 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Attention GAN for Vehicle Motion Prediction
Sep 26, 2022
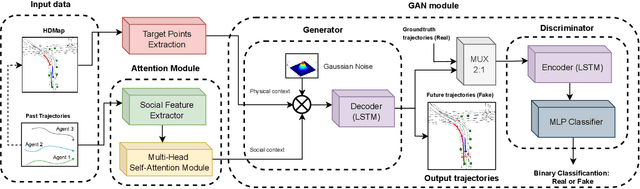
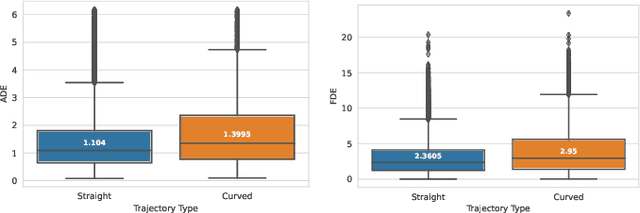
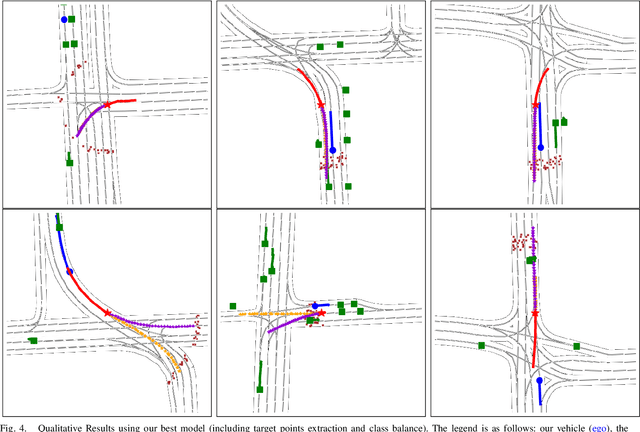
The design of a safe and reliable Autonomous Driving stack (ADS) is one of the most challenging tasks of our era. These ADS are expected to be driven in highly dynamic environments with full autonomy, and a reliability greater than human beings. In that sense, to efficiently and safely navigate through arbitrarily complex traffic scenarios, ADS must have the ability to forecast the future trajectories of surrounding actors. Current state-of-the-art models are typically based on Recurrent, Graph and Convolutional networks, achieving noticeable results in the context of vehicle prediction. In this paper we explore the influence of attention in generative models for motion prediction, considering both physical and social context to compute the most plausible trajectories. We first encode the past trajectories using a LSTM network, which serves as input to a Multi-Head Self-Attention module that computes the social context. On the other hand, we formulate a weighted interpolation to calculate the velocity and orientation in the last observation frame in order to calculate acceptable target points, extracted from the driveable of the HDMap information, which represents our physical context. Finally, the input of our generator is a white noise vector sampled from a multivariate normal distribution while the social and physical context are its conditions, in order to predict plausible trajectories. We validate our method using the Argoverse Motion Forecasting Benchmark 1.1, achieving competitive unimodal results.