 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecuring the Skies: A Comprehensive Survey on Anti-UAV Methods, Benchmarking, and Future Directions
Apr 16, 2025Unmanned Aerial Vehicles (UAVs) are indispensable for infrastructure inspection, surveillance, and related tasks, yet they also introduce critical security challenges. This survey provides a wide-ranging examination of the anti-UAV domain, centering on three core objectives-classification, detection, and tracking-while detailing emerging methodologies such as diffusion-based data synthesis, multi-modal fusion, vision-language modeling, self-supervised learning, and reinforcement learning. We systematically evaluate state-of-the-art solutions across both single-modality and multi-sensor pipelines (spanning RGB, infrared, audio, radar, and RF) and discuss large-scale as well as adversarially oriented benchmarks. Our analysis reveals persistent gaps in real-time performance, stealth detection, and swarm-based scenarios, underscoring pressing needs for robust, adaptive anti-UAV systems. By highlighting open research directions, we aim to foster innovation and guide the development of next-generation defense strategies in an era marked by the extensive use of UAVs.
Why We Feel: Breaking Boundaries in Emotional Reasoning with Multimodal Large Language Models
Apr 10, 2025Most existing emotion analysis emphasizes which emotion arises (e.g., happy, sad, angry) but neglects the deeper why. We propose Emotion Interpretation (EI), focusing on causal factors-whether explicit (e.g., observable objects, interpersonal interactions) or implicit (e.g., cultural context, off-screen events)-that drive emotional responses. Unlike traditional emotion recognition, EI tasks require reasoning about triggers instead of mere labeling. To facilitate EI research, we present EIBench, a large-scale benchmark encompassing 1,615 basic EI samples and 50 complex EI samples featuring multifaceted emotions. Each instance demands rationale-based explanations rather than straightforward categorization. We further propose a Coarse-to-Fine Self-Ask (CFSA) annotation pipeline, which guides Vision-Language Models (VLLMs) through iterative question-answer rounds to yield high-quality labels at scale. Extensive evaluations on open-source and proprietary large language models under four experimental settings reveal consistent performance gaps-especially for more intricate scenarios-underscoring EI's potential to enrich empathetic, context-aware AI applications. Our benchmark and methods are publicly available at: https://github.com/Lum1104/EIBench, offering a foundation for advanced multimodal causal analysis and next-generation affective computing.
HA-VLN: A Benchmark for Human-Aware Navigation in Discrete-Continuous Environments with Dynamic Multi-Human Interactions, Real-World Validation, and an Open Leaderboard
Mar 18, 2025
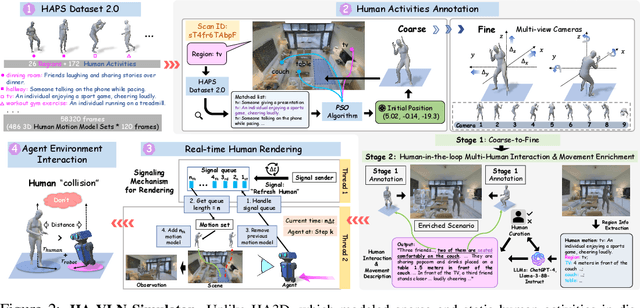
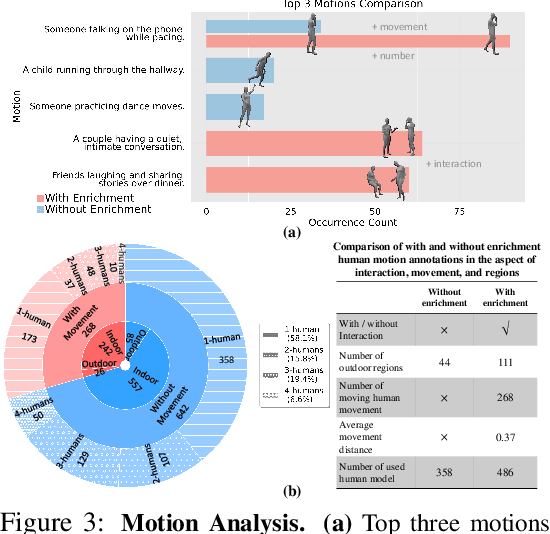

Vision-and-Language Navigation (VLN) systems often focus on either discrete (panoramic) or continuous (free-motion) paradigms alone, overlooking the complexities of human-populated, dynamic environments. We introduce a unified Human-Aware VLN (HA-VLN) benchmark that merges these paradigms under explicit social-awareness constraints. Our contributions include: 1. A standardized task definition that balances discrete-continuous navigation with personal-space requirements; 2. An enhanced human motion dataset (HAPS 2.0) and upgraded simulators capturing realistic multi-human interactions, outdoor contexts, and refined motion-language alignment; 3. Extensive benchmarking on 16,844 human-centric instructions, revealing how multi-human dynamics and partial observability pose substantial challenges for leading VLN agents; 4. Real-world robot tests validating sim-to-real transfer in crowded indoor spaces; and 5. A public leaderboard supporting transparent comparisons across discrete and continuous tasks. Empirical results show improved navigation success and fewer collisions when social context is integrated, underscoring the need for human-centric design. By releasing all datasets, simulators, agent code, and evaluation tools, we aim to advance safer, more capable, and socially responsible VLN research.
UCDR-Adapter: Exploring Adaptation of Pre-Trained Vision-Language Models for Universal Cross-Domain Retrieval
Dec 14, 2024



Universal Cross-Domain Retrieval (UCDR) retrieves relevant images from unseen domains and classes without semantic labels, ensuring robust generalization. Existing methods commonly employ prompt tuning with pre-trained vision-language models but are inherently limited by static prompts, reducing adaptability. We propose UCDR-Adapter, which enhances pre-trained models with adapters and dynamic prompt generation through a two-phase training strategy. First, Source Adapter Learning integrates class semantics with domain-specific visual knowledge using a Learnable Textual Semantic Template and optimizes Class and Domain Prompts via momentum updates and dual loss functions for robust alignment. Second, Target Prompt Generation creates dynamic prompts by attending to masked source prompts, enabling seamless adaptation to unseen domains and classes. Unlike prior approaches, UCDR-Adapter dynamically adapts to evolving data distributions, enhancing both flexibility and generalization. During inference, only the image branch and generated prompts are used, eliminating reliance on textual inputs for highly efficient retrieval. Extensive benchmark experiments show that UCDR-Adapter consistently outperforms ProS in most cases and other state-of-the-art methods on UCDR, U(c)CDR, and U(d)CDR settings.
MetaDesigner: Advancing Artistic Typography through AI-Driven, User-Centric, and Multilingual WordArt Synthesis
Jun 28, 2024
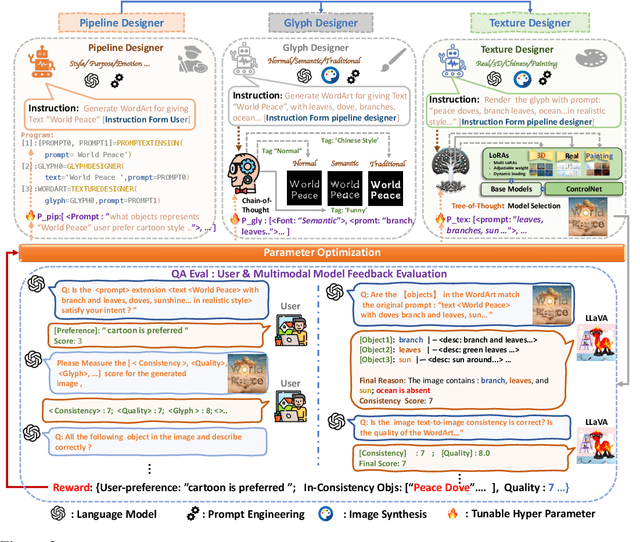
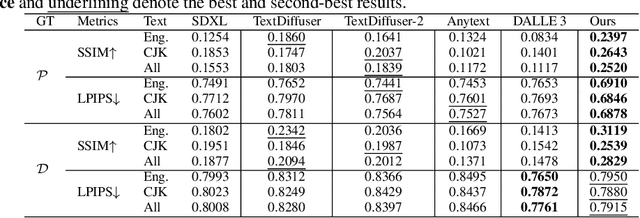
MetaDesigner revolutionizes artistic typography synthesis by leveraging the strengths of Large Language Models (LLMs) to drive a design paradigm centered around user engagement. At the core of this framework lies a multi-agent system comprising the Pipeline, Glyph, and Texture agents, which collectively enable the creation of customized WordArt, ranging from semantic enhancements to the imposition of complex textures. MetaDesigner incorporates a comprehensive feedback mechanism that harnesses insights from multimodal models and user evaluations to refine and enhance the design process iteratively. Through this feedback loop, the system adeptly tunes hyperparameters to align with user-defined stylistic and thematic preferences, generating WordArt that not only meets but exceeds user expectations of visual appeal and contextual relevance. Empirical validations highlight MetaDesigner's capability to effectively serve diverse WordArt applications, consistently producing aesthetically appealing and context-sensitive results.
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
Jun 17, 2024

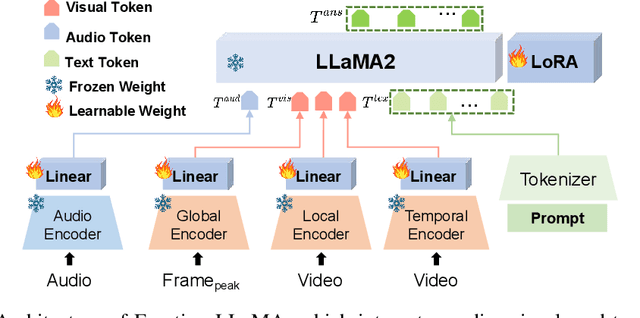

Accurate emotion perception is crucial for various applications, including human-computer interaction, education, and counseling. However, traditional single-modality approaches often fail to capture the complexity of real-world emotional expressions, which are inherently multimodal. Moreover, existing Multimodal Large Language Models (MLLMs) face challenges in integrating audio and recognizing subtle facial micro-expressions. To address this, we introduce the MERR dataset, containing 28,618 coarse-grained and 4,487 fine-grained annotated samples across diverse emotional categories. This dataset enables models to learn from varied scenarios and generalize to real-world applications. Furthermore, we propose Emotion-LLaMA, a model that seamlessly integrates audio, visual, and textual inputs through emotion-specific encoders. By aligning features into a shared space and employing a modified LLaMA model with instruction tuning, Emotion-LLaMA significantly enhances both emotional recognition and reasoning capabilities. Extensive evaluations show Emotion-LLaMA outperforms other MLLMs, achieving top scores in Clue Overlap (7.83) and Label Overlap (6.25) on EMER, an F1 score of 0.9036 on MER2023 challenge, and the highest UAR (45.59) and WAR (59.37) in zero-shot evaluations on DFEW dataset.
WordArt Designer API: User-Driven Artistic Typography Synthesis with Large Language Models on ModelScope
Jan 12, 2024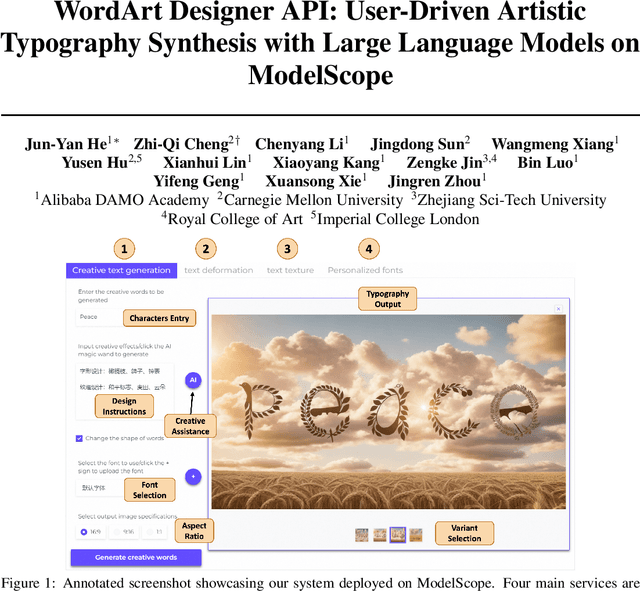


This paper introduces the WordArt Designer API, a novel framework for user-driven artistic typography synthesis utilizing Large Language Models (LLMs) on ModelScope. We address the challenge of simplifying artistic typography for non-professionals by offering a dynamic, adaptive, and computationally efficient alternative to traditional rigid templates. Our approach leverages the power of LLMs to understand and interpret user input, facilitating a more intuitive design process. We demonstrate through various case studies how users can articulate their aesthetic preferences and functional requirements, which the system then translates into unique and creative typographic designs. Our evaluations indicate significant improvements in user satisfaction, design flexibility, and creative expression over existing systems. The WordArt Designer API not only democratizes the art of typography but also opens up new possibilities for personalized digital communication and design.
Debunking Free Fusion Myth: Online Multi-view Anomaly Detection with Disentangled Product-of-Experts Modeling
Oct 31, 2023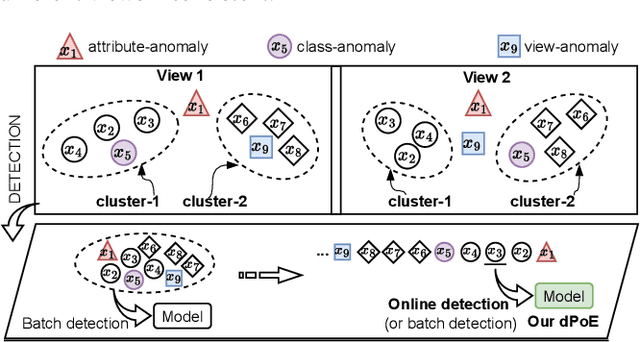
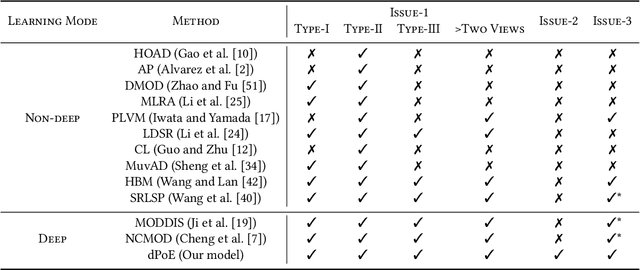
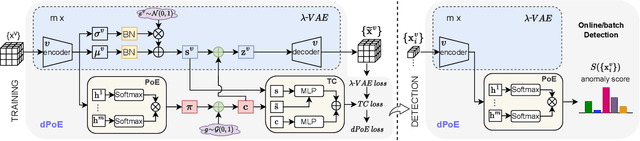
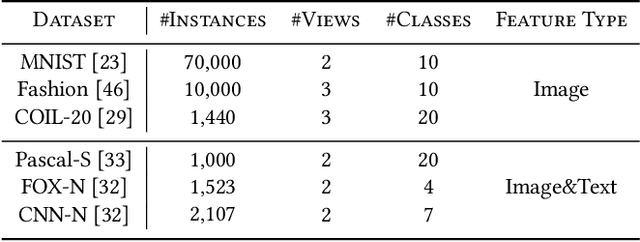
Multi-view or even multi-modal data is appealing yet challenging for real-world applications. Detecting anomalies in multi-view data is a prominent recent research topic. However, most of the existing methods 1) are only suitable for two views or type-specific anomalies, 2) suffer from the issue of fusion disentanglement, and 3) do not support online detection after model deployment. To address these challenges, our main ideas in this paper are three-fold: multi-view learning, disentangled representation learning, and generative model. To this end, we propose dPoE, a novel multi-view variational autoencoder model that involves (1) a Product-of-Experts (PoE) layer in tackling multi-view data, (2) a Total Correction (TC) discriminator in disentangling view-common and view-specific representations, and (3) a joint loss function in wrapping up all components. In addition, we devise theoretical information bounds to control both view-common and view-specific representations. Extensive experiments on six real-world datasets markedly demonstrate that the proposed dPoE outperforms baselines.
WordArt Designer: User-Driven Artistic Typography Synthesis using Large Language Models
Oct 20, 2023



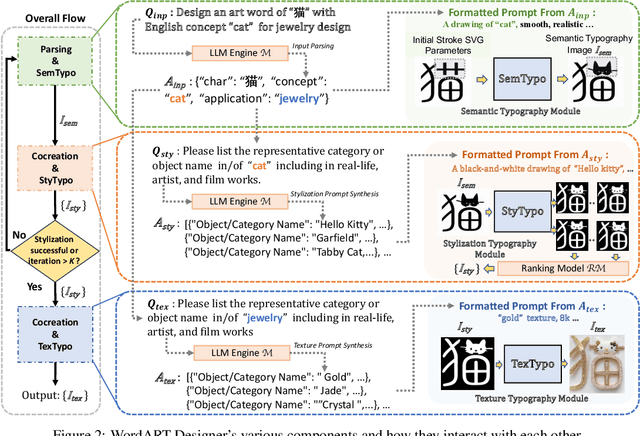
This paper introduces "WordArt Designer", a user-driven framework for artistic typography synthesis, relying on Large Language Models (LLM). The system incorporates four key modules: the "LLM Engine", "SemTypo", "StyTypo", and "TexTypo" modules. 1) The "LLM Engine", empowered by LLM (e.g., GPT-3.5-turbo), interprets user inputs and generates actionable prompts for the other modules, thereby transforming abstract concepts into tangible designs. 2) The "SemTypo module" optimizes font designs using semantic concepts, striking a balance between artistic transformation and readability. 3) Building on the semantic layout provided by the "SemTypo module", the "StyTypo module" creates smooth, refined images. 4) The "TexTypo module" further enhances the design's aesthetics through texture rendering, enabling the generation of inventive textured fonts. Notably, "WordArt Designer" highlights the fusion of generative AI with artistic typography. Experience its capabilities on ModelScope: https://www.modelscope.cn/studios/WordArt/WordArt.
KeyPosS: Plug-and-Play Facial Landmark Detection through GPS-Inspired True-Range Multilateration
May 25, 2023



In the realm of facial analysis, accurate landmark detection is crucial for various applications, ranging from face recognition and expression analysis to animation. Conventional heatmap or coordinate regression-based techniques, however, often face challenges in terms of computational burden and quantization errors. To address these issues, we present the KeyPoint Positioning System (KeyPosS), a groundbreaking facial landmark detection framework that stands out from existing methods. For the first time, KeyPosS employs the True-range Multilateration algorithm, a technique originally used in GPS systems, to achieve rapid and precise facial landmark detection without relying on computationally intensive regression approaches. The framework utilizes a fully convolutional network to predict a distance map, which computes the distance between a Point of Interest (POI) and multiple anchor points. These anchor points are ingeniously harnessed to triangulate the POI's position through the True-range Multilateration algorithm. Notably, the plug-and-play nature of KeyPosS enables seamless integration into any decoding stage, ensuring a versatile and adaptable solution. We conducted a thorough evaluation of KeyPosS's performance by benchmarking it against state-of-the-art models on four different datasets. The results show that KeyPosS substantially outperforms leading methods in low-resolution settings while requiring a minimal time overhead. The code is available at https://github.com/zhiqic/KeyPosS.