 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised learning from videos using temporal coherency deep networks
Oct 11, 2018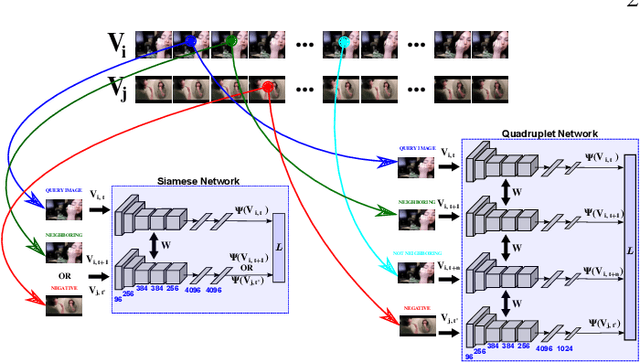

In this work we address the challenging problem of unsupervised learning from videos. Existing methods utilize the spatio-temporal continuity in contiguous video frames as regularization for the learning process. Typically, this temporal coherence of close frames is used as a free form of annotation, encouraging the learned representations to exhibit small differences between these frames. But this type of approach fails to capture the dissimilarity between videos with different content, hence learning less discriminative features. We here propose two Siamese architectures for Convolutional Neural Networks, and their corresponding novel loss functions, to learn from unlabeled videos, which jointly exploit the local temporal coherence between contiguous frames, and a global discriminative margin used to separate representations of different videos. An extensive experimental evaluation is presented, where we validate the proposed models on various tasks. First, we show how the learned features can be used to discover actions and scenes in video collections. Second, we show the benefits of such an unsupervised learning from just unlabeled videos, which can be directly used as a prior for the supervised recognition tasks of actions and objects in images, where our results further show that our features can even surpass a traditional and heavily supervised pre-training plus fine-tunning strategy.
In pixels we trust: From Pixel Labeling to Object Localization and Scene Categorization
Jul 19, 2018



While there has been significant progress in solving the problems of image pixel labeling, object detection and scene classification, existing approaches normally address them separately. In this paper, we propose to tackle these problems from a bottom-up perspective, where we simply need a semantic segmentation of the scene as input. We employ the DeepLab architecture, based on the ResNet deep network, which leverages multi-scale inputs to later fuse their responses to perform a precise pixel labeling of the scene. This semantic segmentation mask is used to localize the objects and to recognize the scene, following two simple yet effective strategies. We evaluate the benefits of our solutions, performing a thorough experimental evaluation on the NYU Depth V2 dataset. Our approach achieves a performance that beats the leading results by a significant margin, defining the new state of the art in this benchmark for the three tasks comprising the scene understanding: semantic segmentation, object detection and scene categorization.
Learning to Exploit the Prior Network Knowledge for Weakly-Supervised Semantic Segmentation
Apr 13, 2018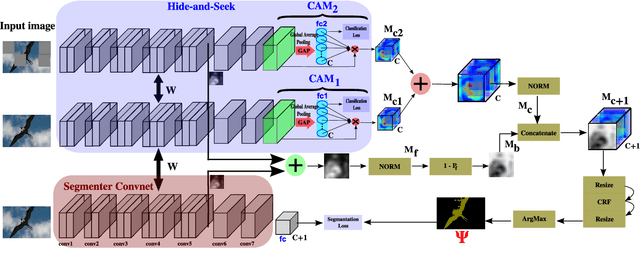



Training a Convolutional Neural Network (CNN) for semantic segmentation typically requires to collect a large amount of accurate pixel-level annotations, a hard and expensive task. In contrast, simple image tags are easier to gather. With this paper we introduce a novel weakly-supervised semantic segmentation model able to learn from image labels, and just image labels. Our model uses the prior knowledge of a network trained for image recognition, employing these image annotations, as an attention mechanism to identify semantic regions in the images. We then present a methodology that builds accurate class-specific segmentation masks from these regions, where neither external objectness nor saliency algorithms are required. We describe how to incorporate this mask generation strategy into a fully end-to-end trainable process where the network jointly learns to classify and segment images. Our experiments on PASCAL VOC 2012 dataset show that exploiting these generated class-specific masks in conjunction with our novel end-to-end learning process outperforms several recent weakly-supervised semantic segmentation methods that use image tags only, and even some models that leverage additional supervision or training data.
The challenge of simultaneous object detection and pose estimation: a comparative study
Jan 24, 2018

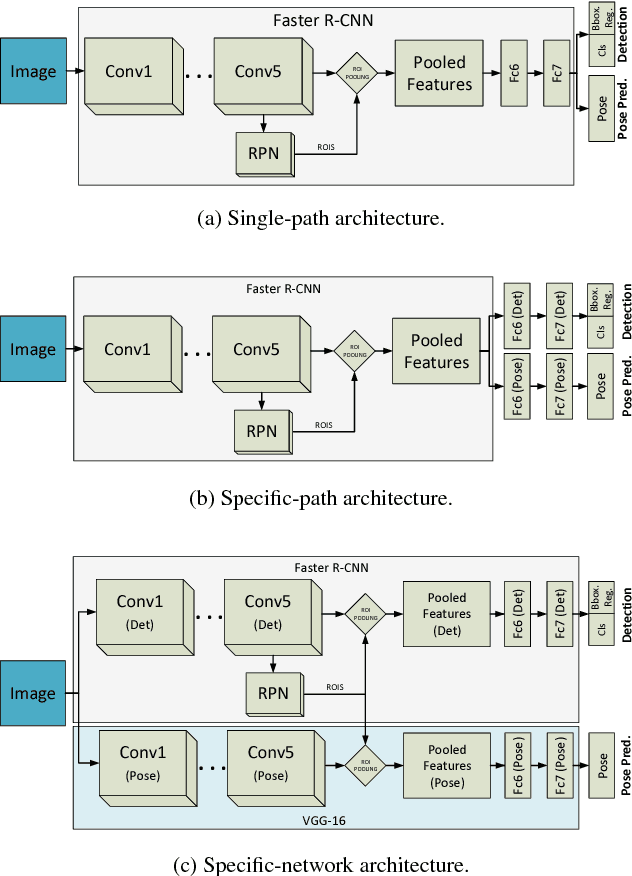

Detecting objects and estimating their pose remains as one of the major challenges of the computer vision research community. There exists a compromise between localizing the objects and estimating their viewpoints. The detector ideally needs to be view-invariant, while the pose estimation process should be able to generalize towards the category-level. This work is an exploration of using deep learning models for solving both problems simultaneously. For doing so, we propose three novel deep learning architectures, which are able to perform a joint detection and pose estimation, where we gradually decouple the two tasks. We also investigate whether the pose estimation problem should be solved as a classification or regression problem, being this still an open question in the computer vision community. We detail a comparative analysis of all our solutions and the methods that currently define the state of the art for this problem. We use PASCAL3D+ and ObjectNet3D datasets to present the thorough experimental evaluation and main results. With the proposed models we achieve the state-of-the-art performance in both datasets.