 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebunking Free Fusion Myth: Online Multi-view Anomaly Detection with Disentangled Product-of-Experts Modeling
Paper and Code
Oct 31, 2023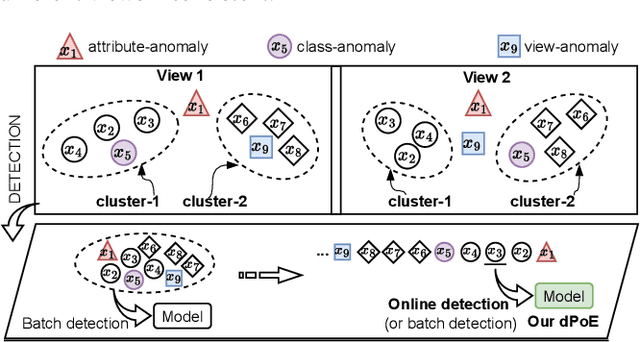
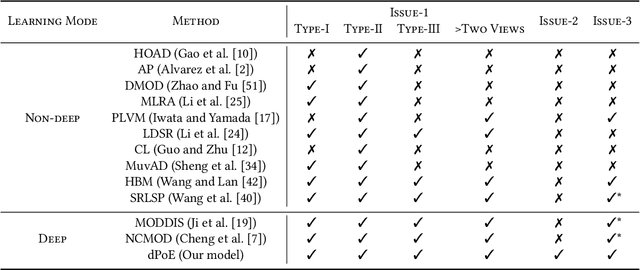
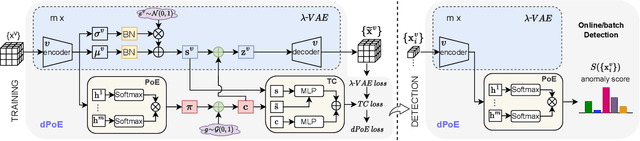
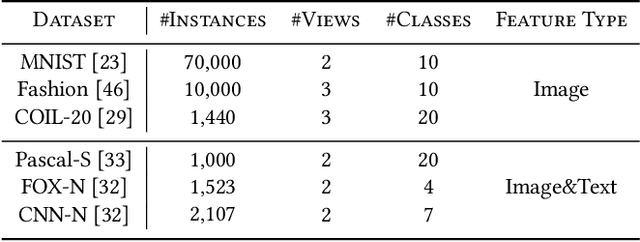
Multi-view or even multi-modal data is appealing yet challenging for real-world applications. Detecting anomalies in multi-view data is a prominent recent research topic. However, most of the existing methods 1) are only suitable for two views or type-specific anomalies, 2) suffer from the issue of fusion disentanglement, and 3) do not support online detection after model deployment. To address these challenges, our main ideas in this paper are three-fold: multi-view learning, disentangled representation learning, and generative model. To this end, we propose dPoE, a novel multi-view variational autoencoder model that involves (1) a Product-of-Experts (PoE) layer in tackling multi-view data, (2) a Total Correction (TC) discriminator in disentangling view-common and view-specific representations, and (3) a joint loss function in wrapping up all components. In addition, we devise theoretical information bounds to control both view-common and view-specific representations. Extensive experiments on six real-world datasets markedly demonstrate that the proposed dPoE outperforms baselines.