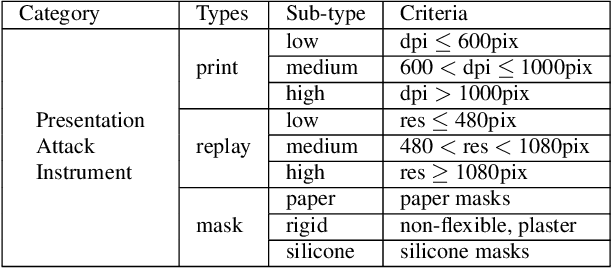
Over the past few years, Presentation Attack Detection (PAD) has become a fundamental part of facial recognition systems. Although much effort has been devoted to anti-spoofing research, generalization in real scenarios remains a challenge. In this paper we present a new open-source evaluation framework to study the generalization capacity of face PAD methods, coined here as face-GPAD. This framework facilitates the creation of new protocols focused on the generalization problem establishing fair procedures of evaluation and comparison between PAD solutions. We also introduce a large aggregated and categorized dataset to address the problem of incompatibility between publicly available datasets. Finally, we propose a benchmark adding two novel evaluation protocols: one for measuring the effect introduced by the variations in face resolution, and the second for evaluating the influence of adversarial operating conditions.
Embarrassingly Simple Model for Early Action Proposal
Oct 18, 2018


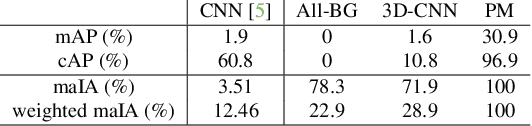
Early action proposal consists in generating high quality candidate temporal segments that are likely to contain an action in a video stream, as soon as they happen. Many sophisticated approaches have been proposed for the action proposal problem but from the off-line perspective. On the contrary, we focus on the on-line version of the problem, proposing a simple classifier-based model, using standard 3D CNNs, that performs significantly better than the state of the art.
ISA$^2$: Intelligent Speed Adaptation from Appearance
Oct 11, 2018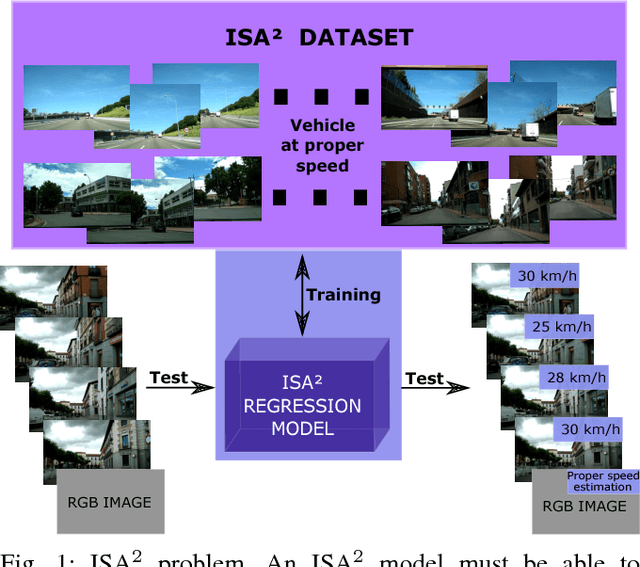



In this work we introduce a new problem named Intelligent Speed Adaptation from Appearance (ISA$^2$). Technically, the goal of an ISA$^2$ model is to predict for a given image of a driving scenario the proper speed of the vehicle. Note this problem is different from predicting the actual speed of the vehicle. It defines a novel regression problem where the appearance information has to be directly mapped to get a prediction for the speed at which the vehicle should go, taking into account the traffic situation. First, we release a novel dataset for the new problem, where multiple driving video sequences, with the annotated adequate speed per frame, are provided. We then introduce two deep learning based ISA$^2$ models, which are trained to perform the final regression of the proper speed given a test image. We end with a thorough experimental validation where the results show the level of difficulty of the proposed task. The dataset and the proposed models will all be made publicly available to encourage much needed further research on this problem.
Unsupervised learning from videos using temporal coherency deep networks
Oct 11, 2018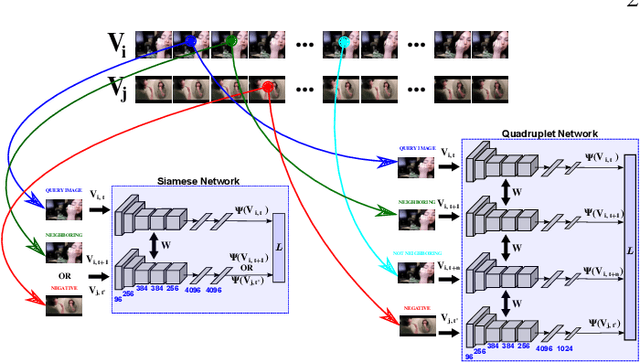

In this work we address the challenging problem of unsupervised learning from videos. Existing methods utilize the spatio-temporal continuity in contiguous video frames as regularization for the learning process. Typically, this temporal coherence of close frames is used as a free form of annotation, encouraging the learned representations to exhibit small differences between these frames. But this type of approach fails to capture the dissimilarity between videos with different content, hence learning less discriminative features. We here propose two Siamese architectures for Convolutional Neural Networks, and their corresponding novel loss functions, to learn from unlabeled videos, which jointly exploit the local temporal coherence between contiguous frames, and a global discriminative margin used to separate representations of different videos. An extensive experimental evaluation is presented, where we validate the proposed models on various tasks. First, we show how the learned features can be used to discover actions and scenes in video collections. Second, we show the benefits of such an unsupervised learning from just unlabeled videos, which can be directly used as a prior for the supervised recognition tasks of actions and objects in images, where our results further show that our features can even surpass a traditional and heavily supervised pre-training plus fine-tunning strategy.