 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Do Large Language Model Benchmarks Test Reliability?
Feb 05, 2025When deploying large language models (LLMs), it is important to ensure that these models are not only capable, but also reliable. Many benchmarks have been created to track LLMs' growing capabilities, however there has been no similar focus on measuring their reliability. To understand the potential ramifications of this gap, we investigate how well current benchmarks quantify model reliability. We find that pervasive label errors can compromise these evaluations, obscuring lingering model failures and hiding unreliable behavior. Motivated by this gap in the evaluation of reliability, we then propose the concept of so-called platinum benchmarks, i.e., benchmarks carefully curated to minimize label errors and ambiguity. As a first attempt at constructing such benchmarks, we revise examples from fifteen existing popular benchmarks. We evaluate a wide range of models on these platinum benchmarks and find that, indeed, frontier LLMs still exhibit failures on simple tasks such as elementary-level math word problems. Analyzing these failures further reveals previously unidentified patterns of problems on which frontier models consistently struggle. We provide code at https://github.com/MadryLab/platinum-benchmarks
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Ask Your Distribution Shift if Pre-Training is Right for You
Feb 29, 2024



Pre-training is a widely used approach to develop models that are robust to distribution shifts. However, in practice, its effectiveness varies: fine-tuning a pre-trained model improves robustness significantly in some cases but not at all in others (compared to training from scratch). In this work, we seek to characterize the failure modes that pre-training can and cannot address. In particular, we focus on two possible failure modes of models under distribution shift: poor extrapolation (e.g., they cannot generalize to a different domain) and biases in the training data (e.g., they rely on spurious features). Our study suggests that, as a rule of thumb, pre-training can help mitigate poor extrapolation but not dataset biases. After providing theoretical motivation and empirical evidence for this finding, we explore two of its implications for developing robust models: (1) pre-training and interventions designed to prevent exploiting biases have complementary robustness benefits, and (2) fine-tuning on a (very) small, non-diverse but de-biased dataset can result in significantly more robust models than fine-tuning on a large and diverse but biased dataset. Code is available at https://github.com/MadryLab/pretraining-distribution-shift-robustness.
The Journey, Not the Destination: How Data Guides Diffusion Models
Dec 11, 2023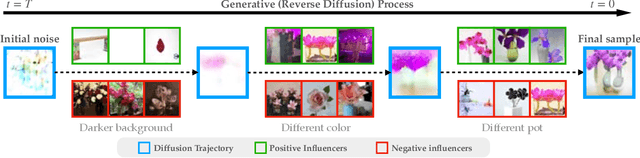
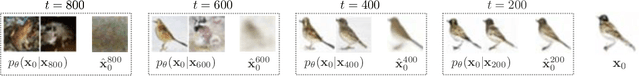

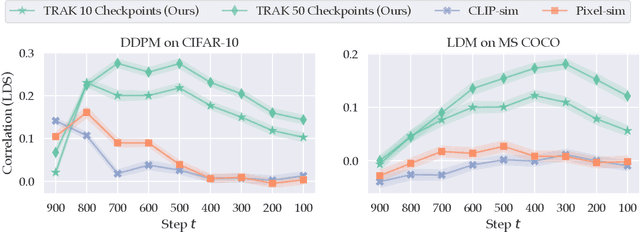
Diffusion models trained on large datasets can synthesize photo-realistic images of remarkable quality and diversity. However, attributing these images back to the training data-that is, identifying specific training examples which caused an image to be generated-remains a challenge. In this paper, we propose a framework that: (i) provides a formal notion of data attribution in the context of diffusion models, and (ii) allows us to counterfactually validate such attributions. Then, we provide a method for computing these attributions efficiently. Finally, we apply our method to find (and evaluate) such attributions for denoising diffusion probabilistic models trained on CIFAR-10 and latent diffusion models trained on MS COCO. We provide code at https://github.com/MadryLab/journey-TRAK .
Neural Nonnegative Matrix Factorization for Hierarchical Multilayer Topic Modeling
Feb 28, 2023We introduce a new method based on nonnegative matrix factorization, Neural NMF, for detecting latent hierarchical structure in data. Datasets with hierarchical structure arise in a wide variety of fields, such as document classification, image processing, and bioinformatics. Neural NMF recursively applies NMF in layers to discover overarching topics encompassing the lower-level features. We derive a backpropagation optimization scheme that allows us to frame hierarchical NMF as a neural network. We test Neural NMF on a synthetic hierarchical dataset, the 20 Newsgroups dataset, and the MyLymeData symptoms dataset. Numerical results demonstrate that Neural NMF outperforms other hierarchical NMF methods on these data sets and offers better learned hierarchical structure and interpretability of topics.
Dataset Interfaces: Diagnosing Model Failures Using Controllable Counterfactual Generation
Feb 15, 2023Distribution shifts are a major source of failure of deployed machine learning models. However, evaluating a model's reliability under distribution shifts can be challenging, especially since it may be difficult to acquire counterfactual examples that exhibit a specified shift. In this work, we introduce dataset interfaces: a framework which allows users to scalably synthesize such counterfactual examples from a given dataset. Specifically, we represent each class from the input dataset as a custom token within the text space of a text-to-image diffusion model. By incorporating these tokens into natural language prompts, we can then generate instantiations of objects in that dataset under desired distribution shifts. We demonstrate how applying our framework to the ImageNet dataset enables us to study model behavior across a diverse array of shifts, including variations in background, lighting, and attributes of the objects themselves. Code available at https://github.com/MadryLab/dataset-interfaces.
A Generalized Hierarchical Nonnegative Tensor Decomposition
Sep 30, 2021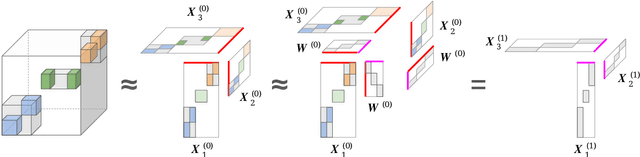
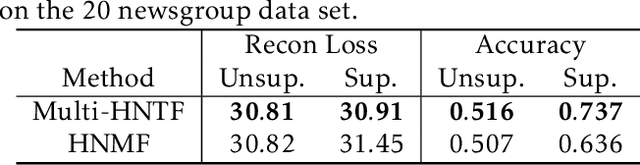
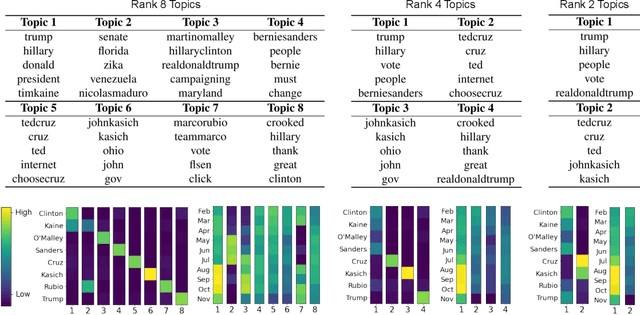
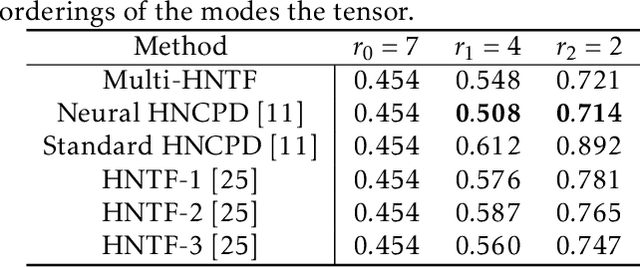
Nonnegative matrix factorization (NMF) has found many applications including topic modeling and document analysis. Hierarchical NMF (HNMF) variants are able to learn topics at various levels of granularity and illustrate their hierarchical relationship. Recently, nonnegative tensor factorization (NTF) methods have been applied in a similar fashion in order to handle data sets with complex, multi-modal structure. Hierarchical NTF (HNTF) methods have been proposed, however these methods do not naturally generalize their matrix-based counterparts. Here, we propose a new HNTF model which directly generalizes a HNMF model special case, and provide a supervised extension. We also provide a multiplicative updates training method for this model. Our experimental results show that this model more naturally illuminates the topic hierarchy than previous HNMF and HNTF methods.
Analysis of Legal Documents via Non-negative Matrix Factorization Methods
Apr 28, 2021The California Innocence Project (CIP), a clinical law school program aiming to free wrongfully convicted prisoners, evaluates thousands of mails containing new requests for assistance and corresponding case files. Processing and interpreting this large amount of information presents a significant challenge for CIP officials, which can be successfully aided by topic modeling techniques.In this paper, we apply Non-negative Matrix Factorization (NMF) method and implement various offshoots of it to the important and previously unstudied data set compiled by CIP. We identify underlying topics of existing case files and classify request files by crime type and case status (decision type). The results uncover the semantic structure of current case files and can provide CIP officials with a general understanding of newly received case files before further examinations. We also provide an exposition of popular variants of NMF with their experimental results and discuss the benefits and drawbacks of each variant through the real-world application.
Learning low-rank latent mesoscale structures in networks
Feb 13, 2021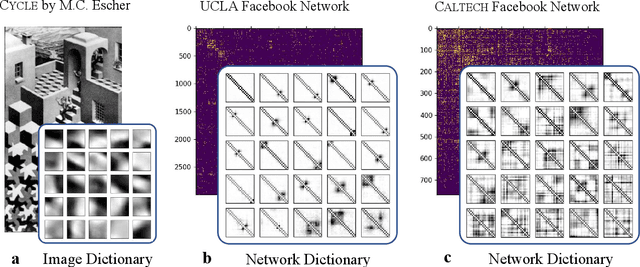
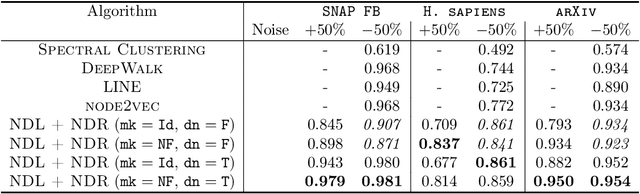

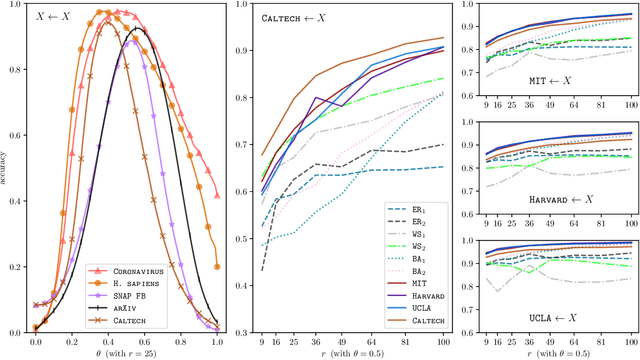
It is common to use networks to encode the architecture of interactions between entities in complex systems in the physical, biological, social, and information sciences. Moreover, to study the large-scale behavior of complex systems, it is important to study mesoscale structures in networks as building blocks that influence such behavior. In this paper, we present a new approach for describing low-rank mesoscale structure in networks, and we illustrate our approach using several synthetic network models and empirical friendship, collaboration, and protein--protein interaction (PPI) networks. We find that these networks possess a relatively small number of `latent motifs' that together can successfully approximate most subnetworks at a fixed mesoscale. We use an algorithm that we call "network dictionary learning" (NDL), which combines a network sampling method and nonnegative matrix factorization, to learn the latent motifs of a given network. The ability to encode a network using a set of latent motifs has a wide range of applications to network-analysis tasks, such as comparison, denoising, and edge inference. Additionally, using our new network denoising and reconstruction (NDR) algorithm, we demonstrate how to denoise a corrupted network by using only the latent motifs that one learns directly from the corrupted networks.