 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Video Captioning
Jun 20, 2024
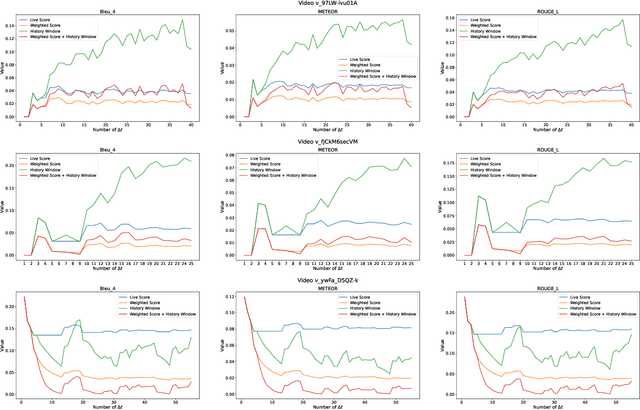
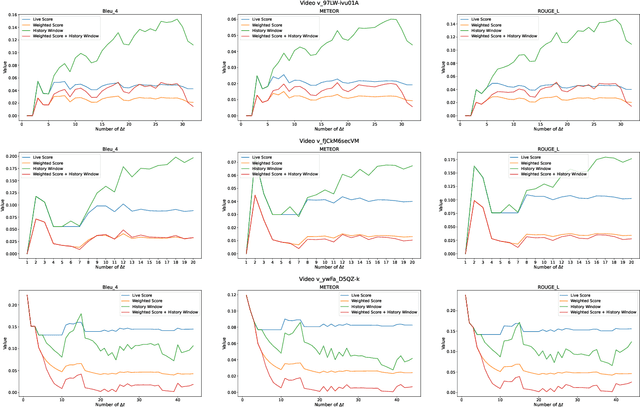

Dense video captioning is the task that involves the detection and description of events within video sequences. While traditional approaches focus on offline solutions where the entire video of analysis is available for the captioning model, in this work we introduce a paradigm shift towards Live Video Captioning (LVC). In LVC, dense video captioning models must generate captions for video streams in an online manner, facing important constraints such as having to work with partial observations of the video, the need for temporal anticipation and, of course, ensuring ideally a real-time response. In this work we formally introduce the novel problem of LVC and propose new evaluation metrics tailored for the online scenario, demonstrating their superiority over traditional metrics. We also propose an LVC model integrating deformable transformers and temporal filtering to address the LVC new challenges. Experimental evaluations on the ActivityNet Captions dataset validate the effectiveness of our approach, highlighting its performance in LVC compared to state-of-the-art offline methods. Results of our model as well as an evaluation kit with the novel metrics integrated are made publicly available to encourage further research on LVC.