 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Video Captioning
Jun 20, 2024
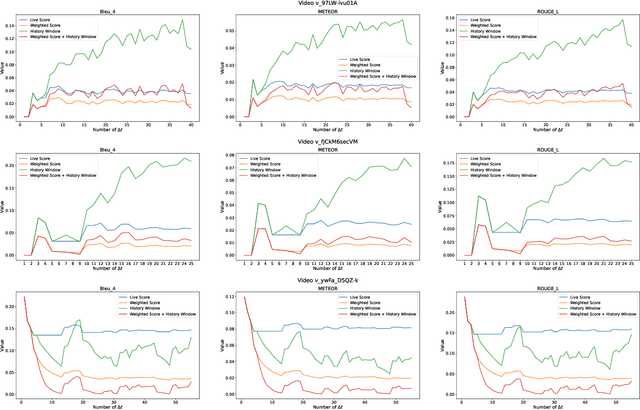
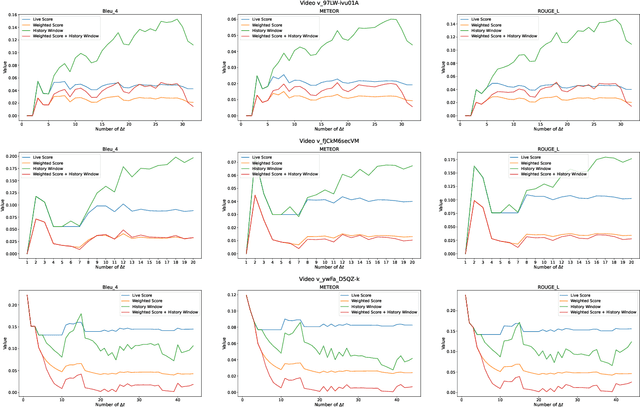

Dense video captioning is the task that involves the detection and description of events within video sequences. While traditional approaches focus on offline solutions where the entire video of analysis is available for the captioning model, in this work we introduce a paradigm shift towards Live Video Captioning (LVC). In LVC, dense video captioning models must generate captions for video streams in an online manner, facing important constraints such as having to work with partial observations of the video, the need for temporal anticipation and, of course, ensuring ideally a real-time response. In this work we formally introduce the novel problem of LVC and propose new evaluation metrics tailored for the online scenario, demonstrating their superiority over traditional metrics. We also propose an LVC model integrating deformable transformers and temporal filtering to address the LVC new challenges. Experimental evaluations on the ActivityNet Captions dataset validate the effectiveness of our approach, highlighting its performance in LVC compared to state-of-the-art offline methods. Results of our model as well as an evaluation kit with the novel metrics integrated are made publicly available to encourage further research on LVC.
Realistic Continual Learning Approach using Pre-trained Models
Apr 11, 2024
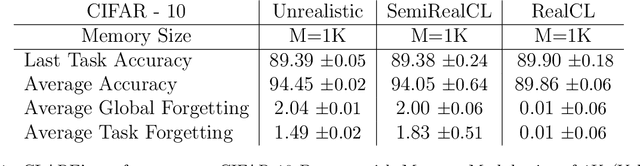


Continual learning (CL) is crucial for evaluating adaptability in learning solutions to retain knowledge. Our research addresses the challenge of catastrophic forgetting, where models lose proficiency in previously learned tasks as they acquire new ones. While numerous solutions have been proposed, existing experimental setups often rely on idealized class-incremental learning scenarios. We introduce Realistic Continual Learning (RealCL), a novel CL paradigm where class distributions across tasks are random, departing from structured setups. We also present CLARE (Continual Learning Approach with pRE-trained models for RealCL scenarios), a pre-trained model-based solution designed to integrate new knowledge while preserving past learning. Our contributions include pioneering RealCL as a generalization of traditional CL setups, proposing CLARE as an adaptable approach for RealCL tasks, and conducting extensive experiments demonstrating its effectiveness across various RealCL scenarios. Notably, CLARE outperforms existing models on RealCL benchmarks, highlighting its versatility and robustness in unpredictable learning environments.
Visual Semantic Navigation with Real Robots
Nov 28, 2023



Visual Semantic Navigation (VSN) is the ability of a robot to learn visual semantic information for navigating in unseen environments. These VSN models are typically tested in those virtual environments where they are trained, mainly using reinforcement learning based approaches. Therefore, we do not yet have an in-depth analysis of how these models would behave in the real world. In this work, we propose a new solution to integrate VSN models into real robots, so that we have true embodied agents. We also release a novel ROS-based framework for VSN, ROS4VSN, so that any VSN-model can be easily deployed in any ROS-compatible robot and tested in a real setting. Our experiments with two different robots, where we have embedded two state-of-the-art VSN agents, confirm that there is a noticeable performance difference of these VSN solutions when tested in real-world and simulation environments. We hope that this research will endeavor to provide a foundation for addressing this consequential issue, with the ultimate aim of advancing the performance and efficiency of embodied agents within authentic real-world scenarios. Code to reproduce all our experiments can be found at https://github.com/gramuah/ros4vsn.