 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShortFT: Diffusion Model Alignment via Shortcut-based Fine-Tuning
Jul 30, 2025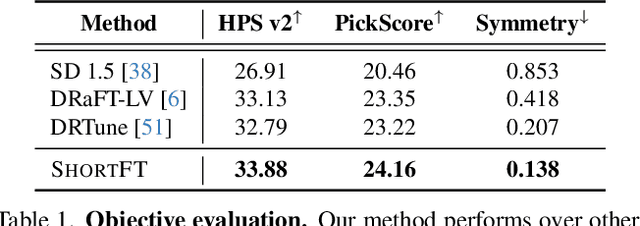


Backpropagation-based approaches aim to align diffusion models with reward functions through end-to-end backpropagation of the reward gradient within the denoising chain, offering a promising perspective. However, due to the computational costs and the risk of gradient explosion associated with the lengthy denoising chain, existing approaches struggle to achieve complete gradient backpropagation, leading to suboptimal results. In this paper, we introduce Shortcut-based Fine-Tuning (ShortFT), an efficient fine-tuning strategy that utilizes the shorter denoising chain. More specifically, we employ the recently researched trajectory-preserving few-step diffusion model, which enables a shortcut over the original denoising chain, and construct a shortcut-based denoising chain of shorter length. The optimization on this chain notably enhances the efficiency and effectiveness of fine-tuning the foundational model. Our method has been rigorously tested and can be effectively applied to various reward functions, significantly improving alignment performance and surpassing state-of-the-art alternatives.
Leveraging Predicate and Triplet Learning for Scene Graph Generation
Jun 04, 2024

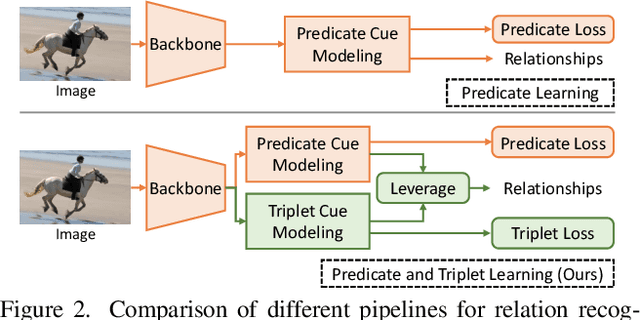

Scene Graph Generation (SGG) aims to identify entities and predict the relationship triplets \textit{\textless subject, predicate, object\textgreater } in visual scenes. Given the prevalence of large visual variations of subject-object pairs even in the same predicate, it can be quite challenging to model and refine predicate representations directly across such pairs, which is however a common strategy adopted by most existing SGG methods. We observe that visual variations within the identical triplet are relatively small and certain relation cues are shared in the same type of triplet, which can potentially facilitate the relation learning in SGG. Moreover, for the long-tail problem widely studied in SGG task, it is also crucial to deal with the limited types and quantity of triplets in tail predicates. Accordingly, in this paper, we propose a Dual-granularity Relation Modeling (DRM) network to leverage fine-grained triplet cues besides the coarse-grained predicate ones. DRM utilizes contexts and semantics of predicate and triplet with Dual-granularity Constraints, generating compact and balanced representations from two perspectives to facilitate relation recognition. Furthermore, a Dual-granularity Knowledge Transfer (DKT) strategy is introduced to transfer variation from head predicates/triplets to tail ones, aiming to enrich the pattern diversity of tail classes to alleviate the long-tail problem. Extensive experiments demonstrate the effectiveness of our method, which establishes new state-of-the-art performance on Visual Genome, Open Image, and GQA datasets. Our code is available at \url{https://github.com/jkli1998/DRM}
I4VGen: Image as Stepping Stone for Text-to-Video Generation
Jun 04, 2024



Text-to-video generation has lagged behind text-to-image synthesis in quality and diversity due to the complexity of spatio-temporal modeling and limited video-text datasets. This paper presents I4VGen, a training-free and plug-and-play video diffusion inference framework, which enhances text-to-video generation by leveraging robust image techniques. Specifically, following text-to-image-to-video, I4VGen decomposes the text-to-video generation into two stages: anchor image synthesis and anchor image-guided video synthesis. Correspondingly, a well-designed generation-selection pipeline is employed to achieve visually-realistic and semantically-faithful anchor image, and an innovative Noise-Invariant Video Score Distillation Sampling is incorporated to animate the image to a dynamic video, followed by a video regeneration process to refine the video. This inference strategy effectively mitigates the prevalent issue of non-zero terminal signal-to-noise ratio. Extensive evaluations show that I4VGen not only produces videos with higher visual realism and textual fidelity but also integrates seamlessly into existing image-to-video diffusion models, thereby improving overall video quality.
Disentangling Foreground and Background Motion for Enhanced Realism in Human Video Generation
May 28, 2024



Recent advancements in human video synthesis have enabled the generation of high-quality videos through the application of stable diffusion models. However, existing methods predominantly concentrate on animating solely the human element (the foreground) guided by pose information, while leaving the background entirely static. Contrary to this, in authentic, high-quality videos, backgrounds often dynamically adjust in harmony with foreground movements, eschewing stagnancy. We introduce a technique that concurrently learns both foreground and background dynamics by segregating their movements using distinct motion representations. Human figures are animated leveraging pose-based motion, capturing intricate actions. Conversely, for backgrounds, we employ sparse tracking points to model motion, thereby reflecting the natural interaction between foreground activity and environmental changes. Training on real-world videos enhanced with this innovative motion depiction approach, our model generates videos exhibiting coherent movement in both foreground subjects and their surrounding contexts. To further extend video generation to longer sequences without accumulating errors, we adopt a clip-by-clip generation strategy, introducing global features at each step. To ensure seamless continuity across these segments, we ingeniously link the final frame of a produced clip with input noise to spawn the succeeding one, maintaining narrative flow. Throughout the sequential generation process, we infuse the feature representation of the initial reference image into the network, effectively curtailing any cumulative color inconsistencies that may otherwise arise. Empirical evaluations attest to the superiority of our method in producing videos that exhibit harmonious interplay between foreground actions and responsive background dynamics, surpassing prior methodologies in this regard.
InitNO: Boosting Text-to-Image Diffusion Models via Initial Noise Optimization
Apr 06, 2024



Recent strides in the development of diffusion models, exemplified by advancements such as Stable Diffusion, have underscored their remarkable prowess in generating visually compelling images. However, the imperative of achieving a seamless alignment between the generated image and the provided prompt persists as a formidable challenge. This paper traces the root of these difficulties to invalid initial noise, and proposes a solution in the form of Initial Noise Optimization (InitNO), a paradigm that refines this noise. Considering text prompts, not all random noises are effective in synthesizing semantically-faithful images. We design the cross-attention response score and the self-attention conflict score to evaluate the initial noise, bifurcating the initial latent space into valid and invalid sectors. A strategically crafted noise optimization pipeline is developed to guide the initial noise towards valid regions. Our method, validated through rigorous experimentation, shows a commendable proficiency in generating images in strict accordance with text prompts. Our code is available at https://github.com/xiefan-guo/initno.
DreaMoving: A Human Video Generation Framework based on Diffusion Models
Dec 11, 2023



In this paper, we present DreaMoving, a diffusion-based controllable video generation framework to produce high-quality customized human videos. Specifically, given target identity and posture sequences, DreaMoving can generate a video of the target identity moving or dancing anywhere driven by the posture sequences. To this end, we propose a Video ControlNet for motion-controlling and a Content Guider for identity preserving. The proposed model is easy to use and can be adapted to most stylized diffusion models to generate diverse results. The project page is available at https://dreamoving.github.io/dreamoving
Image Inpainting via Conditional Texture and Structure Dual Generation
Aug 22, 2021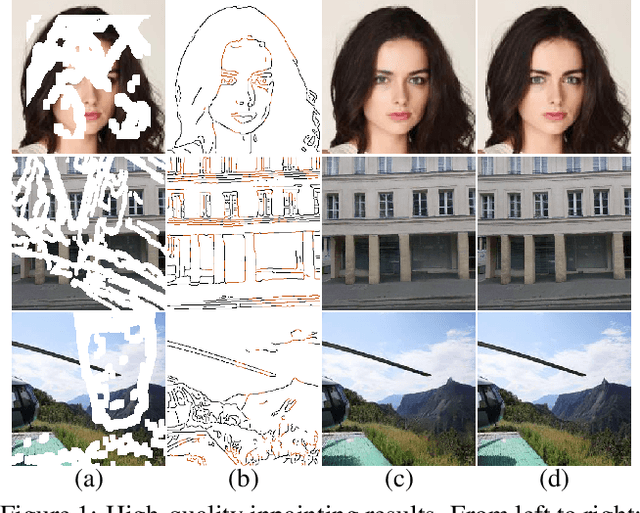
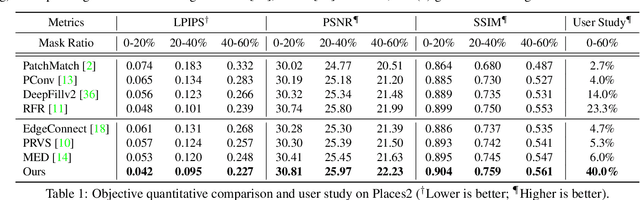

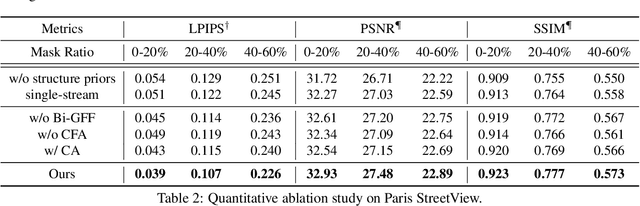
Deep generative approaches have recently made considerable progress in image inpainting by introducing structure priors. Due to the lack of proper interaction with image texture during structure reconstruction, however, current solutions are incompetent in handling the cases with large corruptions, and they generally suffer from distorted results. In this paper, we propose a novel two-stream network for image inpainting, which models the structure-constrained texture synthesis and texture-guided structure reconstruction in a coupled manner so that they better leverage each other for more plausible generation. Furthermore, to enhance the global consistency, a Bi-directional Gated Feature Fusion (Bi-GFF) module is designed to exchange and combine the structure and texture information and a Contextual Feature Aggregation (CFA) module is developed to refine the generated contents by region affinity learning and multi-scale feature aggregation. Qualitative and quantitative experiments on the CelebA, Paris StreetView and Places2 datasets demonstrate the superiority of the proposed method. Our code is available at https://github.com/Xiefan-Guo/CTSDG.