 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKey Information Extraction in Purchase Documents using Deep Learning and Rule-based Corrections
Oct 07, 2022


Deep Learning (DL) is dominating the fields of Natural Language Processing (NLP) and Computer Vision (CV) in the recent times. However, DL commonly relies on the availability of large data annotations, so other alternative or complementary pattern-based techniques can help to improve results. In this paper, we build upon Key Information Extraction (KIE) in purchase documents using both DL and rule-based corrections. Our system initially trusts on Optical Character Recognition (OCR) and text understanding based on entity tagging to identify purchase facts of interest (e.g., product codes, descriptions, quantities, or prices). These facts are then linked to a same product group, which is recognized by means of line detection and some grouping heuristics. Once these DL approaches are processed, we contribute several mechanisms consisting of rule-based corrections for improving the baseline DL predictions. We prove the enhancements provided by these rule-based corrections over the baseline DL results in the presented experiments for purchase documents from public and NielsenIQ datasets.
Multi-label classification of promotions in digital leaflets using textual and visual information
Oct 07, 2020

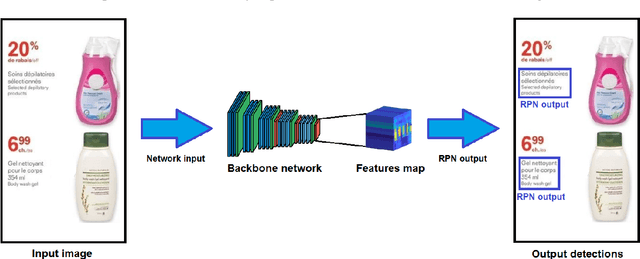

Product descriptions in e-commerce platforms contain detailed and valuable information about retailers assortment. In particular, coding promotions within digital leaflets are of great interest in e-commerce as they capture the attention of consumers by showing regular promotions for different products. However, this information is embedded into images, making it difficult to extract and process for downstream tasks. In this paper, we present an end-to-end approach that classifies promotions within digital leaflets into their corresponding product categories using both visual and textual information. Our approach can be divided into three key components: 1) region detection, 2) text recognition and 3) text classification. In many cases, a single promotion refers to multiple product categories, so we introduce a multi-label objective in the classification head. We demonstrate the effectiveness of our approach for two separated tasks: 1) image-based detection of the descriptions for each individual promotion and 2) multi-label classification of the product categories using the text from the product descriptions. We train and evaluate our models using a private dataset composed of images from digital leaflets obtained by Nielsen. Results show that we consistently outperform the proposed baseline by a large margin in all the experiments.
Integration of Text-maps in Convolutional Neural Networks for Region Detection among Different Textual Categories
May 26, 2019


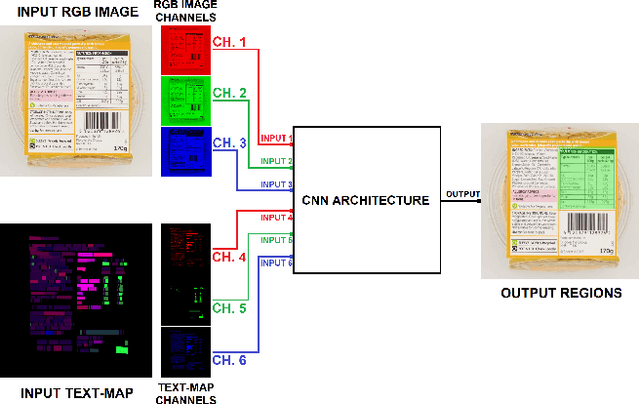
In this work, we propose a new technique that combines appearance and text in a Convolutional Neural Network (CNN), with the aim of detecting regions of different textual categories. We define a novel visual representation of the semantic meaning of text that allows a seamless integration in a standard CNN architecture. This representation, referred to as text-map, is integrated with the actual image to provide a much richer input to the network. Text-maps are colored with different intensities depending on the relevance of the words recognized over the image. Concretely, these words are previously extracted using Optical Character Recognition (OCR) and they are colored according to the probability of belonging to a textual category of interest. In this sense, this solution is especially relevant in the context of item coding for supermarket products, where different types of textual categories must be identified, such as ingredients or nutritional facts. We evaluated our solution in the proprietary item coding dataset of Nielsen Brandbank, which contains more than 10,000 images for train and 2,000 images for test. The reported results demonstrate that our approach focused on visual and textual data outperforms state-of-the-art algorithms only based on appearance, such as standard Faster R-CNN. These enhancements are reflected in precision and recall, which are improved in 42 and 33 points respectively.
Can we unify monocular detectors for autonomous driving by using the pixel-wise semantic segmentation of CNNs?
Jul 04, 2016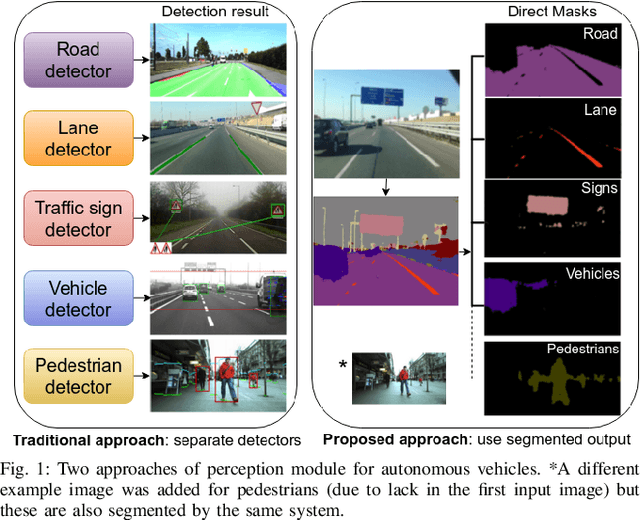


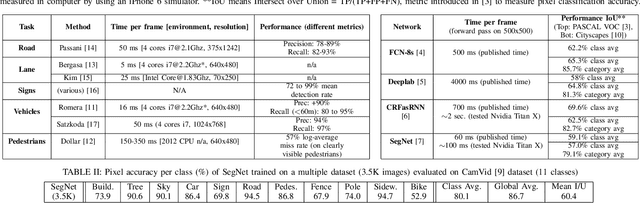
Autonomous driving is a challenging topic that requires complex solutions in perception tasks such as recognition of road, lanes, traffic signs or lights, vehicles and pedestrians. Through years of research, computer vision has grown capable of tackling these tasks with monocular detectors that can provide remarkable detection rates with relatively low processing times. However, the recent appearance of Convolutional Neural Networks (CNNs) has revolutionized the computer vision field and has made possible approaches to perform full pixel-wise semantic segmentation in times close to real time (even on hardware that can be carried on a vehicle). In this paper, we propose to use full image segmentation as an approach to simplify and unify most of the detection tasks required in the perception module of an autonomous vehicle, analyzing major concerns such as computation time and detection performance.