 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLDesigner: Leveraging Multi-Modal LLMs as Designer for Enhanced Aesthetic Text Glyph Layouts
Nov 18, 2024

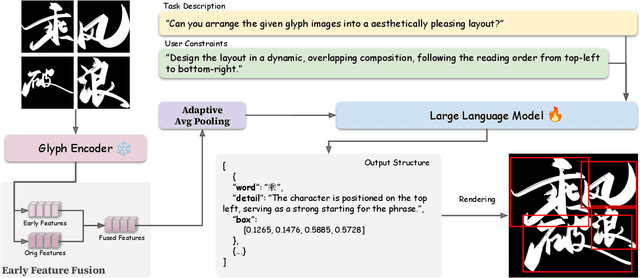
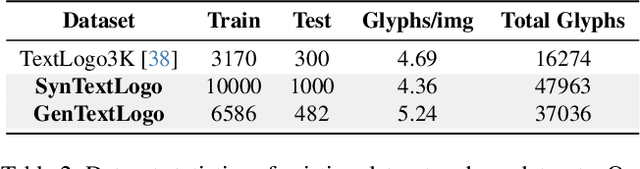
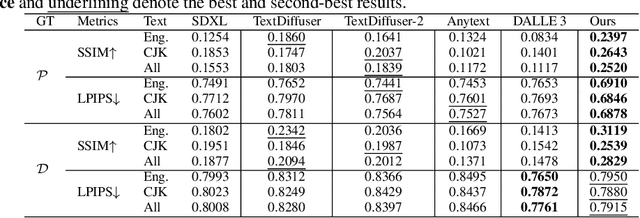
Text logo design heavily relies on the creativity and expertise of professional designers, in which arranging element layouts is one of the most important procedures. However, few attention has been paid to this specific task which needs to take precise textural details and user constraints into consideration, but only on the broader tasks such as document/poster layout generation. In this paper, we propose a VLM-based framework that generates content-aware text logo layouts by integrating multi-modal inputs with user constraints, supporting a more flexible and stable layout design in real-world applications. We introduce two model techniques to reduce the computation for processing multiple glyph images simultaneously, while does not face performance degradation. To support instruction-tuning of out model, we construct two extensive text logo datasets, which are 5x more larger than the existing public dataset. Except for the geometric annotations (e.g. text masks and character recognition), we also compliment with comprehensive layout descriptions in natural language format, for more effective training to have reasoning ability when dealing with complex layouts and custom user constraints. Experimental studies demonstrate the effectiveness of our proposed model and datasets, when comparing with previous methods in various benchmarks to evaluate geometric aesthetics and human preferences. The code and datasets will be publicly available.
MetaDesigner: Advancing Artistic Typography through AI-Driven, User-Centric, and Multilingual WordArt Synthesis
Jun 28, 2024
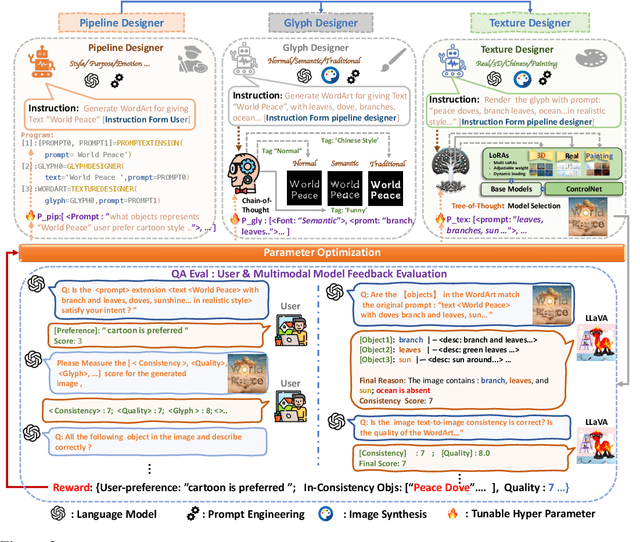
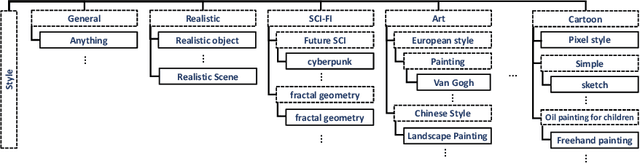
MetaDesigner revolutionizes artistic typography synthesis by leveraging the strengths of Large Language Models (LLMs) to drive a design paradigm centered around user engagement. At the core of this framework lies a multi-agent system comprising the Pipeline, Glyph, and Texture agents, which collectively enable the creation of customized WordArt, ranging from semantic enhancements to the imposition of complex textures. MetaDesigner incorporates a comprehensive feedback mechanism that harnesses insights from multimodal models and user evaluations to refine and enhance the design process iteratively. Through this feedback loop, the system adeptly tunes hyperparameters to align with user-defined stylistic and thematic preferences, generating WordArt that not only meets but exceeds user expectations of visual appeal and contextual relevance. Empirical validations highlight MetaDesigner's capability to effectively serve diverse WordArt applications, consistently producing aesthetically appealing and context-sensitive results.
Multi-modal Instruction Tuned LLMs with Fine-grained Visual Perception
Mar 05, 2024Multimodal Large Language Model (MLLMs) leverages Large Language Models as a cognitive framework for diverse visual-language tasks. Recent efforts have been made to equip MLLMs with visual perceiving and grounding capabilities. However, there still remains a gap in providing fine-grained pixel-level perceptions and extending interactions beyond text-specific inputs. In this work, we propose {\bf{AnyRef}}, a general MLLM model that can generate pixel-wise object perceptions and natural language descriptions from multi-modality references, such as texts, boxes, images, or audio. This innovation empowers users with greater flexibility to engage with the model beyond textual and regional prompts, without modality-specific designs. Through our proposed refocusing mechanism, the generated grounding output is guided to better focus on the referenced object, implicitly incorporating additional pixel-level supervision. This simple modification utilizes attention scores generated during the inference of LLM, eliminating the need for extra computations while exhibiting performance enhancements in both grounding masks and referring expressions. With only publicly available training data, our model achieves state-of-the-art results across multiple benchmarks, including diverse modality referring segmentation and region-level referring expression generation.
Towards Deeply Unified Depth-aware Panoptic Segmentation with Bi-directional Guidance Learning
Aug 14, 2023Depth-aware panoptic segmentation is an emerging topic in computer vision which combines semantic and geometric understanding for more robust scene interpretation. Recent works pursue unified frameworks to tackle this challenge but mostly still treat it as two individual learning tasks, which limits their potential for exploring cross-domain information. We propose a deeply unified framework for depth-aware panoptic segmentation, which performs joint segmentation and depth estimation both in a per-segment manner with identical object queries. To narrow the gap between the two tasks, we further design a geometric query enhancement method, which is able to integrate scene geometry into object queries using latent representations. In addition, we propose a bi-directional guidance learning approach to facilitate cross-task feature learning by taking advantage of their mutual relations. Our method sets the new state of the art for depth-aware panoptic segmentation on both Cityscapes-DVPS and SemKITTI-DVPS datasets. Moreover, our guidance learning approach is shown to deliver performance improvement even under incomplete supervision labels.
Tracking Anything in High Quality
Jul 26, 2023Visual object tracking is a fundamental video task in computer vision. Recently, the notably increasing power of perception algorithms allows the unification of single/multiobject and box/mask-based tracking. Among them, the Segment Anything Model (SAM) attracts much attention. In this report, we propose HQTrack, a framework for High Quality Tracking anything in videos. HQTrack mainly consists of a video multi-object segmenter (VMOS) and a mask refiner (MR). Given the object to be tracked in the initial frame of a video, VMOS propagates the object masks to the current frame. The mask results at this stage are not accurate enough since VMOS is trained on several closeset video object segmentation (VOS) datasets, which has limited ability to generalize to complex and corner scenes. To further improve the quality of tracking masks, a pretrained MR model is employed to refine the tracking results. As a compelling testament to the effectiveness of our paradigm, without employing any tricks such as test-time data augmentations and model ensemble, HQTrack ranks the 2nd place in the Visual Object Tracking and Segmentation (VOTS2023) challenge. Code and models are available at https://github.com/jiawen-zhu/HQTrack.
LongShortNet: Exploring Temporal and Semantic Features Fusion in Streaming Perception
Oct 27, 2022Streaming perception is a task of reporting the current state of autonomous driving, which coherently considers the latency and accuracy of autopilot systems. However, the existing streaming perception only uses the current and adjacent two frames as input for learning the movement patterns, which cannot model actual complex scenes, resulting in failed detection results. To solve this problem, we propose an end-to-end dual-path network dubbed LongShortNet, which captures long-term temporal motion and calibrates it with short-term spatial semantics for real-time perception. Moreover, we investigate a Long-Short Fusion Module (LSFM) to explore spatiotemporal feature fusion, which is the first work to extend long-term temporal in streaming perception. We evaluate the proposed LongShortNet and compare it with existing methods on the benchmark dataset Argoverse-HD. The results demonstrate that the proposed LongShortNet outperforms the other state-of-the-art methods with almost no extra computational cost.
ProContEXT: Exploring Progressive Context Transformer for Tracking
Oct 27, 2022Existing Visual Object Tracking (VOT) only takes the target area in the first frame as a template. This causes tracking to inevitably fail in fast-changing and crowded scenes, as it cannot account for changes in object appearance between frames. To this end, we revamped the tracking framework with Progressive Context Encoding Transformer Tracker (ProContEXT), which coherently exploits spatial and temporal contexts to predict object motion trajectories. Specifically, ProContEXT leverages a context-aware self-attention module to encode the spatial and temporal context, refining and updating the multi-scale static and dynamic templates to progressively perform accurate tracking. It explores the complementary between spatial and temporal context, raising a new pathway to multi-context modeling for transformer-based trackers. In addition, ProContEXT revised the token pruning technique to reduce computational complexity. Extensive experiments on popular benchmark datasets such as GOT-10k and TrackingNet demonstrate that the proposed ProContEXT achieves state-of-the-art performance.