 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Attribute with Attention
Apr 18, 2025Given a sequence of tokens generated by a language model, we may want to identify the preceding tokens that influence the model to generate this sequence. Performing such token attribution is expensive; a common approach is to ablate preceding tokens and directly measure their effects. To reduce the cost of token attribution, we revisit attention weights as a heuristic for how a language model uses previous tokens. Naive approaches to attribute model behavior with attention (e.g., averaging attention weights across attention heads to estimate a token's influence) have been found to be unreliable. To attain faithful attributions, we propose treating the attention weights of different attention heads as features. This way, we can learn how to effectively leverage attention weights for attribution (using signal from ablations). Our resulting method, Attribution with Attention (AT2), reliably performs on par with approaches that involve many ablations, while being significantly more efficient. To showcase the utility of AT2, we use it to prune less important parts of a provided context in a question answering setting, improving answer quality. We provide code for AT2 at https://github.com/MadryLab/AT2 .
SelfCite: Self-Supervised Alignment for Context Attribution in Large Language Models
Feb 13, 2025



We introduce SelfCite, a novel self-supervised approach that aligns LLMs to generate high-quality, fine-grained, sentence-level citations for the statements in their generated responses. Instead of only relying on costly and labor-intensive annotations, SelfCite leverages a reward signal provided by the LLM itself through context ablation: If a citation is necessary, removing the cited text from the context should prevent the same response; if sufficient, retaining the cited text alone should preserve the same response. This reward can guide the inference-time best-of-N sampling strategy to improve citation quality significantly, as well as be used in preference optimization to directly fine-tune the models for generating better citations. The effectiveness of SelfCite is demonstrated by increasing citation F1 up to 5.3 points on the LongBench-Cite benchmark across five long-form question answering tasks.
ContextCite: Attributing Model Generation to Context
Sep 01, 2024
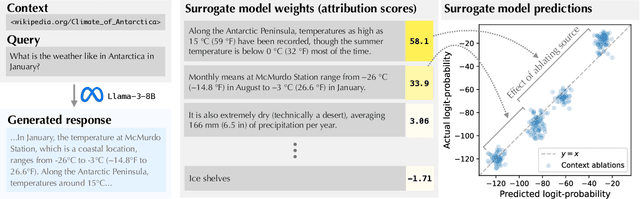
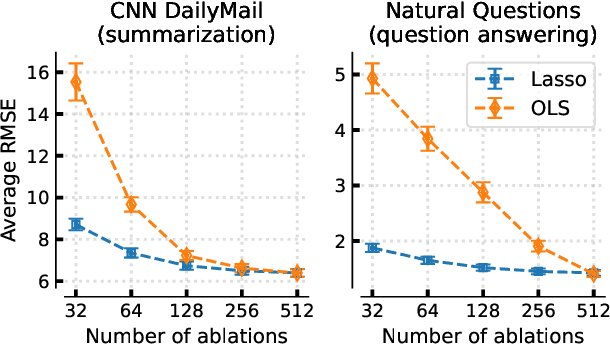
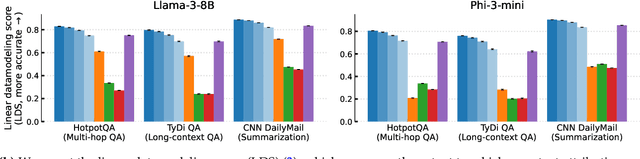
How do language models use information provided as context when generating a response? Can we infer whether a particular generated statement is actually grounded in the context, a misinterpretation, or fabricated? To help answer these questions, we introduce the problem of context attribution: pinpointing the parts of the context (if any) that led a model to generate a particular statement. We then present ContextCite, a simple and scalable method for context attribution that can be applied on top of any existing language model. Finally, we showcase the utility of ContextCite through three applications: (1) helping verify generated statements (2) improving response quality by pruning the context and (3) detecting poisoning attacks. We provide code for ContextCite at https://github.com/MadryLab/context-cite.
Ask Your Distribution Shift if Pre-Training is Right for You
Feb 29, 2024



Pre-training is a widely used approach to develop models that are robust to distribution shifts. However, in practice, its effectiveness varies: fine-tuning a pre-trained model improves robustness significantly in some cases but not at all in others (compared to training from scratch). In this work, we seek to characterize the failure modes that pre-training can and cannot address. In particular, we focus on two possible failure modes of models under distribution shift: poor extrapolation (e.g., they cannot generalize to a different domain) and biases in the training data (e.g., they rely on spurious features). Our study suggests that, as a rule of thumb, pre-training can help mitigate poor extrapolation but not dataset biases. After providing theoretical motivation and empirical evidence for this finding, we explore two of its implications for developing robust models: (1) pre-training and interventions designed to prevent exploiting biases have complementary robustness benefits, and (2) fine-tuning on a (very) small, non-diverse but de-biased dataset can result in significantly more robust models than fine-tuning on a large and diverse but biased dataset. Code is available at https://github.com/MadryLab/pretraining-distribution-shift-robustness.
Comparing the Value of Labeled and Unlabeled Data in Method-of-Moments Latent Variable Estimation
Mar 03, 2021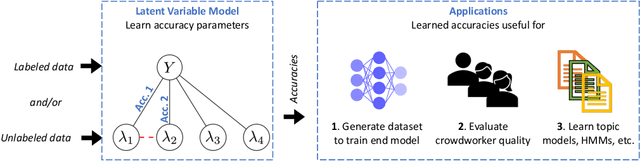
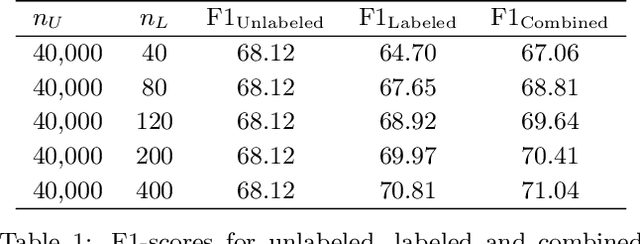
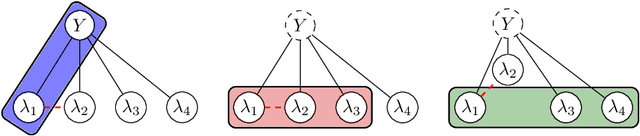

Labeling data for modern machine learning is expensive and time-consuming. Latent variable models can be used to infer labels from weaker, easier-to-acquire sources operating on unlabeled data. Such models can also be trained using labeled data, presenting a key question: should a user invest in few labeled or many unlabeled points? We answer this via a framework centered on model misspecification in method-of-moments latent variable estimation. Our core result is a bias-variance decomposition of the generalization error, which shows that the unlabeled-only approach incurs additional bias under misspecification. We then introduce a correction that provably removes this bias in certain cases. We apply our decomposition framework to three scenarios -- well-specified, misspecified, and corrected models -- to 1) choose between labeled and unlabeled data and 2) learn from their combination. We observe theoretically and with synthetic experiments that for well-specified models, labeled points are worth a constant factor more than unlabeled points. With misspecification, however, their relative value is higher due to the additional bias but can be reduced with correction. We also apply our approach to study real-world weak supervision techniques for dataset construction.