 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistory repeats Itself: A Baseline for Temporal Knowledge Graph Forecasting
Apr 29, 2024


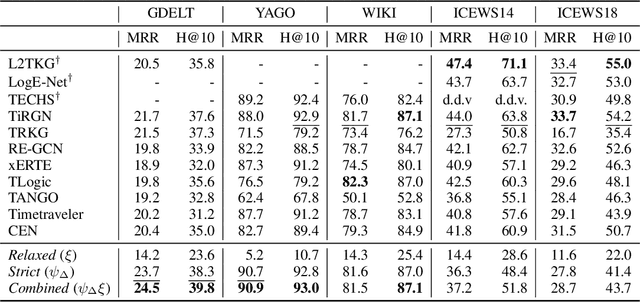
Temporal Knowledge Graph (TKG) Forecasting aims at predicting links in Knowledge Graphs for future timesteps based on a history of Knowledge Graphs. To this day, standardized evaluation protocols and rigorous comparison across TKG models are available, but the importance of simple baselines is often neglected in the evaluation, which prevents researchers from discerning actual and fictitious progress. We propose to close this gap by designing an intuitive baseline for TKG Forecasting based on predicting recurring facts. Compared to most TKG models, it requires little hyperparameter tuning and no iterative training. Further, it can help to identify failure modes in existing approaches. The empirical findings are quite unexpected: compared to 11 methods on five datasets, our baseline ranks first or third in three of them, painting a radically different picture of the predictive quality of the state of the art.
Human-Centric Research for NLP: Towards a Definition and Guiding Questions
Jul 10, 2022

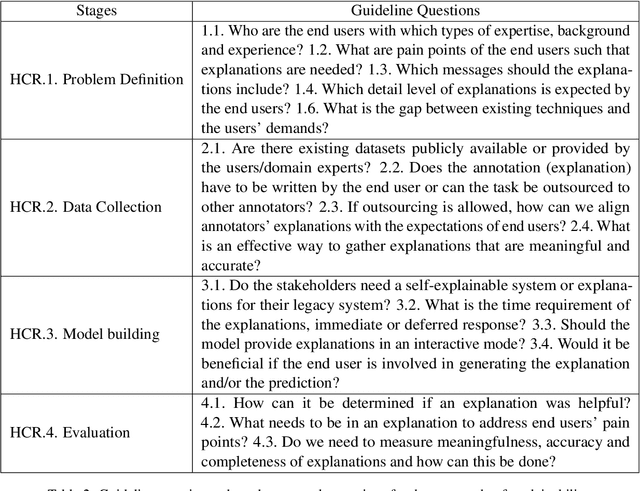
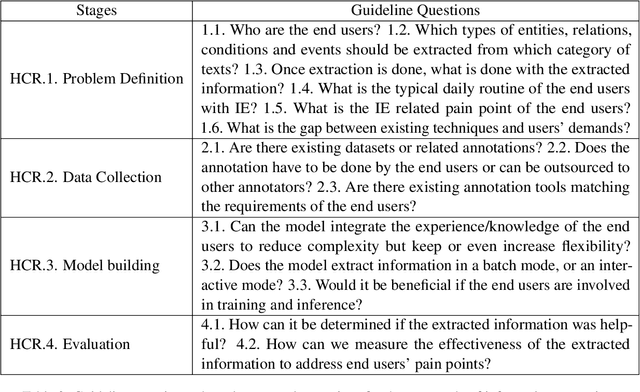
With Human-Centric Research (HCR) we can steer research activities so that the research outcome is beneficial for human stakeholders, such as end users. But what exactly makes research human-centric? We address this question by providing a working definition and define how a research pipeline can be split into different stages in which human-centric components can be added. Additionally, we discuss existing NLP with HCR components and define a series of guiding questions, which can serve as starting points for researchers interested in exploring human-centric research approaches. We hope that this work would inspire researchers to refine the proposed definition and to pose other questions that might be meaningful for achieving HCR.
ProcK: Machine Learning for Knowledge-Intensive Processes
Sep 10, 2021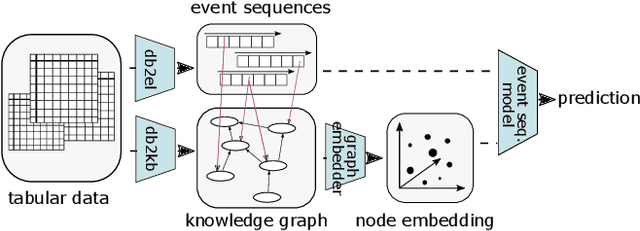
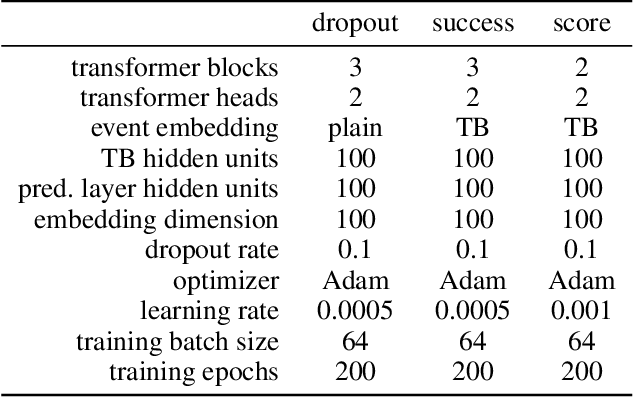
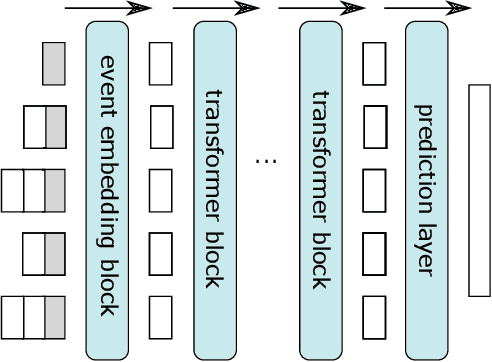
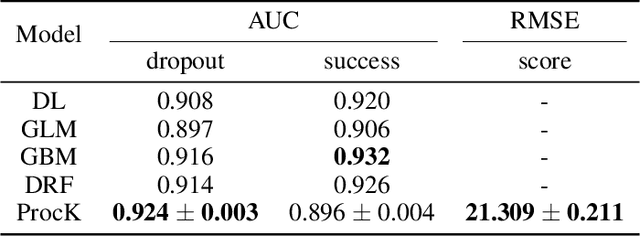
Process mining deals with extraction of knowledge from business process execution logs. Traditional process mining tasks, like process model generation or conformance checking, rely on a minimalistic feature set where each event is characterized only by its case identifier, activity type, and timestamp. In contrast, the success of modern machine learning is based on models that take any available data as direct input and build layers of features automatically during training. In this work, we introduce ProcK (Process & Knowledge), a novel pipeline to build business process prediction models that take into account both sequential data in the form of event logs and rich semantic information represented in a graph-structured knowledge base. The hybrid approach enables ProcK to flexibly make use of all information residing in the databases of organizations. Components to extract inter-linked event logs and knowledge bases from relational databases are part of the pipeline. We demonstrate the power of ProcK by training it for prediction tasks on the OULAD e-learning dataset, where we achieve state-of-the-art performance on the tasks of predicting student dropout from courses and predicting their success. We also apply our method on a number of additional machine learning tasks, including exam score prediction and early predictions that only take into account data recorded during the first weeks of the courses.
Explaining Neural Matrix Factorization with Gradient Rollback
Oct 14, 2020



Explaining the predictions of neural black-box models is an important problem, especially when such models are used in applications where user trust is crucial. Estimating the influence of training examples on a learned neural model's behavior allows us to identify training examples most responsible for a given prediction and, therefore, to faithfully explain the output of a black-box model. The most generally applicable existing method is based on influence functions, which scale poorly for larger sample sizes and models. We propose gradient rollback, a general approach for influence estimation, applicable to neural models where each parameter update step during gradient descent touches a smaller number of parameters, even if the overall number of parameters is large. Neural matrix factorization models trained with gradient descent are part of this model class. These models are popular and have found a wide range of applications in industry. Especially knowledge graph embedding methods, which belong to this class, are used extensively. We show that gradient rollback is highly efficient at both training and test time. Moreover, we show theoretically that the difference between gradient rollback's influence approximation and the true influence on a model's behavior is smaller than known bounds on the stability of stochastic gradient descent. This establishes that gradient rollback is robustly estimating example influence. We also conduct experiments which show that gradient rollback provides faithful explanations for knowledge base completion and recommender datasets.