 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin
Nov 08, 2025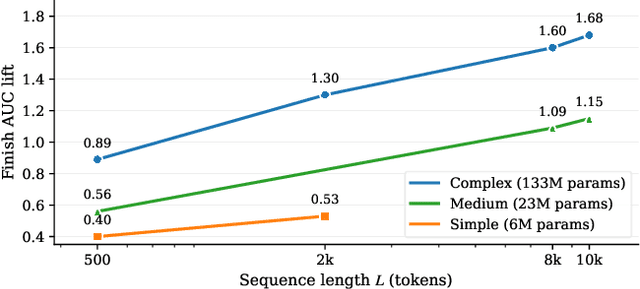
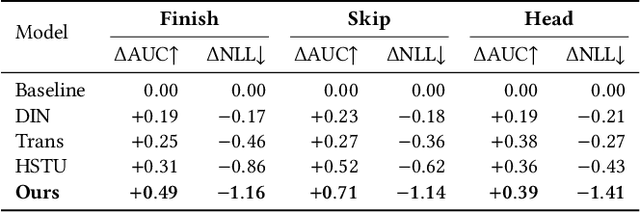
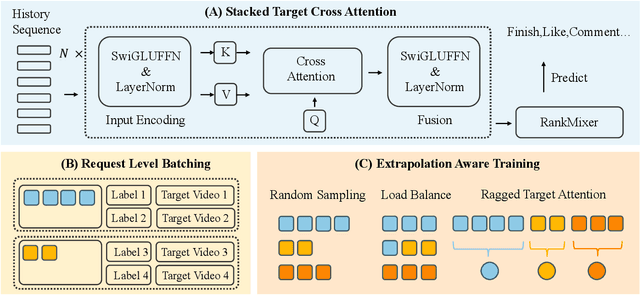

Short-video recommenders such as Douyin must exploit extremely long user histories without breaking latency or cost budgets. We present an end-to-end system that scales long-sequence modeling to 10k-length histories in production. First, we introduce Stacked Target-to-History Cross Attention (STCA), which replaces history self-attention with stacked cross-attention from the target to the history, reducing complexity from quadratic to linear in sequence length and enabling efficient end-to-end training. Second, we propose Request Level Batching (RLB), a user-centric batching scheme that aggregates multiple targets for the same user/request to share the user-side encoding, substantially lowering sequence-related storage, communication, and compute without changing the learning objective. Third, we design a length-extrapolative training strategy -- train on shorter windows, infer on much longer ones -- so the model generalizes to 10k histories without additional training cost. Across offline and online experiments, we observe predictable, monotonic gains as we scale history length and model capacity, mirroring the scaling law behavior observed in large language models. Deployed at full traffic on Douyin, our system delivers significant improvements on key engagement metrics while meeting production latency, demonstrating a practical path to scaling end-to-end long-sequence recommendation to the 10k regime.
DiffuEraser: A Diffusion Model for Video Inpainting
Jan 17, 2025Recent video inpainting algorithms integrate flow-based pixel propagation with transformer-based generation to leverage optical flow for restoring textures and objects using information from neighboring frames, while completing masked regions through visual Transformers. However, these approaches often encounter blurring and temporal inconsistencies when dealing with large masks, highlighting the need for models with enhanced generative capabilities. Recently, diffusion models have emerged as a prominent technique in image and video generation due to their impressive performance. In this paper, we introduce DiffuEraser, a video inpainting model based on stable diffusion, designed to fill masked regions with greater details and more coherent structures. We incorporate prior information to provide initialization and weak conditioning,which helps mitigate noisy artifacts and suppress hallucinations. Additionally, to improve temporal consistency during long-sequence inference, we expand the temporal receptive fields of both the prior model and DiffuEraser, and further enhance consistency by leveraging the temporal smoothing property of Video Diffusion Models. Experimental results demonstrate that our proposed method outperforms state-of-the-art techniques in both content completeness and temporal consistency while maintaining acceptable efficiency.
DreaMoving: A Human Video Generation Framework based on Diffusion Models
Dec 11, 2023



In this paper, we present DreaMoving, a diffusion-based controllable video generation framework to produce high-quality customized human videos. Specifically, given target identity and posture sequences, DreaMoving can generate a video of the target identity moving or dancing anywhere driven by the posture sequences. To this end, we propose a Video ControlNet for motion-controlling and a Content Guider for identity preserving. The proposed model is easy to use and can be adapted to most stylized diffusion models to generate diverse results. The project page is available at https://dreamoving.github.io/dreamoving