 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data for any Differentiable Target
Apr 09, 2026What are the limits of controlling language models via synthetic training data? We develop a reinforcement learning (RL) primitive, the Dataset Policy Gradient (DPG), which can precisely optimize synthetic data generators to produce a dataset of targeted examples. When used for supervised fine-tuning (SFT) of a target model, these examples cause the target model to do well on a differentiable metric of our choice. Our approach achieves this by taking exact data attribution via higher-order gradients and using those scores as policy gradient rewards. We prove that this procedure closely approximates the true, intractable gradient for the synthetic data generator. To illustrate the potential of DPG, we show that, using only SFT on generated examples, we can cause the target model's LM head weights to (1) embed a QR code, (2) embed the pattern $\texttt{67}$, and (3) have lower $\ell^2$ norm. We additionally show that we can cause the generator to (4) rephrase inputs in a new language and (5) produce a specific UUID, even though neither of these objectives is conveyed in the generator's input prompts. These findings suggest that DPG is a powerful and flexible technique for shaping model properties using only synthetic training examples.
Attribute-to-Delete: Machine Unlearning via Datamodel Matching
Oct 30, 2024



Machine unlearning -- efficiently removing the effect of a small "forget set" of training data on a pre-trained machine learning model -- has recently attracted significant research interest. Despite this interest, however, recent work shows that existing machine unlearning techniques do not hold up to thorough evaluation in non-convex settings. In this work, we introduce a new machine unlearning technique that exhibits strong empirical performance even in such challenging settings. Our starting point is the perspective that the goal of unlearning is to produce a model whose outputs are statistically indistinguishable from those of a model re-trained on all but the forget set. This perspective naturally suggests a reduction from the unlearning problem to that of data attribution, where the goal is to predict the effect of changing the training set on a model's outputs. Thus motivated, we propose the following meta-algorithm, which we call Datamodel Matching (DMM): given a trained model, we (a) use data attribution to predict the output of the model if it were re-trained on all but the forget set points; then (b) fine-tune the pre-trained model to match these predicted outputs. In a simple convex setting, we show how this approach provably outperforms a variety of iterative unlearning algorithms. Empirically, we use a combination of existing evaluations and a new metric based on the KL-divergence to show that even in non-convex settings, DMM achieves strong unlearning performance relative to existing algorithms. An added benefit of DMM is that it is a meta-algorithm, in the sense that future advances in data attribution translate directly into better unlearning algorithms, pointing to a clear direction for future progress in unlearning.
The Journey, Not the Destination: How Data Guides Diffusion Models
Dec 11, 2023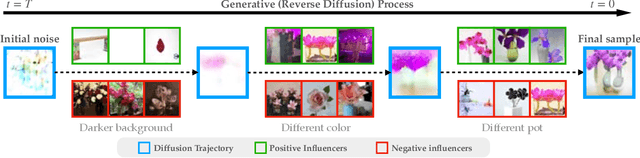
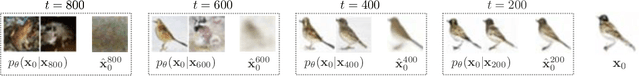

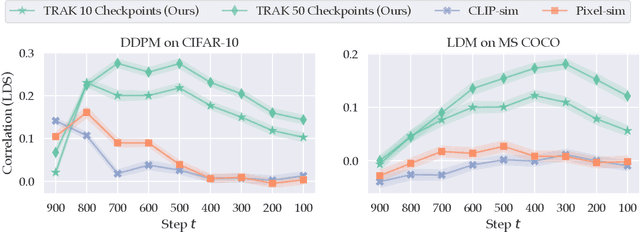
Diffusion models trained on large datasets can synthesize photo-realistic images of remarkable quality and diversity. However, attributing these images back to the training data-that is, identifying specific training examples which caused an image to be generated-remains a challenge. In this paper, we propose a framework that: (i) provides a formal notion of data attribution in the context of diffusion models, and (ii) allows us to counterfactually validate such attributions. Then, we provide a method for computing these attributions efficiently. Finally, we apply our method to find (and evaluate) such attributions for denoising diffusion probabilistic models trained on CIFAR-10 and latent diffusion models trained on MS COCO. We provide code at https://github.com/MadryLab/journey-TRAK .
FFCV: Accelerating Training by Removing Data Bottlenecks
Jun 21, 2023



We present FFCV, a library for easy and fast machine learning model training. FFCV speeds up model training by eliminating (often subtle) data bottlenecks from the training process. In particular, we combine techniques such as an efficient file storage format, caching, data pre-loading, asynchronous data transfer, and just-in-time compilation to (a) make data loading and transfer significantly more efficient, ensuring that GPUs can reach full utilization; and (b) offload as much data processing as possible to the CPU asynchronously, freeing GPU cycles for training. Using FFCV, we train ResNet-18 and ResNet-50 on the ImageNet dataset with competitive tradeoff between accuracy and training time. For example, we are able to train an ImageNet ResNet-50 model to 75\% in only 20 mins on a single machine. We demonstrate FFCV's performance, ease-of-use, extensibility, and ability to adapt to resource constraints through several case studies. Detailed installation instructions, documentation, and Slack support channel are available at https://ffcv.io/ .
TRAK: Attributing Model Behavior at Scale
Apr 03, 2023



The goal of data attribution is to trace model predictions back to training data. Despite a long line of work towards this goal, existing approaches to data attribution tend to force users to choose between computational tractability and efficacy. That is, computationally tractable methods can struggle with accurately attributing model predictions in non-convex settings (e.g., in the context of deep neural networks), while methods that are effective in such regimes require training thousands of models, which makes them impractical for large models or datasets. In this work, we introduce TRAK (Tracing with the Randomly-projected After Kernel), a data attribution method that is both effective and computationally tractable for large-scale, differentiable models. In particular, by leveraging only a handful of trained models, TRAK can match the performance of attribution methods that require training thousands of models. We demonstrate the utility of TRAK across various modalities and scales: image classifiers trained on ImageNet, vision-language models (CLIP), and language models (BERT and mT5). We provide code for using TRAK (and reproducing our work) at https://github.com/MadryLab/trak .
ModelDiff: A Framework for Comparing Learning Algorithms
Nov 22, 2022We study the problem of (learning) algorithm comparison, where the goal is to find differences between models trained with two different learning algorithms. We begin by formalizing this goal as one of finding distinguishing feature transformations, i.e., input transformations that change the predictions of models trained with one learning algorithm but not the other. We then present ModelDiff, a method that leverages the datamodels framework (Ilyas et al., 2022) to compare learning algorithms based on how they use their training data. We demonstrate ModelDiff through three case studies, comparing models trained with/without data augmentation, with/without pre-training, and with different SGD hyperparameters. Our code is available at https://github.com/MadryLab/modeldiff .
A Data-Based Perspective on Transfer Learning
Jul 12, 2022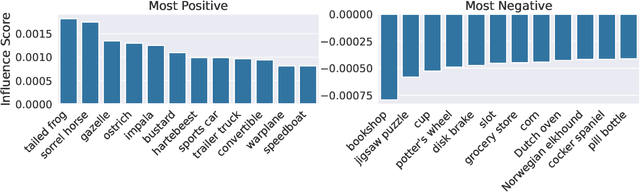
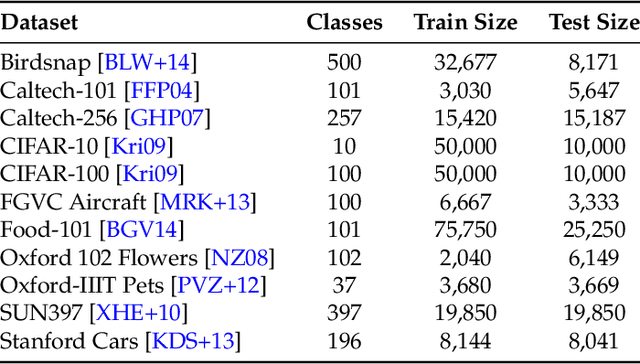
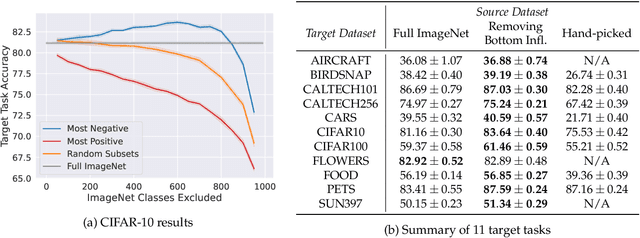
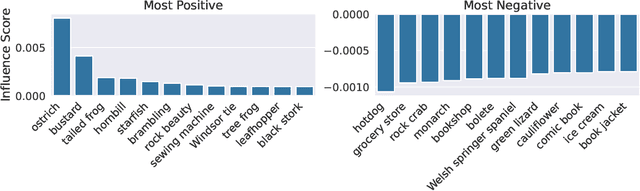
It is commonly believed that in transfer learning including more pre-training data translates into better performance. However, recent evidence suggests that removing data from the source dataset can actually help too. In this work, we take a closer look at the role of the source dataset's composition in transfer learning and present a framework for probing its impact on downstream performance. Our framework gives rise to new capabilities such as pinpointing transfer learning brittleness as well as detecting pathologies such as data-leakage and the presence of misleading examples in the source dataset. In particular, we demonstrate that removing detrimental datapoints identified by our framework improves transfer learning performance from ImageNet on a variety of target tasks. Code is available at https://github.com/MadryLab/data-transfer
Datamodels: Predicting Predictions from Training Data
Feb 01, 2022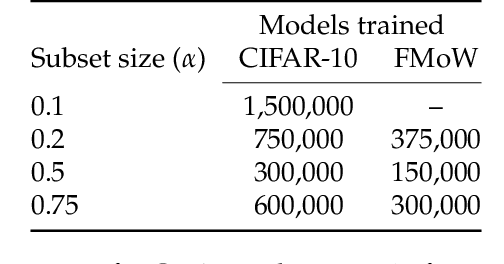


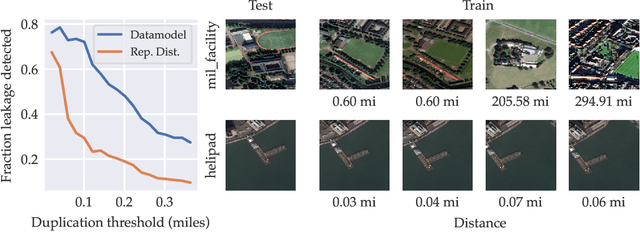
We present a conceptual framework, datamodeling, for analyzing the behavior of a model class in terms of the training data. For any fixed "target" example $x$, training set $S$, and learning algorithm, a datamodel is a parameterized function $2^S \to \mathbb{R}$ that for any subset of $S' \subset S$ -- using only information about which examples of $S$ are contained in $S'$ -- predicts the outcome of training a model on $S'$ and evaluating on $x$. Despite the potential complexity of the underlying process being approximated (e.g., end-to-end training and evaluation of deep neural networks), we show that even simple linear datamodels can successfully predict model outputs. We then demonstrate that datamodels give rise to a variety of applications, such as: accurately predicting the effect of dataset counterfactuals; identifying brittle predictions; finding semantically similar examples; quantifying train-test leakage; and embedding data into a well-behaved and feature-rich representation space. Data for this paper (including pre-computed datamodels as well as raw predictions from four million trained deep neural networks) is available at https://github.com/MadryLab/datamodels-data .
On Distinctive Properties of Universal Perturbations
Dec 31, 2021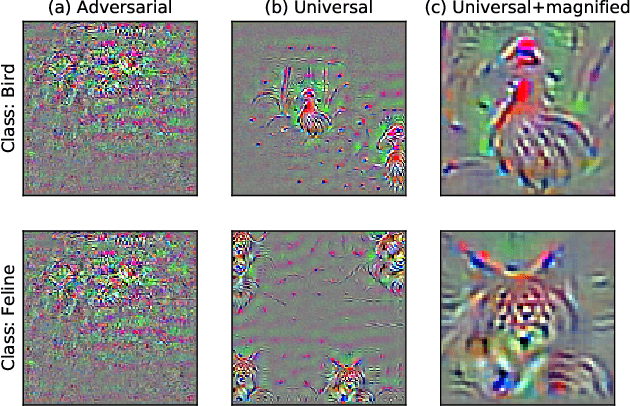
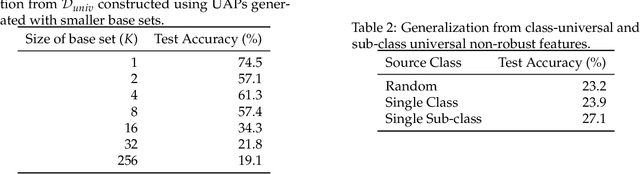
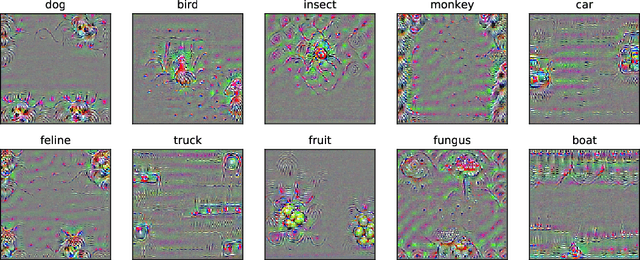
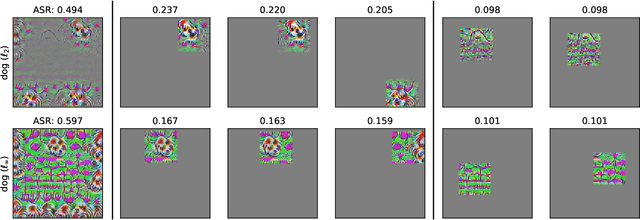
We identify properties of universal adversarial perturbations (UAPs) that distinguish them from standard adversarial perturbations. Specifically, we show that targeted UAPs generated by projected gradient descent exhibit two human-aligned properties: semantic locality and spatial invariance, which standard targeted adversarial perturbations lack. We also demonstrate that UAPs contain significantly less signal for generalization than standard adversarial perturbations -- that is, UAPs leverage non-robust features to a smaller extent than standard adversarial perturbations.
Sparse PCA from Sparse Linear Regression
Nov 25, 2018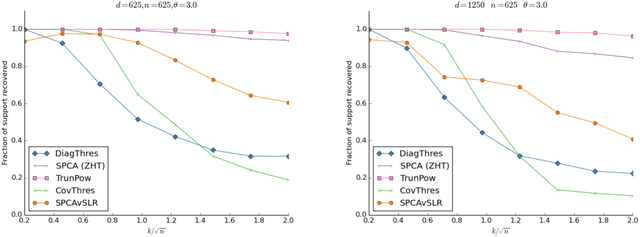
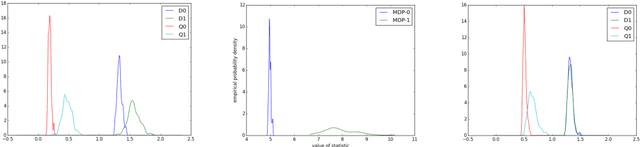
Sparse Principal Component Analysis (SPCA) and Sparse Linear Regression (SLR) have a wide range of applications and have attracted a tremendous amount of attention in the last two decades as canonical examples of statistical problems in high dimension. A variety of algorithms have been proposed for both SPCA and SLR, but an explicit connection between the two had not been made. We show how to efficiently transform a black-box solver for SLR into an algorithm for SPCA: assuming the SLR solver satisfies prediction error guarantees achieved by existing efficient algorithms such as those based on the Lasso, the SPCA algorithm derived from it achieves near state of the art guarantees for testing and for support recovery for the single spiked covariance model as obtained by the current best polynomialtime algorithms. Our reduction not only highlights the inherent similarity between the two problems, but also, from a practical standpoint, allows one to obtain a collection of algorithms for SPCA directly from known algorithms for SLR. We provide experimental results on simulated data comparing our proposed framework to other algorithms for SPCA.