 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGI-1: Autoregressive Video Generation at Scale
May 19, 2025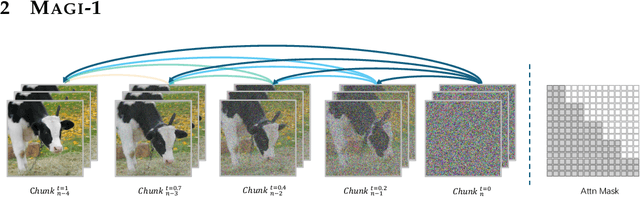
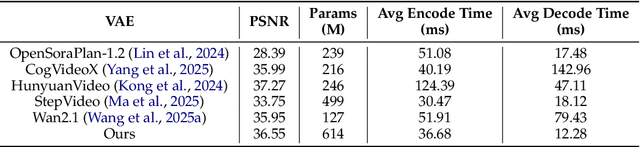
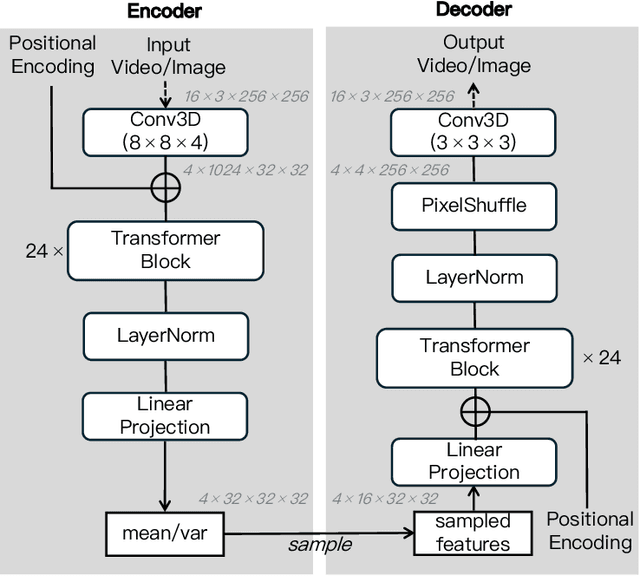
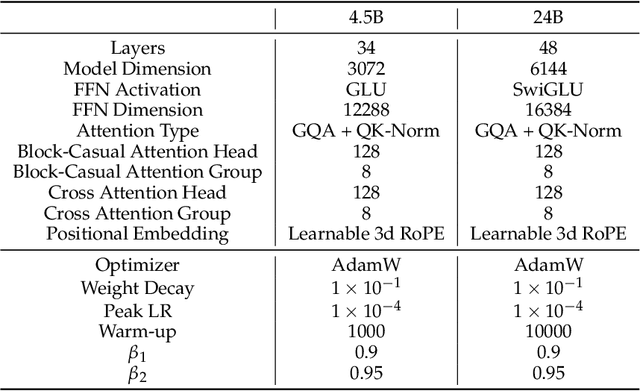
We present MAGI-1, a world model that generates videos by autoregressively predicting a sequence of video chunks, defined as fixed-length segments of consecutive frames. Trained to denoise per-chunk noise that increases monotonically over time, MAGI-1 enables causal temporal modeling and naturally supports streaming generation. It achieves strong performance on image-to-video (I2V) tasks conditioned on text instructions, providing high temporal consistency and scalability, which are made possible by several algorithmic innovations and a dedicated infrastructure stack. MAGI-1 facilitates controllable generation via chunk-wise prompting and supports real-time, memory-efficient deployment by maintaining constant peak inference cost, regardless of video length. The largest variant of MAGI-1 comprises 24 billion parameters and supports context lengths of up to 4 million tokens, demonstrating the scalability and robustness of our approach. The code and models are available at https://github.com/SandAI-org/MAGI-1 and https://github.com/SandAI-org/MagiAttention. The product can be accessed at https://sand.ai.
AtomoVideo: High Fidelity Image-to-Video Generation
Mar 05, 2024



Recently, video generation has achieved significant rapid development based on superior text-to-image generation techniques. In this work, we propose a high fidelity framework for image-to-video generation, named AtomoVideo. Based on multi-granularity image injection, we achieve higher fidelity of the generated video to the given image. In addition, thanks to high quality datasets and training strategies, we achieve greater motion intensity while maintaining superior temporal consistency and stability. Our architecture extends flexibly to the video frame prediction task, enabling long sequence prediction through iterative generation. Furthermore, due to the design of adapter training, our approach can be well combined with existing personalized models and controllable modules. By quantitatively and qualitatively evaluation, AtomoVideo achieves superior results compared to popular methods, more examples can be found on our project website: https://atomo-video.github.io/.
WordArt Designer API: User-Driven Artistic Typography Synthesis with Large Language Models on ModelScope
Jan 12, 2024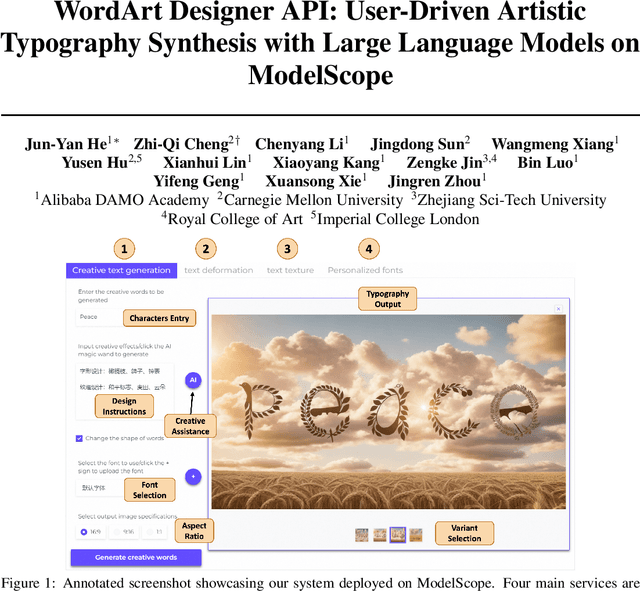


This paper introduces the WordArt Designer API, a novel framework for user-driven artistic typography synthesis utilizing Large Language Models (LLMs) on ModelScope. We address the challenge of simplifying artistic typography for non-professionals by offering a dynamic, adaptive, and computationally efficient alternative to traditional rigid templates. Our approach leverages the power of LLMs to understand and interpret user input, facilitating a more intuitive design process. We demonstrate through various case studies how users can articulate their aesthetic preferences and functional requirements, which the system then translates into unique and creative typographic designs. Our evaluations indicate significant improvements in user satisfaction, design flexibility, and creative expression over existing systems. The WordArt Designer API not only democratizes the art of typography but also opens up new possibilities for personalized digital communication and design.
DreaMoving: A Human Video Generation Framework based on Diffusion Models
Dec 11, 2023



In this paper, we present DreaMoving, a diffusion-based controllable video generation framework to produce high-quality customized human videos. Specifically, given target identity and posture sequences, DreaMoving can generate a video of the target identity moving or dancing anywhere driven by the posture sequences. To this end, we propose a Video ControlNet for motion-controlling and a Content Guider for identity preserving. The proposed model is easy to use and can be adapted to most stylized diffusion models to generate diverse results. The project page is available at https://dreamoving.github.io/dreamoving
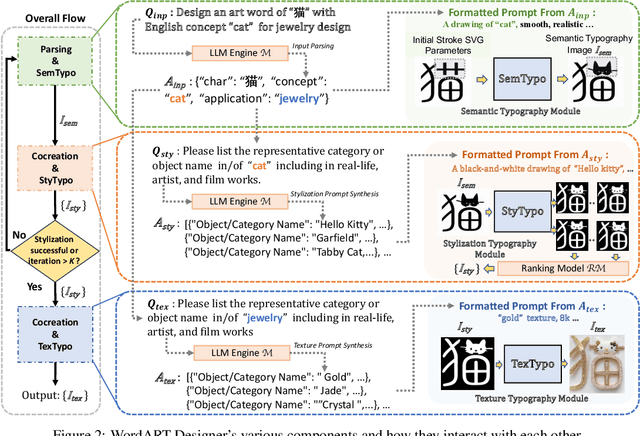
WordArt Designer: User-Driven Artistic Typography Synthesis using Large Language Models
Oct 20, 2023



This paper introduces "WordArt Designer", a user-driven framework for artistic typography synthesis, relying on Large Language Models (LLM). The system incorporates four key modules: the "LLM Engine", "SemTypo", "StyTypo", and "TexTypo" modules. 1) The "LLM Engine", empowered by LLM (e.g., GPT-3.5-turbo), interprets user inputs and generates actionable prompts for the other modules, thereby transforming abstract concepts into tangible designs. 2) The "SemTypo module" optimizes font designs using semantic concepts, striking a balance between artistic transformation and readability. 3) Building on the semantic layout provided by the "SemTypo module", the "StyTypo module" creates smooth, refined images. 4) The "TexTypo module" further enhances the design's aesthetics through texture rendering, enabling the generation of inventive textured fonts. Notably, "WordArt Designer" highlights the fusion of generative AI with artistic typography. Experience its capabilities on ModelScope: https://www.modelscope.cn/studios/WordArt/WordArt.
RSFNet: A White-Box Image Retouching Approach using Region-Specific Color Filters
Mar 15, 2023

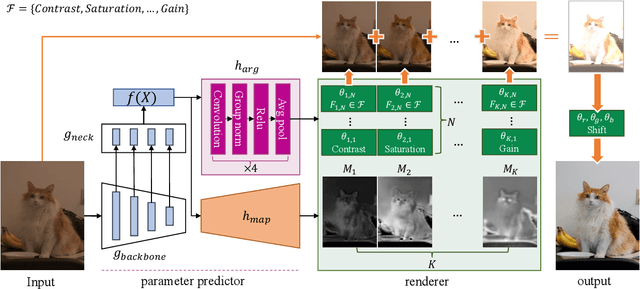

Retouching images is an essential aspect of enhancing the visual appeal of photos. Although users often share common aesthetic preferences, their retouching methods may vary based on their individual preferences. Therefore, there is a need for white-box approaches that produce satisfying results and enable users to conveniently edit their images simultaneously. Recent white-box retouching methods rely on cascaded global filters that provide image-level filter arguments but cannot perform fine-grained retouching. In contrast, colorists typically use a divide-and-conquer approach, performing a series of region-specific fine-grained enhancements when using traditional tools like Davinci Resolve. We draw on this insight to develop a white-box framework for photo retouching using parallel region-specific filters, called RSFNet. Our model generates filter arguments (e.g., saturation, contrast, hue) and attention maps of regions for each filter simultaneously. Instead of cascading filters, RSFNet employs linear summations of filters, allowing for a more diverse range of filter classes that can be trained more easily. Our experiments demonstrate that RSFNet achieves state-of-the-art results, offering satisfying aesthetic appeal and greater user convenience for editable white-box retouching.
DDColor: Towards Photo-Realistic and Semantic-Aware Image Colorization via Dual Decoders
Dec 23, 2022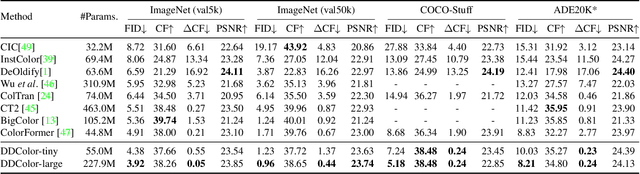



Automatic image colorization is a particularly challenging problem. Due to the high illness of the problem and multi-modal uncertainty, directly training a deep neural network usually leads to incorrect semantic colors and low color richness. Existing transformer-based methods can deliver better results but highly depend on hand-crafted dataset-level empirical distribution priors. In this work, we propose DDColor, a new end-to-end method with dual decoders, for image colorization. More specifically, we design a multi-scale image decoder and a transformer-based color decoder. The former manages to restore the spatial resolution of the image, while the latter establishes the correlation between semantic representations and color queries via cross-attention. The two decoders incorporate to learn semantic-aware color embedding by leveraging the multi-scale visual features. With the help of these two decoders, our method succeeds in producing semantically consistent and visually plausible colorization results without any additional priors. In addition, a simple but effective colorfulness loss is introduced to further improve the color richness of generated results. Our extensive experiments demonstrate that the proposed DDColor achieves significantly superior performance to existing state-of-the-art works both quantitatively and qualitatively. Codes will be made publicly available at https://github.com/piddnad/DDColor.