 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeISA$^2$: Intelligent Speed Adaptation from Appearance
Oct 11, 2018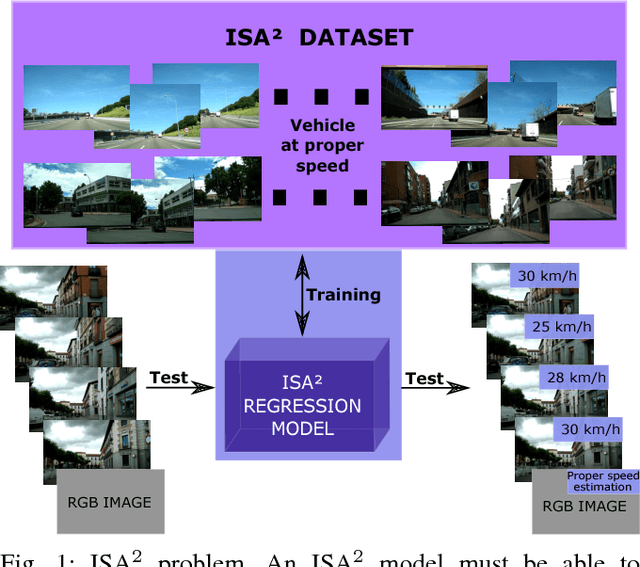



In this work we introduce a new problem named Intelligent Speed Adaptation from Appearance (ISA$^2$). Technically, the goal of an ISA$^2$ model is to predict for a given image of a driving scenario the proper speed of the vehicle. Note this problem is different from predicting the actual speed of the vehicle. It defines a novel regression problem where the appearance information has to be directly mapped to get a prediction for the speed at which the vehicle should go, taking into account the traffic situation. First, we release a novel dataset for the new problem, where multiple driving video sequences, with the annotated adequate speed per frame, are provided. We then introduce two deep learning based ISA$^2$ models, which are trained to perform the final regression of the proper speed given a test image. We end with a thorough experimental validation where the results show the level of difficulty of the proposed task. The dataset and the proposed models will all be made publicly available to encourage much needed further research on this problem.
In pixels we trust: From Pixel Labeling to Object Localization and Scene Categorization
Jul 19, 2018



While there has been significant progress in solving the problems of image pixel labeling, object detection and scene classification, existing approaches normally address them separately. In this paper, we propose to tackle these problems from a bottom-up perspective, where we simply need a semantic segmentation of the scene as input. We employ the DeepLab architecture, based on the ResNet deep network, which leverages multi-scale inputs to later fuse their responses to perform a precise pixel labeling of the scene. This semantic segmentation mask is used to localize the objects and to recognize the scene, following two simple yet effective strategies. We evaluate the benefits of our solutions, performing a thorough experimental evaluation on the NYU Depth V2 dataset. Our approach achieves a performance that beats the leading results by a significant margin, defining the new state of the art in this benchmark for the three tasks comprising the scene understanding: semantic segmentation, object detection and scene categorization.