 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcK: Machine Learning for Knowledge-Intensive Processes
Paper and Code
Sep 10, 2021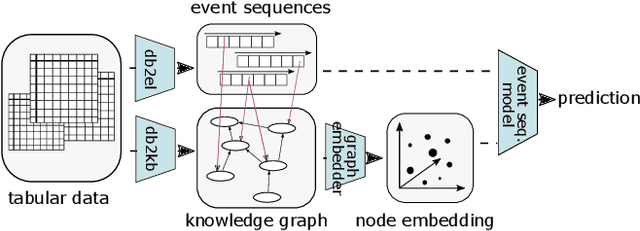
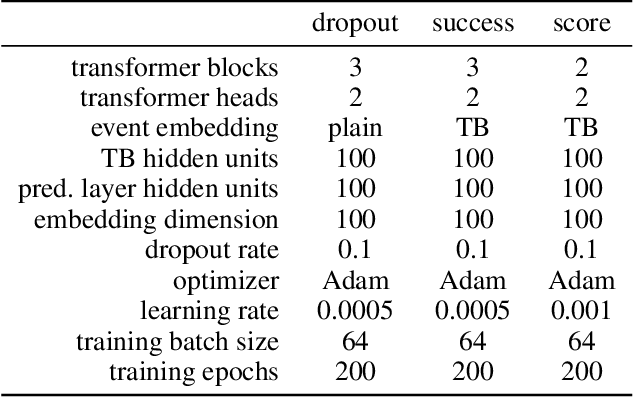
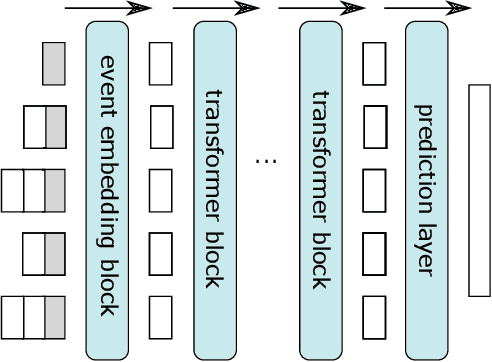
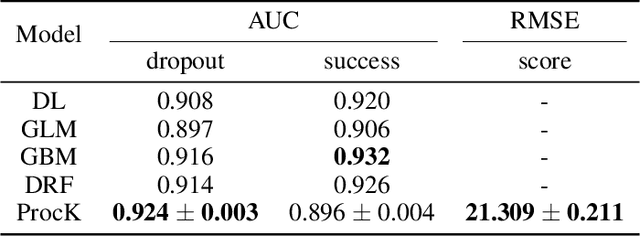
Process mining deals with extraction of knowledge from business process execution logs. Traditional process mining tasks, like process model generation or conformance checking, rely on a minimalistic feature set where each event is characterized only by its case identifier, activity type, and timestamp. In contrast, the success of modern machine learning is based on models that take any available data as direct input and build layers of features automatically during training. In this work, we introduce ProcK (Process & Knowledge), a novel pipeline to build business process prediction models that take into account both sequential data in the form of event logs and rich semantic information represented in a graph-structured knowledge base. The hybrid approach enables ProcK to flexibly make use of all information residing in the databases of organizations. Components to extract inter-linked event logs and knowledge bases from relational databases are part of the pipeline. We demonstrate the power of ProcK by training it for prediction tasks on the OULAD e-learning dataset, where we achieve state-of-the-art performance on the tasks of predicting student dropout from courses and predicting their success. We also apply our method on a number of additional machine learning tasks, including exam score prediction and early predictions that only take into account data recorded during the first weeks of the courses.