 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-label classification of promotions in digital leaflets using textual and visual information
Oct 07, 2020

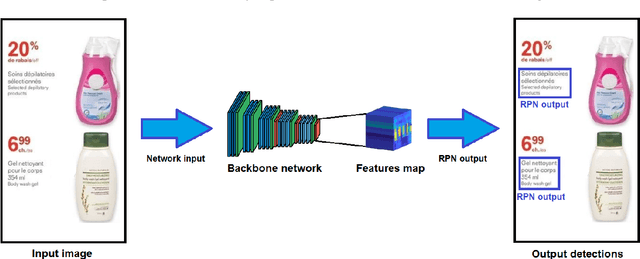

Product descriptions in e-commerce platforms contain detailed and valuable information about retailers assortment. In particular, coding promotions within digital leaflets are of great interest in e-commerce as they capture the attention of consumers by showing regular promotions for different products. However, this information is embedded into images, making it difficult to extract and process for downstream tasks. In this paper, we present an end-to-end approach that classifies promotions within digital leaflets into their corresponding product categories using both visual and textual information. Our approach can be divided into three key components: 1) region detection, 2) text recognition and 3) text classification. In many cases, a single promotion refers to multiple product categories, so we introduce a multi-label objective in the classification head. We demonstrate the effectiveness of our approach for two separated tasks: 1) image-based detection of the descriptions for each individual promotion and 2) multi-label classification of the product categories using the text from the product descriptions. We train and evaluate our models using a private dataset composed of images from digital leaflets obtained by Nielsen. Results show that we consistently outperform the proposed baseline by a large margin in all the experiments.
Deep Anomaly Detection for Generalized Face Anti-Spoofing
Apr 17, 2019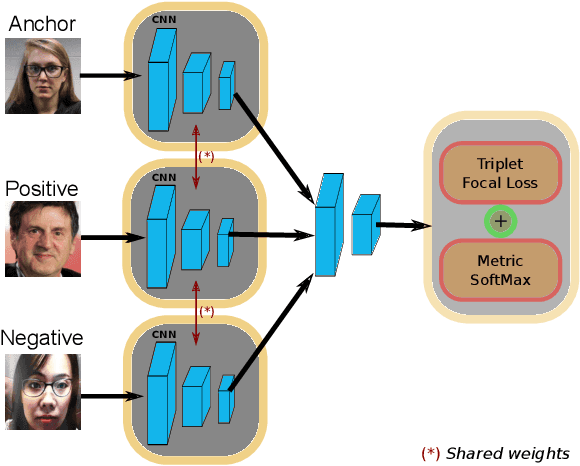
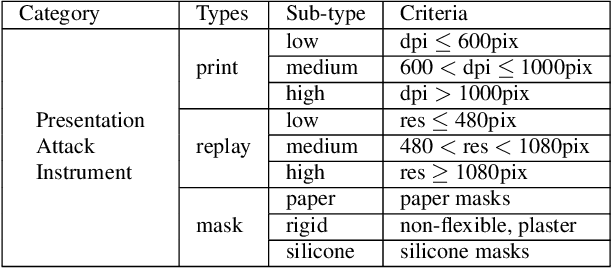
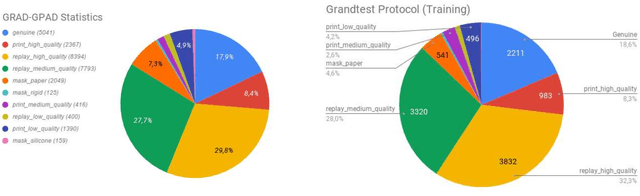
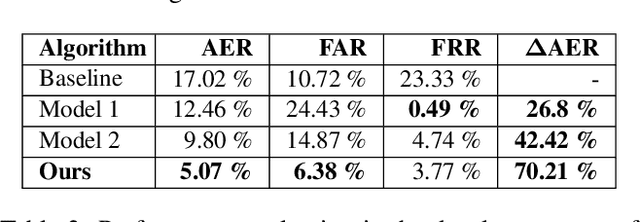
Face recognition has achieved unprecedented results, surpassing human capabilities in certain scenarios. However, these automatic solutions are not ready for production because they can be easily fooled by simple identity impersonation attacks. And although much effort has been devoted to develop face anti-spoofing models, their generalization capacity still remains a challenge in real scenarios. In this paper, we introduce a novel approach that reformulates the Generalized Presentation Attack Detection (GPAD) problem from an anomaly detection perspective. Technically, a deep metric learning model is proposed, where a triplet focal loss is used as a regularization for a novel loss coined "metric-softmax", which is in charge of guiding the learning process towards more discriminative feature representations in an embedding space. Finally, we demonstrate the benefits of our deep anomaly detection architecture, by introducing a few-shot a posteriori probability estimation that does not need any classifier to be trained on the learned features. We conduct extensive experiments using the GRAD-GPAD framework that provides the largest aggregated dataset for face GPAD. Results confirm that our approach is able to outperform all the state-of-the-art methods by a considerable margin.