 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Polysemantic Spoof Trace: A Multi-Modal Disentanglement Network for Face Anti-spoofing
Dec 07, 2022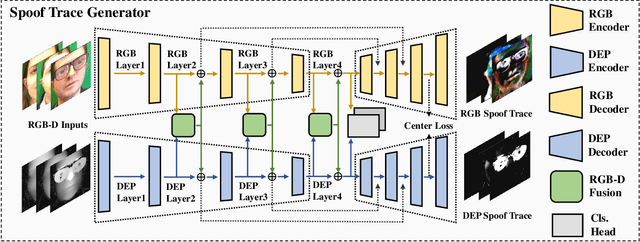
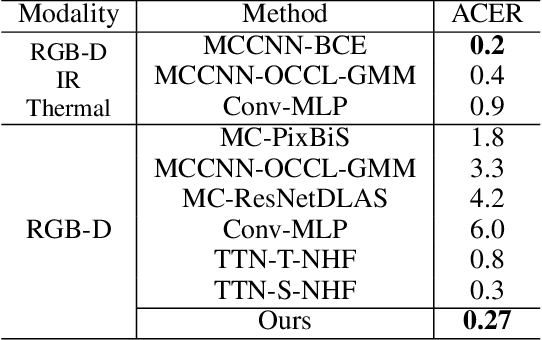
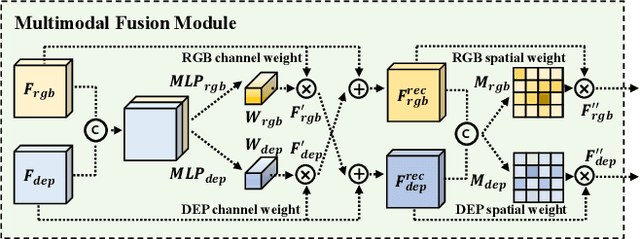
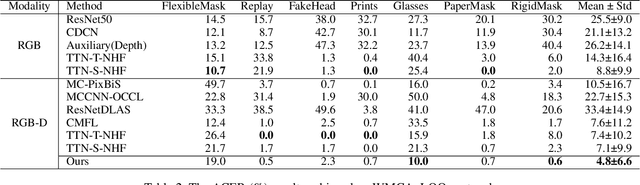
Along with the widespread use of face recognition systems, their vulnerability has become highlighted. While existing face anti-spoofing methods can be generalized between attack types, generic solutions are still challenging due to the diversity of spoof characteristics. Recently, the spoof trace disentanglement framework has shown great potential for coping with both seen and unseen spoof scenarios, but the performance is largely restricted by the single-modal input. This paper focuses on this issue and presents a multi-modal disentanglement model which targetedly learns polysemantic spoof traces for more accurate and robust generic attack detection. In particular, based on the adversarial learning mechanism, a two-stream disentangling network is designed to estimate spoof patterns from the RGB and depth inputs, respectively. In this case, it captures complementary spoofing clues inhering in different attacks. Furthermore, a fusion module is exploited, which recalibrates both representations at multiple stages to promote the disentanglement in each individual modality. It then performs cross-modality aggregation to deliver a more comprehensive spoof trace representation for prediction. Extensive evaluations are conducted on multiple benchmarks, demonstrating that learning polysemantic spoof traces favorably contributes to anti-spoofing with more perceptible and interpretable results.
CN-CELEB: a challenging Chinese speaker recognition dataset
Oct 31, 2019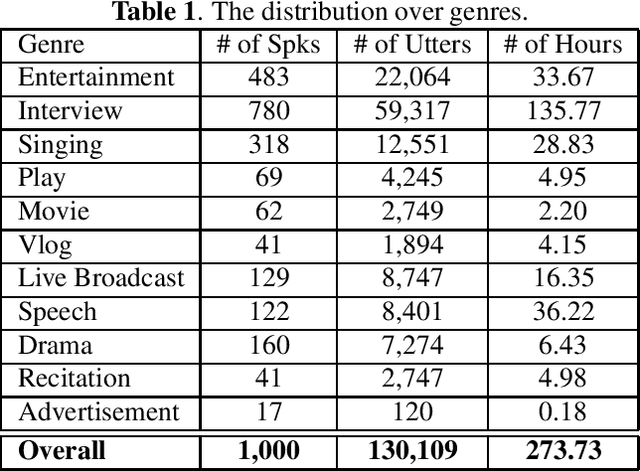
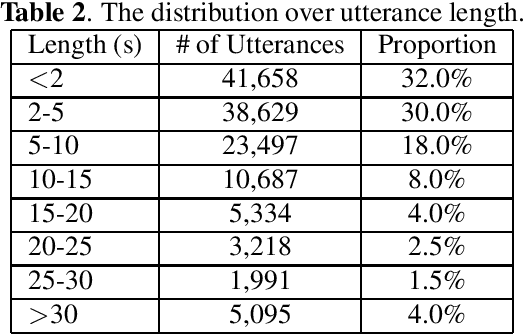
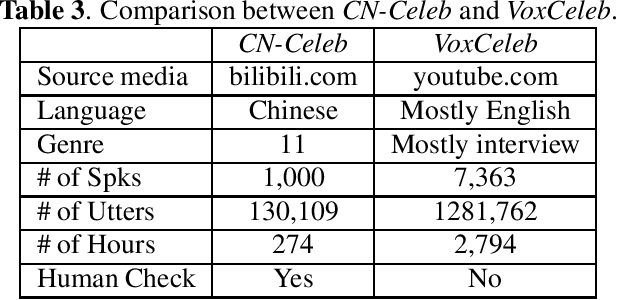

Recently, researchers set an ambitious goal of conducting speaker recognition in unconstrained conditions where the variations on ambient, channel and emotion could be arbitrary. However, most publicly available datasets are collected under constrained environments, i.e., with little noise and limited channel variation. These datasets tend to deliver over optimistic performance and do not meet the request of research on speaker recognition in unconstrained conditions. In this paper, we present CN-Celeb, a large-scale speaker recognition dataset collected `in the wild'. This dataset contains more than 130,000 utterances from 1,000 Chinese celebrities, and covers 11 different genres in real world. Experiments conducted with two state-of-the-art speaker recognition approaches (i-vector and x-vector) show that the performance on CN-Celeb is far inferior to the one obtained on VoxCeleb, a widely used speaker recognition dataset. This result demonstrates that in real-life conditions, the performance of existing techniques might be much worse than it was thought. Our database is free for researchers and can be downloaded from http://project.cslt.org.