 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogicGraph : Benchmarking Multi-Path Logical Reasoning via Neuro-Symbolic Generation and Verification
Feb 24, 2026Evaluations of large language models (LLMs) primarily emphasize convergent logical reasoning, where success is defined by producing a single correct proof. However, many real-world reasoning problems admit multiple valid derivations, requiring models to explore diverse logical paths rather than committing to one route. To address this limitation, we introduce LogicGraph, the first benchmark aimed to systematically evaluate multi-path logical reasoning, constructed via a neuro-symbolic framework that leverages backward logic generation and semantic instantiation. This pipeline yields solver-verified reasoning problems formalized by high-depth multi-path reasoning and inherent logical distractions, where each instance is associated with an exhaustive set of minimal proofs. We further propose a reference-free evaluation framework to rigorously assess model performance in both convergent and divergent regimes. Experiments on state-of-the-art language models reveal a common limitation: models tend to commit early to a single route and fail to explore alternatives, and the coverage gap grows substantially with reasoning depth. LogicGraph exposes this divergence gap and provides actionable insights to motivate future improvements. Our code and data will be released at https://github.com/kkkkarry/LogicGraph.
AERO: Autonomous Evolutionary Reasoning Optimization via Endogenous Dual-Loop Feedback
Feb 03, 2026Large Language Models (LLMs) have achieved significant success in complex reasoning but remain bottlenecked by reliance on expert-annotated data and external verifiers. While existing self-evolution paradigms aim to bypass these constraints, they often fail to identify the optimal learning zone and risk reinforcing collective hallucinations and incorrect priors through flawed internal feedback. To address these challenges, we propose \underline{A}utonomous \underline{E}volutionary \underline{R}easoning \underline{O}ptimization (AERO), an unsupervised framework that achieves autonomous reasoning evolution by internalizing self-questioning, answering, and criticism within a synergistic dual-loop system. Inspired by the \textit{Zone of Proximal Development (ZPD)} theory, AERO utilizes entropy-based positioning to target the ``solvability gap'' and employs Independent Counterfactual Correction for robust verification. Furthermore, we introduce a Staggered Training Strategy to synchronize capability growth across functional roles and prevent curriculum collapse. Extensive evaluations across nine benchmarks spanning three domains demonstrate that AERO achieves average performance improvements of 4.57\% on Qwen3-4B-Base and 5.10\% on Qwen3-8B-Base, outperforming competitive baselines. Code is available at https://github.com/mira-ai-lab/AERO.
$\textbf{AGT$^{AO}$}$: Robust and Stabilized LLM Unlearning via Adversarial Gating Training with Adaptive Orthogonality
Feb 02, 2026While Large Language Models (LLMs) have achieved remarkable capabilities, they unintentionally memorize sensitive data, posing critical privacy and security risks. Machine unlearning is pivotal for mitigating these risks, yet existing paradigms face a fundamental dilemma: aggressive unlearning often induces catastrophic forgetting that degrades model utility, whereas conservative strategies risk superficial forgetting, leaving models vulnerable to adversarial recovery. To address this trade-off, we propose $\textbf{AGT$^{AO}$}$ (Adversarial Gating Training with Adaptive Orthogonality), a unified framework designed to reconcile robust erasure with utility preservation. Specifically, our approach introduces $\textbf{Adaptive Orthogonality (AO)}$ to dynamically mitigate geometric gradient conflicts between forgetting and retention objectives, thereby minimizing unintended knowledge degradation. Concurrently, $\textbf{Adversarial Gating Training (AGT)}$ formulates unlearning as a latent-space min-max game, employing a curriculum-based gating mechanism to simulate and counter internal recovery attempts. Extensive experiments demonstrate that $\textbf{AGT$^{AO}$}$ achieves a superior trade-off between unlearning efficacy (KUR $\approx$ 0.01) and model utility (MMLU 58.30). Code is available at https://github.com/TiezMind/AGT-unlearning.
PathFinder: Advancing Path Loss Prediction for Single-to-Multi-Transmitter Scenario
Dec 16, 2025Radio path loss prediction (RPP) is critical for optimizing 5G networks and enabling IoT, smart city, and similar applications. However, current deep learning-based RPP methods lack proactive environmental modeling, struggle with realistic multi-transmitter scenarios, and generalize poorly under distribution shifts, particularly when training/testing environments differ in building density or transmitter configurations. This paper identifies three key issues: (1) passive environmental modeling that overlooks transmitters and key environmental features; (2) overemphasis on single-transmitter scenarios despite real-world multi-transmitter prevalence; (3) excessive focus on in-distribution performance while neglecting distribution shift challenges. To address these, we propose PathFinder, a novel architecture that actively models buildings and transmitters via disentangled feature encoding and integrates Mask-Guided Low-rank Attention to independently focus on receiver and building regions. We also introduce a Transmitter-Oriented Mixup strategy for robust training and a new benchmark, single-to-multi-transmitter RPP (S2MT-RPP), tailored to evaluate extrapolation performance (multi-transmitter testing after single-transmitter training). Experimental results show PathFinder outperforms state-of-the-art methods significantly, especially in challenging multi-transmitter scenarios. Our code and project site are available at: https://emorzz1g.github.io/PathFinder/.
Finding Kissing Numbers with Game-theoretic Reinforcement Learning
Nov 17, 2025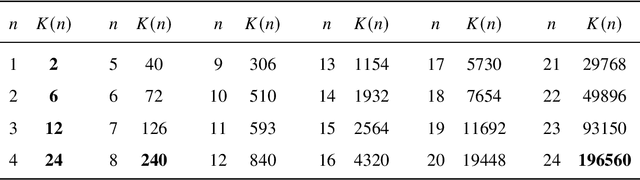
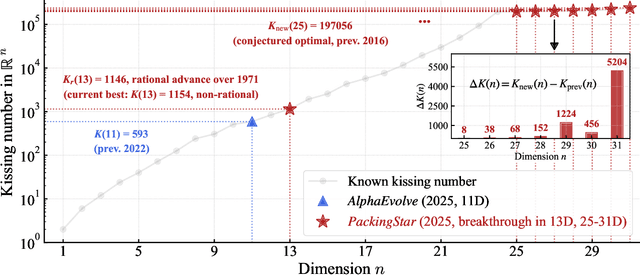

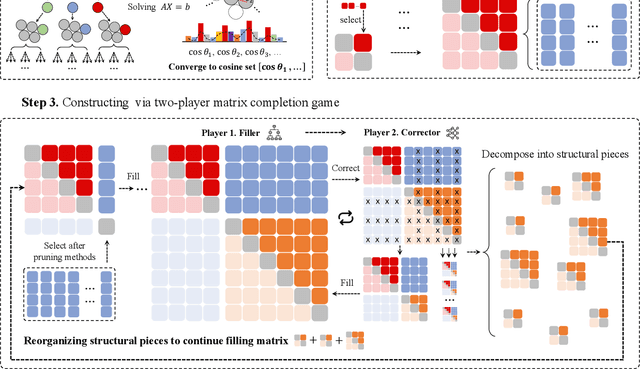
Since Isaac Newton first studied the Kissing Number Problem in 1694, determining the maximal number of non-overlapping spheres around a central sphere has remained a fundamental challenge. This problem represents the local analogue of Hilbert's 18th problem on sphere packing, bridging geometry, number theory, and information theory. Although significant progress has been made through lattices and codes, the irregularities of high-dimensional geometry and exponentially growing combinatorial complexity beyond 8 dimensions, which exceeds the complexity of Go game, limit the scalability of existing methods. Here we model this problem as a two-player matrix completion game and train the game-theoretic reinforcement learning system, PackingStar, to efficiently explore high-dimensional spaces. The matrix entries represent pairwise cosines of sphere center vectors; one player fills entries while another corrects suboptimal ones, jointly maximizing the matrix size, corresponding to the kissing number. This cooperative dynamics substantially improves sample quality, making the extremely large spaces tractable. PackingStar reproduces previous configurations and surpasses all human-known records from dimensions 25 to 31, with the configuration in 25 dimensions geometrically corresponding to the Leech lattice and suggesting possible optimality. It achieves the first breakthrough beyond rational structures from 1971 in 13 dimensions and discovers over 6000 new structures in 14 and other dimensions. These results demonstrate AI's power to explore high-dimensional spaces beyond human intuition and open new pathways for the Kissing Number Problem and broader geometry problems.
A New Perspective on Time Series Anomaly Detection: Faster Patch-based Broad Learning System
Dec 07, 2024



Time series anomaly detection (TSAD) has been a research hotspot in both academia and industry in recent years. Deep learning methods have become the mainstream research direction due to their excellent performance. However, new viewpoints have emerged in recent TSAD research. Deep learning is not required for TSAD due to limitations such as slow deep learning speed. The Broad Learning System (BLS) is a shallow network framework that benefits from its ease of optimization and speed. It has been shown to outperform machine learning approaches while remaining competitive with deep learning. Based on the current situation of TSAD, we propose the Contrastive Patch-based Broad Learning System (CPatchBLS). This is a new exploration of patching technique and BLS, providing a new perspective for TSAD. We construct Dual-PatchBLS as a base through patching and Simple Kernel Perturbation (SKP) and utilize contrastive learning to capture the differences between normal and abnormal data under different representations. To compensate for the temporal semantic loss caused by various patching, we propose CPatchBLS with model level integration, which takes advantage of BLS's fast feature to build model-level integration and improve model detection. Using five real-world series anomaly detection datasets, we confirmed the method's efficacy, outperforming previous deep learning and machine learning methods while retaining a high level of computing efficiency.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
EMDFNet: Efficient Multi-scale and Diverse Feature Network for Traffic Sign Detection
Aug 26, 2024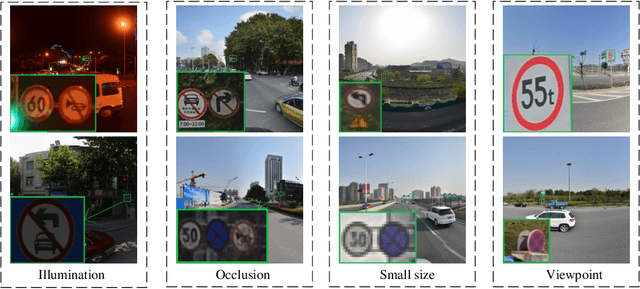
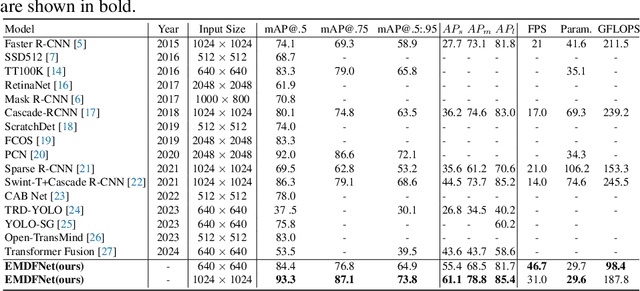
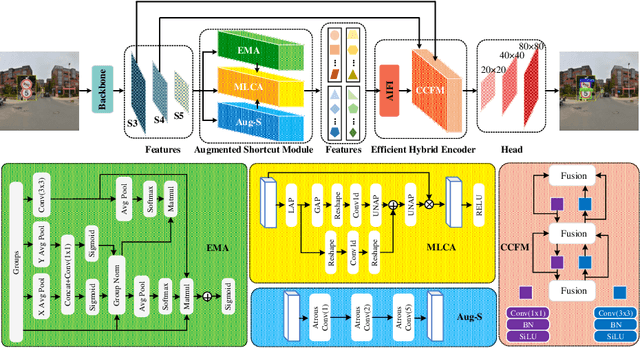
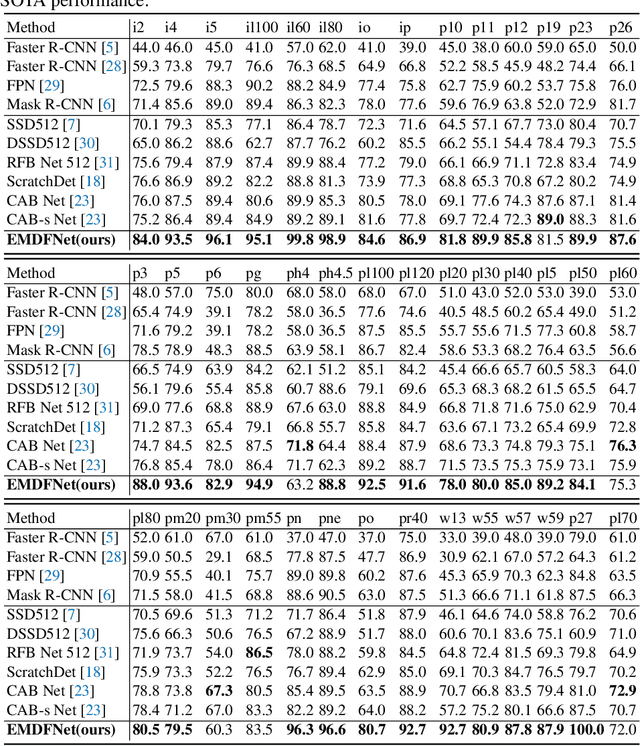
The detection of small objects, particularly traffic signs, is a critical subtask within object detection and autonomous driving. Despite the notable achievements in previous research, two primary challenges persist. Firstly, the main issue is the singleness of feature extraction. Secondly, the detection process fails to effectively integrate with objects of varying sizes or scales. These issues are also prevalent in generic object detection. Motivated by these challenges, in this paper, we propose a novel object detection network named Efficient Multi-scale and Diverse Feature Network (EMDFNet) for traffic sign detection that integrates an Augmented Shortcut Module and an Efficient Hybrid Encoder to address the aforementioned issues simultaneously. Specifically, the Augmented Shortcut Module utilizes multiple branches to integrate various spatial semantic information and channel semantic information, thereby enhancing feature diversity. The Efficient Hybrid Encoder utilizes global feature fusion and local feature interaction based on various features to generate distinctive classification features by integrating feature information in an adaptable manner. Extensive experiments on the Tsinghua-Tencent 100K (TT100K) benchmark and the German Traffic Sign Detection Benchmark (GTSDB) demonstrate that our EMDFNet outperforms other state-of-the-art detectors in performance while retaining the real-time processing capabilities of single-stage models. This substantiates the effectiveness of EMDFNet in detecting small traffic signs.
PersonificationNet: Making customized subject act like a person
Jul 12, 2024



Recently customized generation has significant potential, which uses as few as 3-5 user-provided images to train a model to synthesize new images of a specified subject. Though subsequent applications enhance the flexibility and diversity of customized generation, fine-grained control over the given subject acting like the person's pose is still lack of study. In this paper, we propose a PersonificationNet, which can control the specified subject such as a cartoon character or plush toy to act the same pose as a given referenced person's image. It contains a customized branch, a pose condition branch and a structure alignment module. Specifically, first, the customized branch mimics specified subject appearance. Second, the pose condition branch transfers the body structure information from the human to variant instances. Last, the structure alignment module bridges the structure gap between human and specified subject in the inference stage. Experimental results show our proposed PersonificationNet outperforms the state-of-the-art methods.
Sim2Real in Reconstructive Spectroscopy: Deep Learning with Augmented Device-Informed Data Simulation
Mar 19, 2024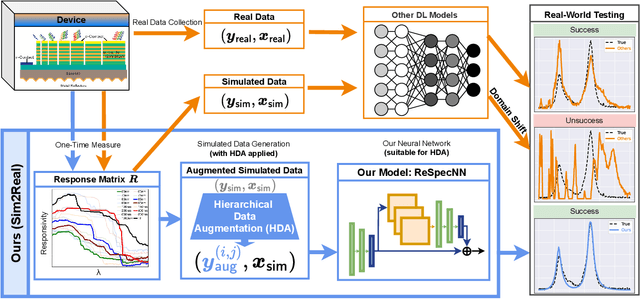

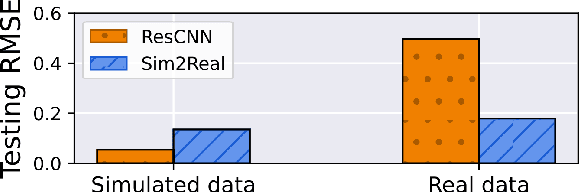
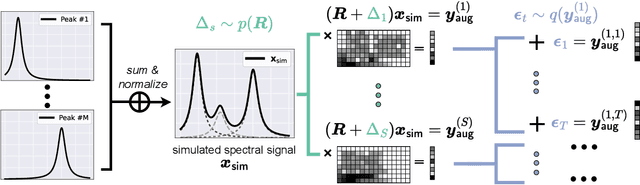
This work proposes a deep learning (DL)-based framework, namely Sim2Real, for spectral signal reconstruction in reconstructive spectroscopy, focusing on efficient data sampling and fast inference time. The work focuses on the challenge of reconstructing real-world spectral signals under the extreme setting where only device-informed simulated data are available for training. Such device-informed simulated data are much easier to collect than real-world data but exhibit large distribution shifts from their real-world counterparts. To leverage such simulated data effectively, a hierarchical data augmentation strategy is introduced to mitigate the adverse effects of this domain shift, and a corresponding neural network for the spectral signal reconstruction with our augmented data is designed. Experiments using a real dataset measured from our spectrometer device demonstrate that Sim2Real achieves significant speed-up during the inference while attaining on-par performance with the state-of-the-art optimization-based methods.