 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefold: Refining Protein Inverse Folding with Efficient Structural Matching and Fusion
Mar 15, 2026Protein inverse folding aims to design an amino acid sequence that will fold into a given backbone structure, serving as a central task in protein design. Two main paradigms have been widely explored. Template-based methods exploit database-derived structural priors and can achieve high local precision when close structural neighbors are available, but their dependence on database coverage and match quality often degrades performance on out-of-distribution (OOD) targets. Deep learning approaches, in contrast, learn general structure-to-sequence regularities and usually generalize better to new backbones. However, they struggle to capture fine-grained local structure, which can cause uncertain residue predictions and missed local motifs in ambiguous regions. We introduce Refold, a novel framework that synergistically integrates the strengths of database-derived structural priors and deep learning prediction to enhance inverse folding. Refold obtains structural priors from matched neighbors and fuses them with model predictions to refine residue probabilities. In practice, low-quality neighbors can introduce noise, potentially degrading model performance. We address this issue with a Dynamic Utility Gate that controls prior injection and falls back to the base prediction when the priors are untrustworthy. Comprehensive evaluations on standard benchmarks demonstrate that Refold achieves state-of-the-art native sequence recovery of 0.63 on both CATH 4.2 and CATH 4.3. Also, analysis indicates that Refold delivers larger gains on high-uncertainty regions, reflecting the complementarity between structural priors and deep learning predictions.
Identity-Preserving Image-to-Video Generation via Reward-Guided Optimization
Oct 16, 2025Recent advances in image-to-video (I2V) generation have achieved remarkable progress in synthesizing high-quality, temporally coherent videos from static images. Among all the applications of I2V, human-centric video generation includes a large portion. However, existing I2V models encounter difficulties in maintaining identity consistency between the input human image and the generated video, especially when the person in the video exhibits significant expression changes and movements. This issue becomes critical when the human face occupies merely a small fraction of the image. Since humans are highly sensitive to identity variations, this poses a critical yet under-explored challenge in I2V generation. In this paper, we propose Identity-Preserving Reward-guided Optimization (IPRO), a novel video diffusion framework based on reinforcement learning to enhance identity preservation. Instead of introducing auxiliary modules or altering model architectures, our approach introduces a direct and effective tuning algorithm that optimizes diffusion models using a face identity scorer. To improve performance and accelerate convergence, our method backpropagates the reward signal through the last steps of the sampling chain, enabling richer gradient feedback. We also propose a novel facial scoring mechanism that treats faces in ground-truth videos as facial feature pools, providing multi-angle facial information to enhance generalization. A KL-divergence regularization is further incorporated to stabilize training and prevent overfitting to the reward signal. Extensive experiments on Wan 2.2 I2V model and our in-house I2V model demonstrate the effectiveness of our method. Our project and code are available at \href{https://ipro-alimama.github.io/}{https://ipro-alimama.github.io/}.
STG: Spatiotemporal Graph Neural Network with Fusion and Spatiotemporal Decoupling Learning for Prognostic Prediction of Colorectal Cancer Liver Metastasis
May 06, 2025We propose a multimodal spatiotemporal graph neural network (STG) framework to predict colorectal cancer liver metastasis (CRLM) progression. Current clinical models do not effectively integrate the tumor's spatial heterogeneity, dynamic evolution, and complex multimodal data relationships, limiting their predictive accuracy. Our STG framework combines preoperative CT imaging and clinical data into a heterogeneous graph structure, enabling joint modeling of tumor distribution and temporal evolution through spatial topology and cross-modal edges. The framework uses GraphSAGE to aggregate spatiotemporal neighborhood information and leverages supervised and contrastive learning strategies to enhance the model's ability to capture temporal features and improve robustness. A lightweight version of the model reduces parameter count by 78.55%, maintaining near-state-of-the-art performance. The model jointly optimizes recurrence risk regression and survival analysis tasks, with contrastive loss improving feature representational discriminability and cross-modal consistency. Experimental results on the MSKCC CRLM dataset show a time-adjacent accuracy of 85% and a mean absolute error of 1.1005, significantly outperforming existing methods. The innovative heterogeneous graph construction and spatiotemporal decoupling mechanism effectively uncover the associations between dynamic tumor microenvironment changes and prognosis, providing reliable quantitative support for personalized treatment decisions.
PupiNet: Seamless OCT-OCTA Interconversion Through Wavelet-Driven and Multi-Scale Attention Mechanisms
Mar 31, 2025



Optical Coherence Tomography (OCT) and Optical Coherence Tomography Angiography (OCTA) are key diagnostic tools for clinical evaluation and management of retinal diseases. Compared to traditional OCT, OCTA provides richer microvascular information, but its acquisition requires specialized sensors and high-cost equipment, creating significant challenges for the clinical deployment of hardware-dependent OCTA imaging methods. Given the technical complexity of OCTA image acquisition and potential mechanical artifacts, this study proposes a bidirectional image conversion framework called PupiNet, which accurately achieves bidirectional transformation between 3D OCT and 3D OCTA. The generator module of this framework innovatively integrates wavelet transformation and multi-scale attention mechanisms, significantly enhancing image conversion quality. Meanwhile, an Adaptive Discriminator Augmentation (ADA) module has been incorporated into the discriminator to optimize model training stability and convergence efficiency. To ensure clinical accuracy of vascular structures in the converted images, we designed a Vessel Structure Matcher (VSM) supervision module, achieving precise matching of vascular morphology between generated images and target images. Additionally, the Hierarchical Feature Calibration (HFC) module further guarantees high consistency of texture details between generated images and target images across different depth levels. To rigorously validate the clinical effectiveness of the proposed method, we conducted a comprehensive evaluation on a paired OCT-OCTA image dataset containing 300 eyes with various retinal pathologies. Experimental results demonstrate that PupiNet not only reliably achieves high-quality bidirectional transformation between the two modalities but also shows significant advantages in image fidelity, vessel structure preservation, and clinical usability.
4D-ACFNet: A 4D Attention Mechanism-Based Prognostic Framework for Colorectal Cancer Liver Metastasis Integrating Multimodal Spatiotemporal Features
Mar 12, 2025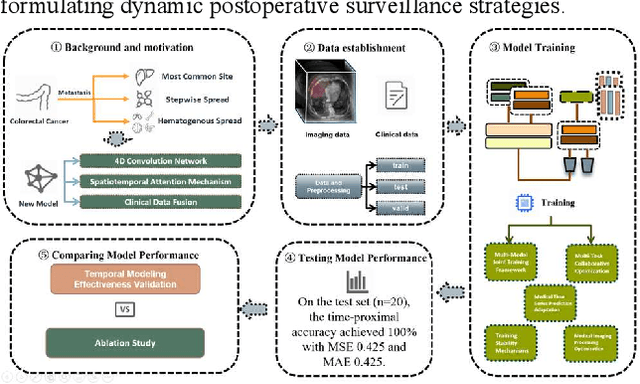

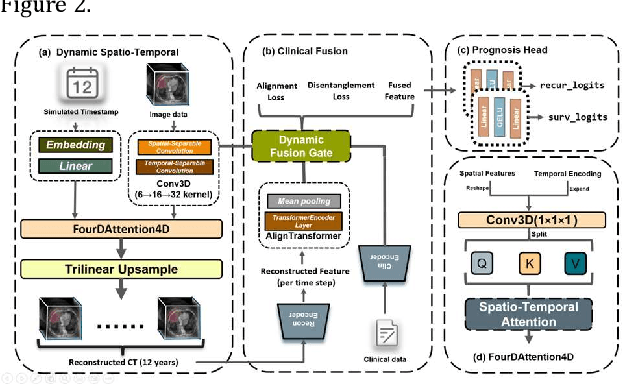

Postoperative prognostic prediction for colorectal cancer liver metastasis (CRLM) remains challenging due to tumor heterogeneity, dynamic evolution of the hepatic microenvironment, and insufficient multimodal data fusion. To address these issues, we propose 4D-ACFNet, the first framework that synergistically integrates lightweight spatiotemporal modeling, cross-modal dynamic calibration, and personalized temporal prediction within a unified architecture. Specifically, it incorporates a novel 4D spatiotemporal attention mechanism, which employs spatiotemporal separable convolution (reducing parameter count by 41%) and virtual timestamp encoding to model the interannual evolution patterns of postoperative dynamic processes, such as liver regeneration and steatosis. For cross-modal feature alignment, Transformer layers are integrated to jointly optimize modality alignment loss and disentanglement loss, effectively suppressing scale mismatch and redundant interference in clinical-imaging data. Additionally, we design a dynamic prognostic decision module that generates personalized interannual recurrence risk heatmaps through temporal upsampling and a gated classification head, overcoming the limitations of traditional methods in temporal dynamic modeling and cross-modal alignment. Experiments on 197 CRLM patients demonstrate that the model achieves 100% temporal adjacency accuracy (TAA), with performance significantly surpassing existing approaches. This study establishes the first spatiotemporal modeling paradigm for postoperative dynamic monitoring of CRLM. The proposed framework can be extended to prognostic analysis of multi-cancer metastases, advancing precision surgery from "spatial resection" to "spatiotemporal cure."
RURANET++: An Unsupervised Learning Method for Diabetic Macular Edema Based on SCSE Attention Mechanisms and Dynamic Multi-Projection Head Clustering
Feb 27, 2025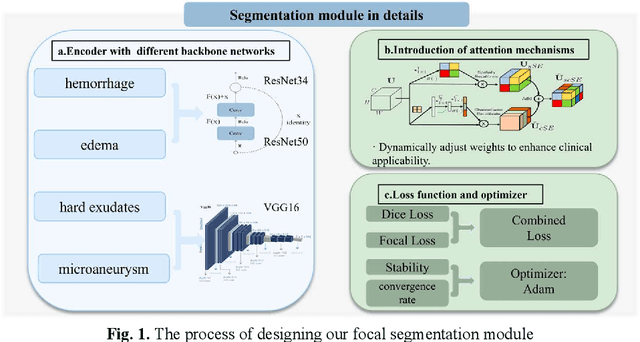
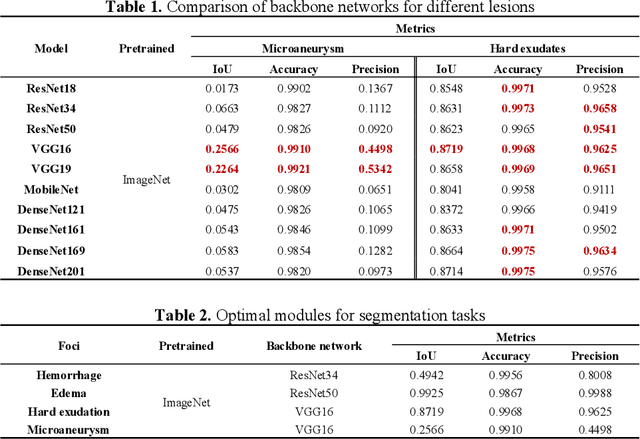
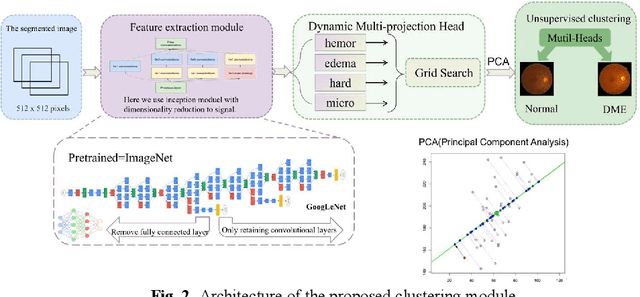
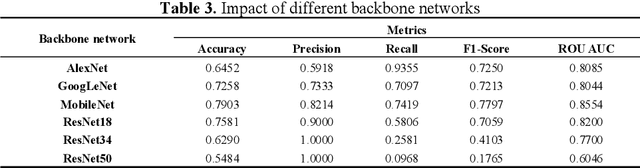
Diabetic Macular Edema (DME), a prevalent complication among diabetic patients, constitutes a major cause of visual impairment and blindness. Although deep learning has achieved remarkable progress in medical image analysis, traditional DME diagnosis still relies on extensive annotated data and subjective ophthalmologist assessments, limiting practical applications. To address this, we present RURANET++, an unsupervised learning-based automated DME diagnostic system. This framework incorporates an optimized U-Net architecture with embedded Spatial and Channel Squeeze & Excitation (SCSE) attention mechanisms to enhance lesion feature extraction. During feature processing, a pre-trained GoogLeNet model extracts deep features from retinal images, followed by PCA-based dimensionality reduction to 50 dimensions for computational efficiency. Notably, we introduce a novel clustering algorithm employing multi-projection heads to explicitly control cluster diversity while dynamically adjusting similarity thresholds, thereby optimizing intra-class consistency and inter-class discrimination. Experimental results demonstrate superior performance across multiple metrics, achieving maximum accuracy (0.8411), precision (0.8593), recall (0.8411), and F1-score (0.8390), with exceptional clustering quality. This work provides an efficient unsupervised solution for DME diagnosis with significant clinical implications.
AtomoVideo: High Fidelity Image-to-Video Generation
Mar 05, 2024



Recently, video generation has achieved significant rapid development based on superior text-to-image generation techniques. In this work, we propose a high fidelity framework for image-to-video generation, named AtomoVideo. Based on multi-granularity image injection, we achieve higher fidelity of the generated video to the given image. In addition, thanks to high quality datasets and training strategies, we achieve greater motion intensity while maintaining superior temporal consistency and stability. Our architecture extends flexibly to the video frame prediction task, enabling long sequence prediction through iterative generation. Furthermore, due to the design of adapter training, our approach can be well combined with existing personalized models and controllable modules. By quantitatively and qualitatively evaluation, AtomoVideo achieves superior results compared to popular methods, more examples can be found on our project website: https://atomo-video.github.io/.
Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation
Mar 05, 2024



Image-to-video (I2V) generation tasks always suffer from keeping high fidelity in the open domains. Traditional image animation techniques primarily focus on specific domains such as faces or human poses, making them difficult to generalize to open domains. Several recent I2V frameworks based on diffusion models can generate dynamic content for open domain images but fail to maintain fidelity. We found that two main factors of low fidelity are the loss of image details and the noise prediction biases during the denoising process. To this end, we propose an effective method that can be applied to mainstream video diffusion models. This method achieves high fidelity based on supplementing more precise image information and noise rectification. Specifically, given a specified image, our method first adds noise to the input image latent to keep more details, then denoises the noisy latent with proper rectification to alleviate the noise prediction biases. Our method is tuning-free and plug-and-play. The experimental results demonstrate the effectiveness of our approach in improving the fidelity of generated videos. For more image-to-video generated results, please refer to the project website: https://noise-rectification.github.io.