 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyncTrack: Rhythmic Stability and Synchronization in Multi-Track Music Generation
Mar 01, 2026Multi-track music generation has garnered significant research interest due to its precise mixing and remixing capabilities. However, existing models often overlook essential attributes such as rhythmic stability and synchronization, leading to a focus on differences between tracks rather than their inherent properties. In this paper, we introduce SyncTrack, a synchronous multi-track waveform music generation model designed to capture the unique characteristics of multi-track music. SyncTrack features a novel architecture that includes track-shared modules to establish a common rhythm across all tracks and track-specific modules to accommodate diverse timbres and pitch ranges. Each track-shared module employs two cross-track attention mechanisms to synchronize rhythmic information, while each track-specific module utilizes learnable instrument priors to better represent timbre and other unique features. Additionally, we enhance the evaluation of multi-track music quality by introducing rhythmic consistency through three novel metrics: Inner-track Rhythmic Stability (IRS), Cross-track Beat Synchronization (CBS), and Cross-track Beat Dispersion (CBD). Experiments demonstrate that SyncTrack significantly improves the multi-track music quality by enhancing rhythmic consistency.
Voices of Civilizations: A Multilingual QA Benchmark for Global Music Understanding
Feb 28, 2026We introduce Voices of Civilizations, the first multilingual QA benchmark for evaluating audio LLMs' cultural comprehension on full-length music recordings. Covering 380 tracks across 38 languages, our automated pipeline yields 1,190 multiple-choice questions through four stages - each followed by manual verification: 1) compiling a representative music list; 2) generating cultural-background documents for each sample in the music list via LLMs; 3) extracting key attributes from those documents; and 4) constructing multiple-choice questions probing language, region associations, mood, and thematic content. We evaluate models under four conditions and report per-language accuracy. Our findings demonstrate that even state-of-the-art audio LLMs struggle to capture subtle cultural nuances without rich textual context and exhibit systematic biases in interpreting music from different cultural traditions. The dataset is publicly available on Hugging Face to foster culturally inclusive music understanding research.
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix
May 19, 2025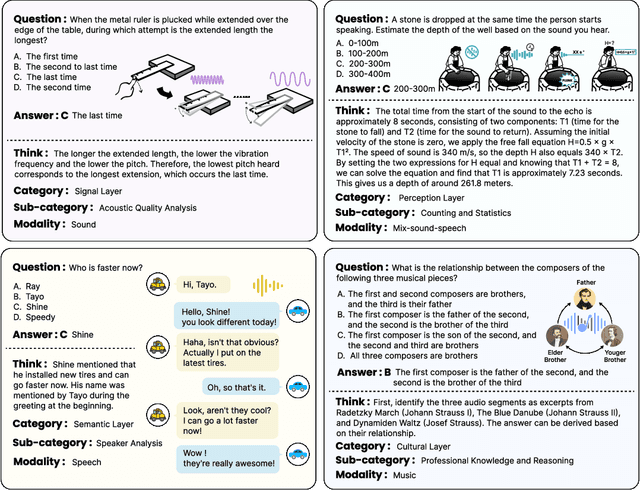

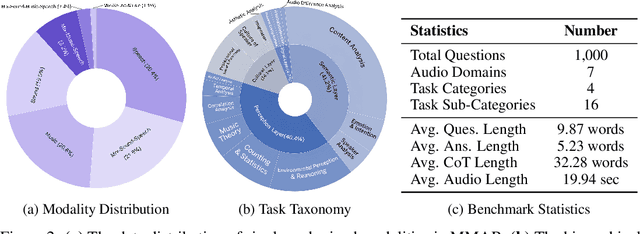
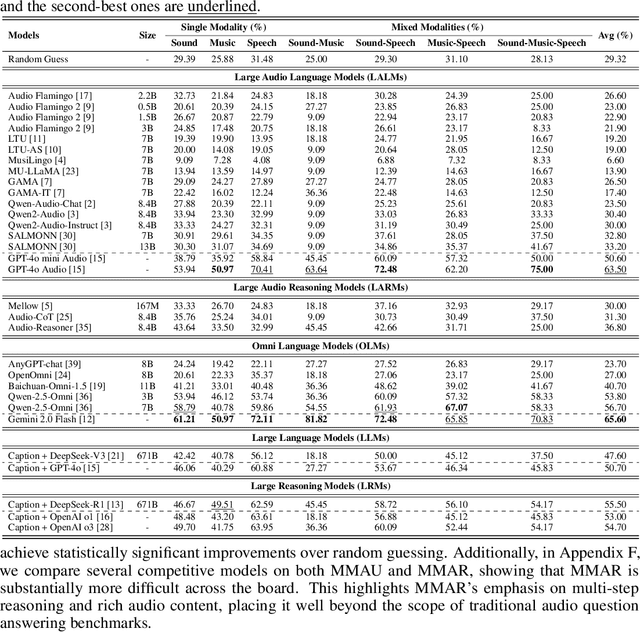
We introduce MMAR, a new benchmark designed to evaluate the deep reasoning capabilities of Audio-Language Models (ALMs) across massive multi-disciplinary tasks. MMAR comprises 1,000 meticulously curated audio-question-answer triplets, collected from real-world internet videos and refined through iterative error corrections and quality checks to ensure high quality. Unlike existing benchmarks that are limited to specific domains of sound, music, or speech, MMAR extends them to a broad spectrum of real-world audio scenarios, including mixed-modality combinations of sound, music, and speech. Each question in MMAR is hierarchically categorized across four reasoning layers: Signal, Perception, Semantic, and Cultural, with additional sub-categories within each layer to reflect task diversity and complexity. To further foster research in this area, we annotate every question with a Chain-of-Thought (CoT) rationale to promote future advancements in audio reasoning. Each item in the benchmark demands multi-step deep reasoning beyond surface-level understanding. Moreover, a part of the questions requires graduate-level perceptual and domain-specific knowledge, elevating the benchmark's difficulty and depth. We evaluate MMAR using a broad set of models, including Large Audio-Language Models (LALMs), Large Audio Reasoning Models (LARMs), Omni Language Models (OLMs), Large Language Models (LLMs), and Large Reasoning Models (LRMs), with audio caption inputs. The performance of these models on MMAR highlights the benchmark's challenging nature, and our analysis further reveals critical limitations of understanding and reasoning capabilities among current models. We hope MMAR will serve as a catalyst for future advances in this important but little-explored area.
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
Audio-FLAN: A Preliminary Release
Feb 23, 2025



Recent advancements in audio tokenization have significantly enhanced the integration of audio capabilities into large language models (LLMs). However, audio understanding and generation are often treated as distinct tasks, hindering the development of truly unified audio-language models. While instruction tuning has demonstrated remarkable success in improving generalization and zero-shot learning across text and vision, its application to audio remains largely unexplored. A major obstacle is the lack of comprehensive datasets that unify audio understanding and generation. To address this, we introduce Audio-FLAN, a large-scale instruction-tuning dataset covering 80 diverse tasks across speech, music, and sound domains, with over 100 million instances. Audio-FLAN lays the foundation for unified audio-language models that can seamlessly handle both understanding (e.g., transcription, comprehension) and generation (e.g., speech, music, sound) tasks across a wide range of audio domains in a zero-shot manner. The Audio-FLAN dataset is available on HuggingFace and GitHub and will be continuously updated.
SINGER: Vivid Audio-driven Singing Video Generation with Multi-scale Spectral Diffusion Model
Dec 04, 2024Recent advancements in generative models have significantly enhanced talking face video generation, yet singing video generation remains underexplored. The differences between human talking and singing limit the performance of existing talking face video generation models when applied to singing. The fundamental differences between talking and singing-specifically in audio characteristics and behavioral expressions-limit the effectiveness of existing models. We observe that the differences between singing and talking audios manifest in terms of frequency and amplitude. To address this, we have designed a multi-scale spectral module to help the model learn singing patterns in the spectral domain. Additionally, we develop a spectral-filtering module that aids the model in learning the human behaviors associated with singing audio. These two modules are integrated into the diffusion model to enhance singing video generation performance, resulting in our proposed model, SINGER. Furthermore, the lack of high-quality real-world singing face videos has hindered the development of the singing video generation community. To address this gap, we have collected an in-the-wild audio-visual singing dataset to facilitate research in this area. Our experiments demonstrate that SINGER is capable of generating vivid singing videos and outperforms state-of-the-art methods in both objective and subjective evaluations.
Can LLMs "Reason" in Music? An Evaluation of LLMs' Capability of Music Understanding and Generation
Jul 31, 2024


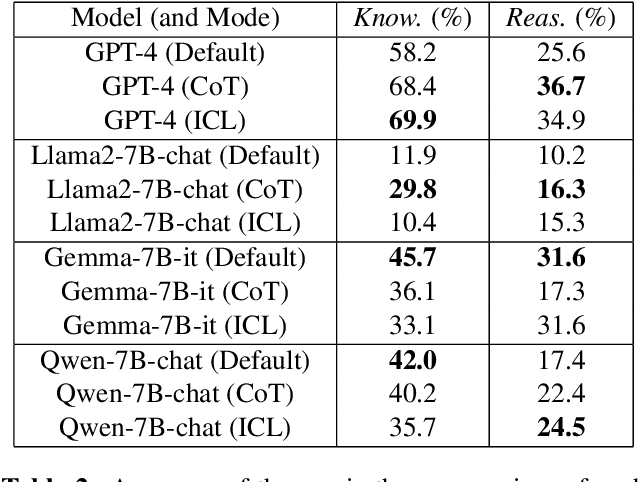
Symbolic Music, akin to language, can be encoded in discrete symbols. Recent research has extended the application of large language models (LLMs) such as GPT-4 and Llama2 to the symbolic music domain including understanding and generation. Yet scant research explores the details of how these LLMs perform on advanced music understanding and conditioned generation, especially from the multi-step reasoning perspective, which is a critical aspect in the conditioned, editable, and interactive human-computer co-creation process. This study conducts a thorough investigation of LLMs' capability and limitations in symbolic music processing. We identify that current LLMs exhibit poor performance in song-level multi-step music reasoning, and typically fail to leverage learned music knowledge when addressing complex musical tasks. An analysis of LLMs' responses highlights distinctly their pros and cons. Our findings suggest achieving advanced musical capability is not intrinsically obtained by LLMs, and future research should focus more on bridging the gap between music knowledge and reasoning, to improve the co-creation experience for musicians.
MuPT: A Generative Symbolic Music Pretrained Transformer
Apr 10, 2024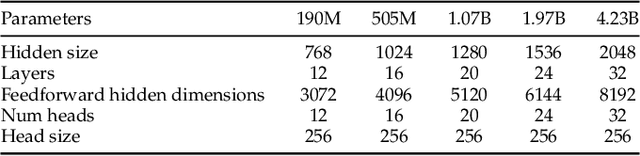

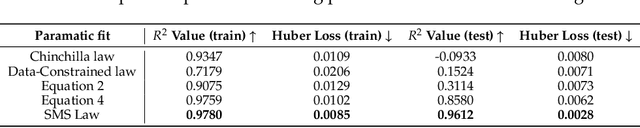
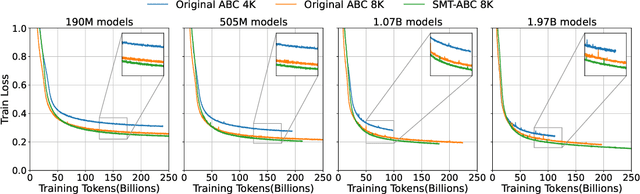
In this paper, we explore the application of Large Language Models (LLMs) to the pre-training of music. While the prevalent use of MIDI in music modeling is well-established, our findings suggest that LLMs are inherently more compatible with ABC Notation, which aligns more closely with their design and strengths, thereby enhancing the model's performance in musical composition. To address the challenges associated with misaligned measures from different tracks during generation, we propose the development of a Synchronized Multi-Track ABC Notation (SMT-ABC Notation), which aims to preserve coherence across multiple musical tracks. Our contributions include a series of models capable of handling up to 8192 tokens, covering 90% of the symbolic music data in our training set. Furthermore, we explore the implications of the Symbolic Music Scaling Law (SMS Law) on model performance. The results indicate a promising direction for future research in music generation, offering extensive resources for community-led research through our open-source contributions.
ChatMusician: Understanding and Generating Music Intrinsically with LLM
Feb 25, 2024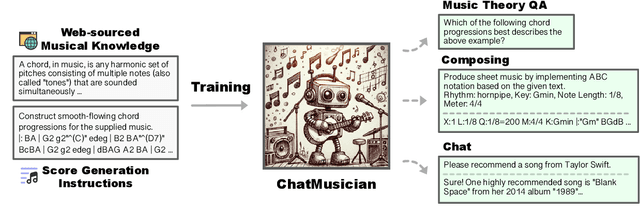
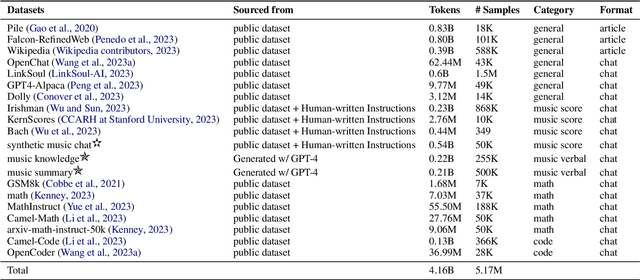


While Large Language Models (LLMs) demonstrate impressive capabilities in text generation, we find that their ability has yet to be generalized to music, humanity's creative language. We introduce ChatMusician, an open-source LLM that integrates intrinsic musical abilities. It is based on continual pre-training and finetuning LLaMA2 on a text-compatible music representation, ABC notation, and the music is treated as a second language. ChatMusician can understand and generate music with a pure text tokenizer without any external multi-modal neural structures or tokenizers. Interestingly, endowing musical abilities does not harm language abilities, even achieving a slightly higher MMLU score. Our model is capable of composing well-structured, full-length music, conditioned on texts, chords, melodies, motifs, musical forms, etc, surpassing GPT-4 baseline. On our meticulously curated college-level music understanding benchmark, MusicTheoryBench, ChatMusician surpasses LLaMA2 and GPT-3.5 on zero-shot setting by a noticeable margin. Our work reveals that LLMs can be an excellent compressor for music, but there remains significant territory to be conquered. We release our 4B token music-language corpora MusicPile, the collected MusicTheoryBench, code, model and demo in GitHub.
CCOM-HuQin: an Annotated Multimodal Chinese Fiddle Performance Dataset
Sep 14, 2022
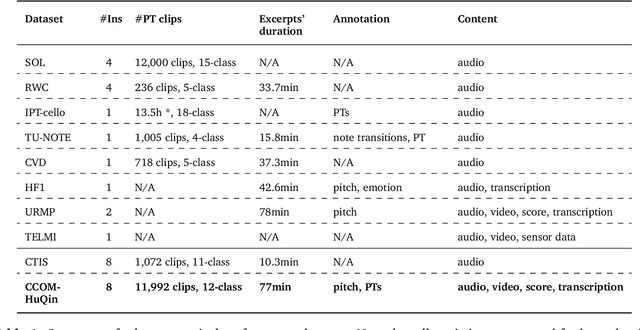
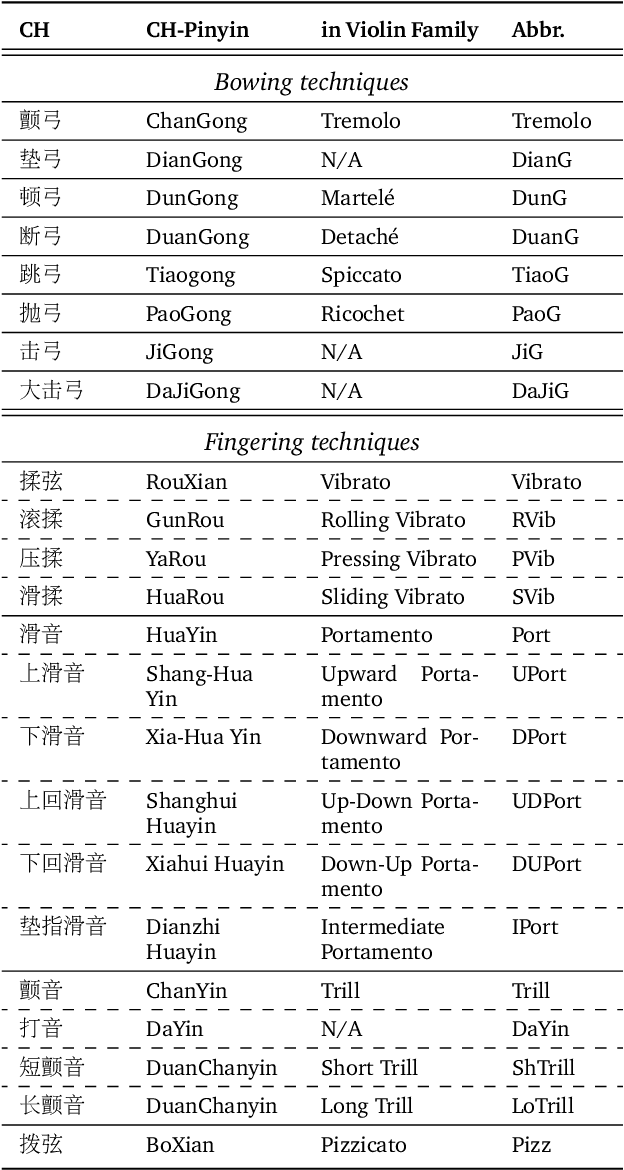
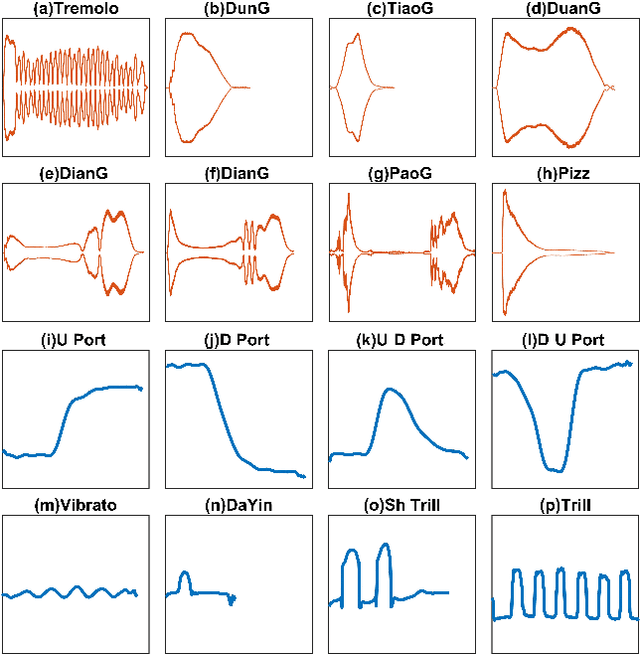
HuQin is a family of traditional Chinese bowed string instruments. Playing techniques(PTs) embodied in various playing styles add abundant emotional coloring and aesthetic feelings to HuQin performance. The complex applied techniques make HuQin music a challenging source for fundamental MIR tasks such as pitch analysis, transcription and score-audio alignment. In this paper, we present a multimodal performance dataset of HuQin music that contains audio-visual recordings of 11,992 single PT clips and 57 annotated musical pieces of classical excerpts. We systematically describe the HuQin PT taxonomy based on musicological theory and practical use cases. Then we introduce the dataset creation methodology and highlight the annotation principles featuring PTs. We analyze the statistics in different aspects to demonstrate the variety of PTs played in HuQin subcategories and perform preliminary experiments to show the potential applications of the dataset in various MIR tasks and cross-cultural music studies. Finally, we propose future work to be extended on the dataset.