 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Human-Centric Assessment Framework for AI
May 25, 2022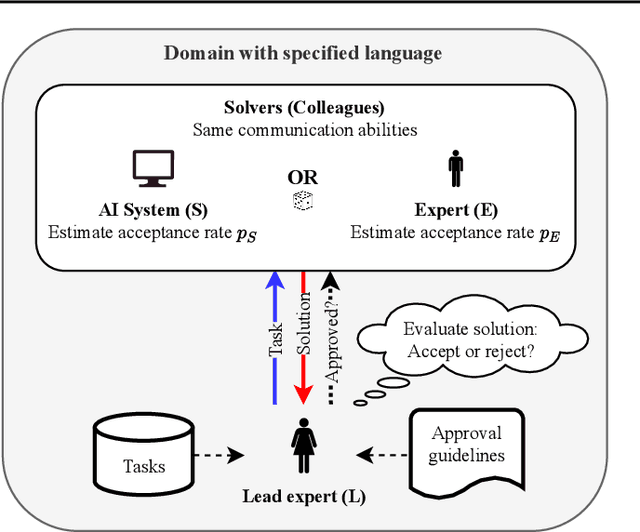
With the rise of AI systems in real-world applications comes the need for reliable and trustworthy AI. An important aspect for this are explainable AI systems. However, there is no agreed standard on how explainable AI systems should be assessed. Inspired by the Turing test, we introduce a human-centric assessment framework where a leading domain expert accepts or rejects the solutions of an AI system and another domain expert. By comparing the acceptance rates of provided solutions, we can assess how the AI system performs in comparison to the domain expert, and in turn whether or not the AI system's explanations (if provided) are human understandable. This setup -- comparable to the Turing test -- can serve as framework for a wide range of human-centric AI system assessments. We demonstrate this by presenting two instantiations: (1) an assessment that measures the classification accuracy of a system with the option to incorporate label uncertainties; (2) an assessment where the usefulness of provided explanations is determined in a human-centric manner.