 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEVPredFormer: Spatio-temporal Attention for BEV Instance Prediction in Autonomous Driving
Apr 03, 2026A robust awareness of how dynamic scenes evolve is essential for Autonomous Driving systems, as they must accurately detect, track, and predict the behaviour of surrounding obstacles. Traditional perception pipelines that rely on modular architectures tend to suffer from cumulative errors and latency. Instance Prediction models provide a unified solution, performing Bird's-Eye-View segmentation and motion estimation across current and future frames using information directly obtained from different sensors. However, a key challenge in these models lies in the effective processing of the dense spatial and temporal information inherent in dynamic driving environments. This level of complexity demands architectures capable of capturing fine-grained motion patterns and long-range dependencies without compromising real-time performance. We introduce BEVPredFormer, a novel camera-only architecture for BEV instance prediction that uses attention-based temporal processing to improve temporal and spatial comprehension of the scene and relies on an attention-based 3D projection of the camera information. BEVPredFormer employs a recurrent-free design that incorporates gated transformer layers, divided spatio-temporal attention mechanisms, and multi-scale head tasks. Additionally, we incorporate a difference-guided feature extraction module that enhances temporal representations. Extensive ablation studies validate the effectiveness of each architectural component. When evaluated on the nuScenes dataset, BEVPredFormer was on par or surpassed State-Of-The-Art methods, highlighting its potential for robust and efficient Autonomous Driving perception.
GaussianCaR: Gaussian Splatting for Efficient Camera-Radar Fusion
Feb 09, 2026Robust and accurate perception of dynamic objects and map elements is crucial for autonomous vehicles performing safe navigation in complex traffic scenarios. While vision-only methods have become the de facto standard due to their technical advances, they can benefit from effective and cost-efficient fusion with radar measurements. In this work, we advance fusion methods by repurposing Gaussian Splatting as an efficient universal view transformer that bridges the view disparity gap, mapping both image pixels and radar points into a common Bird's-Eye View (BEV) representation. Our main contribution is GaussianCaR, an end-to-end network for BEV segmentation that, unlike prior BEV fusion methods, leverages Gaussian Splatting to map raw sensor information into latent features for efficient camera-radar fusion. Our architecture combines multi-scale fusion with a transformer decoder to efficiently extract BEV features. Experimental results demonstrate that our approach achieves performance on par with, or even surpassing, the state of the art on BEV segmentation tasks (57.3%, 82.9%, and 50.1% IoU for vehicles, roads, and lane dividers) on the nuScenes dataset, while maintaining a 3.2x faster inference runtime. Code and project page are available online.
Fast and Efficient Transformer-based Method for Bird's Eye View Instance Prediction
Nov 11, 2024Accurate object detection and prediction are critical to ensure the safety and efficiency of self-driving architectures. Predicting object trajectories and occupancy enables autonomous vehicles to anticipate movements and make decisions with future information, increasing their adaptability and reducing the risk of accidents. Current State-Of-The-Art (SOTA) approaches often isolate the detection, tracking, and prediction stages, which can lead to significant prediction errors due to accumulated inaccuracies between stages. Recent advances have improved the feature representation of multi-camera perception systems through Bird's-Eye View (BEV) transformations, boosting the development of end-to-end systems capable of predicting environmental elements directly from vehicle sensor data. These systems, however, often suffer from high processing times and number of parameters, creating challenges for real-world deployment. To address these issues, this paper introduces a novel BEV instance prediction architecture based on a simplified paradigm that relies only on instance segmentation and flow prediction. The proposed system prioritizes speed, aiming at reduced parameter counts and inference times compared to existing SOTA architectures, thanks to the incorporation of an efficient transformer-based architecture. Furthermore, the implementation of the proposed architecture is optimized for performance improvements in PyTorch version 2.1. Code and trained models are available at https://github.com/miguelag99/Efficient-Instance-Prediction
Efficient Baselines for Motion Prediction in Autonomous Driving
Sep 06, 2023Motion Prediction (MP) of multiple surroundings agents is a crucial task in arbitrarily complex environments, from simple robots to Autonomous Driving Stacks (ADS). Current techniques tackle this problem using end-to-end pipelines, where the input data is usually a rendered top-view of the physical information and the past trajectories of the most relevant agents; leveraging this information is a must to obtain optimal performance. In that sense, a reliable ADS must produce reasonable predictions on time. However, despite many approaches use simple ConvNets and LSTMs to obtain the social latent features, State-Of-The-Art (SOTA) models might be too complex for real-time applications when using both sources of information (map and past trajectories) as well as little interpretable, specially considering the physical information. Moreover, the performance of such models highly depends on the number of available inputs for each particular traffic scenario, which are expensive to obtain, particularly, annotated High-Definition (HD) maps. In this work, we propose several efficient baselines for the well-known Argoverse 1 Motion Forecasting Benchmark. We aim to develop compact models using SOTA techniques for MP, including attention mechanisms and GNNs. Our lightweight models use standard social information and interpretable map information such as points from the driveable area and plausible centerlines by means of a novel preprocessing step based on kinematic constraints, in opposition to black-box CNN-based or too-complex graphs methods for map encoding, to generate plausible multimodal trajectories achieving up-to-pair accuracy with less operations and parameters than other SOTA methods. Our code is publicly available at https://github.com/Cram3r95/mapfe4mp .
S$^3$-MonoDETR: Supervised Shape&Scale-perceptive Deformable Transformer for Monocular 3D Object Detection
Sep 02, 2023



Recently, transformer-based methods have shown exceptional performance in monocular 3D object detection, which can predict 3D attributes from a single 2D image. These methods typically use visual and depth representations to generate query points on objects, whose quality plays a decisive role in the detection accuracy. However, current unsupervised attention mechanisms without any geometry appearance awareness in transformers are susceptible to producing noisy features for query points, which severely limits the network performance and also makes the model have a poor ability to detect multi-category objects in a single training process. To tackle this problem, this paper proposes a novel "Supervised Shape&Scale-perceptive Deformable Attention" (S$^3$-DA) module for monocular 3D object detection. Concretely, S$^3$-DA utilizes visual and depth features to generate diverse local features with various shapes and scales and predict the corresponding matching distribution simultaneously to impose valuable shape&scale perception for each query. Benefiting from this, S$^3$-DA effectively estimates receptive fields for query points belonging to any category, enabling them to generate robust query features. Besides, we propose a Multi-classification-based Shape$\&$Scale Matching (MSM) loss to supervise the above process. Extensive experiments on KITTI and Waymo Open datasets demonstrate that S$^3$-DA significantly improves the detection accuracy, yielding state-of-the-art performance of single-category and multi-category 3D object detection in a single training process compared to the existing approaches. The source code will be made publicly available at https://github.com/mikasa3lili/S3-MonoDETR.
Exploring Attention GAN for Vehicle Motion Prediction
Sep 26, 2022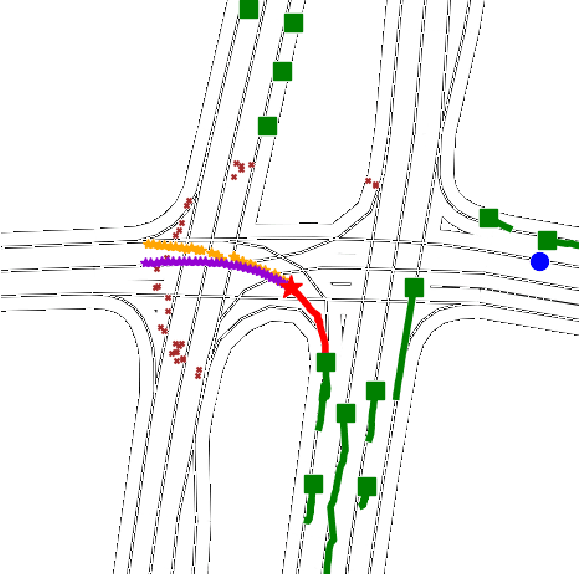
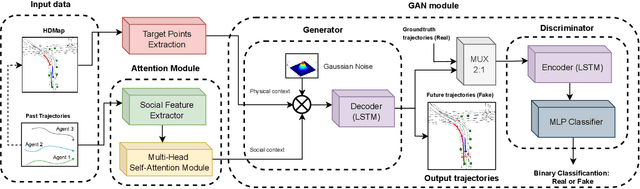
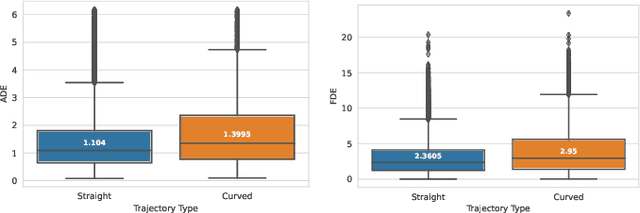
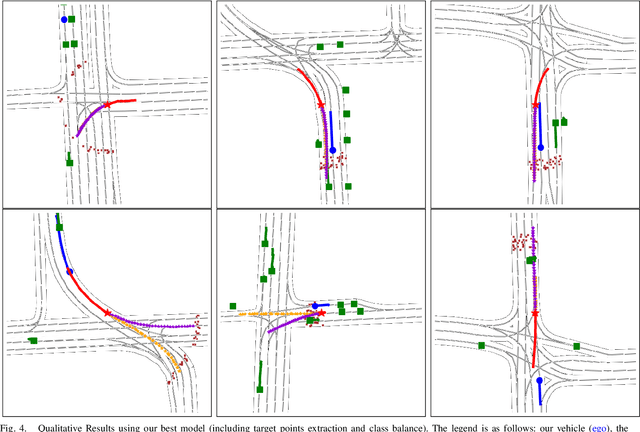
The design of a safe and reliable Autonomous Driving stack (ADS) is one of the most challenging tasks of our era. These ADS are expected to be driven in highly dynamic environments with full autonomy, and a reliability greater than human beings. In that sense, to efficiently and safely navigate through arbitrarily complex traffic scenarios, ADS must have the ability to forecast the future trajectories of surrounding actors. Current state-of-the-art models are typically based on Recurrent, Graph and Convolutional networks, achieving noticeable results in the context of vehicle prediction. In this paper we explore the influence of attention in generative models for motion prediction, considering both physical and social context to compute the most plausible trajectories. We first encode the past trajectories using a LSTM network, which serves as input to a Multi-Head Self-Attention module that computes the social context. On the other hand, we formulate a weighted interpolation to calculate the velocity and orientation in the last observation frame in order to calculate acceptable target points, extracted from the driveable of the HDMap information, which represents our physical context. Finally, the input of our generator is a white noise vector sampled from a multivariate normal distribution while the social and physical context are its conditions, in order to predict plausible trajectories. We validate our method using the Argoverse Motion Forecasting Benchmark 1.1, achieving competitive unimodal results.
Can we unify monocular detectors for autonomous driving by using the pixel-wise semantic segmentation of CNNs?
Jul 04, 2016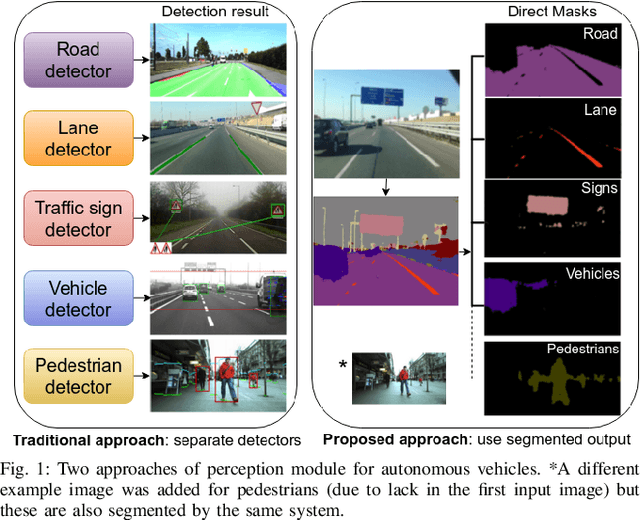


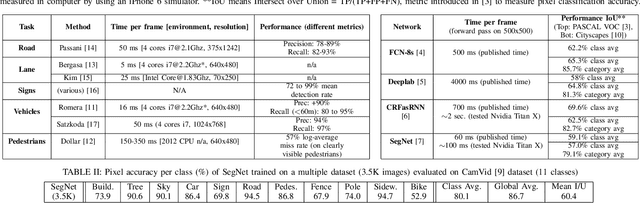
Autonomous driving is a challenging topic that requires complex solutions in perception tasks such as recognition of road, lanes, traffic signs or lights, vehicles and pedestrians. Through years of research, computer vision has grown capable of tackling these tasks with monocular detectors that can provide remarkable detection rates with relatively low processing times. However, the recent appearance of Convolutional Neural Networks (CNNs) has revolutionized the computer vision field and has made possible approaches to perform full pixel-wise semantic segmentation in times close to real time (even on hardware that can be carried on a vehicle). In this paper, we propose to use full image segmentation as an approach to simplify and unify most of the detection tasks required in the perception module of an autonomous vehicle, analyzing major concerns such as computation time and detection performance.