 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
NotaGen: Advancing Musicality in Symbolic Music Generation with Large Language Model Training Paradigms
Feb 26, 2025We introduce NotaGen, a symbolic music generation model aiming to explore the potential of producing high-quality classical sheet music. Inspired by the success of Large Language Models (LLMs), NotaGen adopts pre-training, fine-tuning, and reinforcement learning paradigms (henceforth referred to as the LLM training paradigms). It is pre-trained on 1.6M pieces of music, and then fine-tuned on approximately 9K high-quality classical compositions conditioned on "period-composer-instrumentation" prompts. For reinforcement learning, we propose the CLaMP-DPO method, which further enhances generation quality and controllability without requiring human annotations or predefined rewards. Our experiments demonstrate the efficacy of CLaMP-DPO in symbolic music generation models with different architectures and encoding schemes. Furthermore, subjective A/B tests show that NotaGen outperforms baseline models against human compositions, greatly advancing musical aesthetics in symbolic music generation. The project homepage is https://electricalexis.github.io/notagen-demo.
Exploring Tokenization Methods for Multitrack Sheet Music Generation
Oct 23, 2024

This study explores the tokenization of multitrack sheet music in ABC notation, introducing two methods--bar-stream and line-stream patching. We compare these methods against existing techniques, including bar patching, byte patching, and Byte Pair Encoding (BPE). In terms of both computational efficiency and the musicality of the generated compositions, experimental results show that bar-stream patching performs best overall compared to the others, which makes it a promising tokenization strategy for sheet music generation.
CLaMP 2: Multimodal Music Information Retrieval Across 101 Languages Using Large Language Models
Oct 17, 2024



Challenges in managing linguistic diversity and integrating various musical modalities are faced by current music information retrieval systems. These limitations reduce their effectiveness in a global, multimodal music environment. To address these issues, we introduce CLaMP 2, a system compatible with 101 languages that supports both ABC notation (a text-based musical notation format) and MIDI (Musical Instrument Digital Interface) for music information retrieval. CLaMP 2, pre-trained on 1.5 million ABC-MIDI-text triplets, includes a multilingual text encoder and a multimodal music encoder aligned via contrastive learning. By leveraging large language models, we obtain refined and consistent multilingual descriptions at scale, significantly reducing textual noise and balancing language distribution. Our experiments show that CLaMP 2 achieves state-of-the-art results in both multilingual semantic search and music classification across modalities, thus establishing a new standard for inclusive and global music information retrieval.
Foundation Models for Music: A Survey
Aug 27, 2024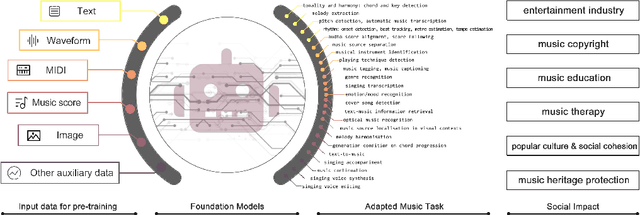

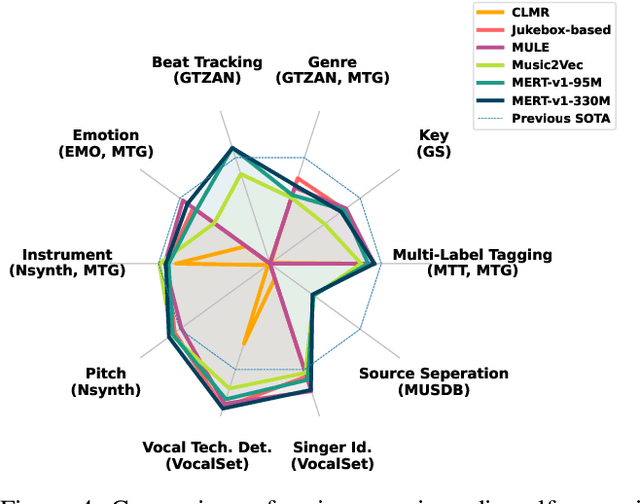
In recent years, foundation models (FMs) such as large language models (LLMs) and latent diffusion models (LDMs) have profoundly impacted diverse sectors, including music. This comprehensive review examines state-of-the-art (SOTA) pre-trained models and foundation models in music, spanning from representation learning, generative learning and multimodal learning. We first contextualise the significance of music in various industries and trace the evolution of AI in music. By delineating the modalities targeted by foundation models, we discover many of the music representations are underexplored in FM development. Then, emphasis is placed on the lack of versatility of previous methods on diverse music applications, along with the potential of FMs in music understanding, generation and medical application. By comprehensively exploring the details of the model pre-training paradigm, architectural choices, tokenisation, finetuning methodologies and controllability, we emphasise the important topics that should have been well explored, like instruction tuning and in-context learning, scaling law and emergent ability, as well as long-sequence modelling etc. A dedicated section presents insights into music agents, accompanied by a thorough analysis of datasets and evaluations essential for pre-training and downstream tasks. Finally, by underscoring the vital importance of ethical considerations, we advocate that following research on FM for music should focus more on such issues as interpretability, transparency, human responsibility, and copyright issues. The paper offers insights into future challenges and trends on FMs for music, aiming to shape the trajectory of human-AI collaboration in the music realm.
MelodyT5: A Unified Score-to-Score Transformer for Symbolic Music Processing
Jul 02, 2024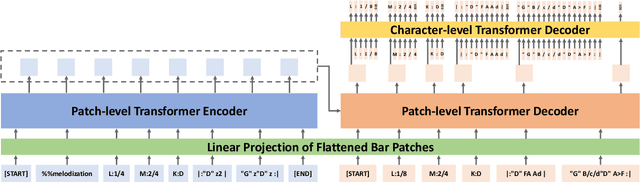
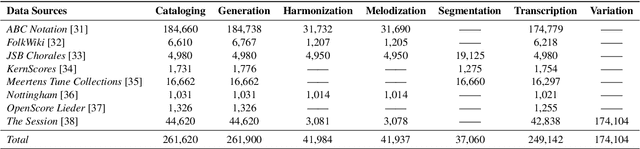

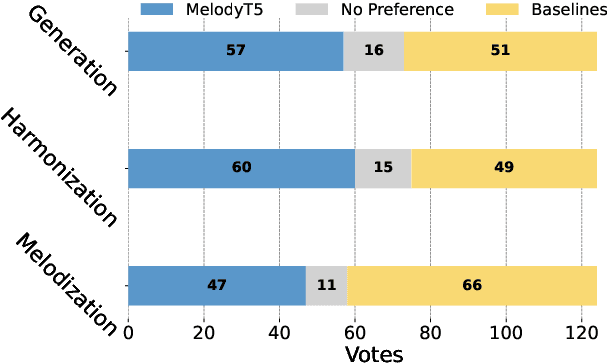
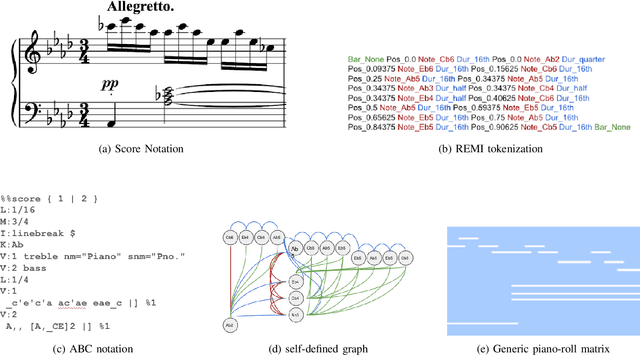
In the domain of symbolic music research, the progress of developing scalable systems has been notably hindered by the scarcity of available training data and the demand for models tailored to specific tasks. To address these issues, we propose MelodyT5, a novel unified framework that leverages an encoder-decoder architecture tailored for symbolic music processing in ABC notation. This framework challenges the conventional task-specific approach, considering various symbolic music tasks as score-to-score transformations. Consequently, it integrates seven melody-centric tasks, from generation to harmonization and segmentation, within a single model. Pre-trained on MelodyHub, a newly curated collection featuring over 261K unique melodies encoded in ABC notation and encompassing more than one million task instances, MelodyT5 demonstrates superior performance in symbolic music processing via multi-task transfer learning. Our findings highlight the efficacy of multi-task transfer learning in symbolic music processing, particularly for data-scarce tasks, challenging the prevailing task-specific paradigms and offering a comprehensive dataset and framework for future explorations in this domain.
MuPT: A Generative Symbolic Music Pretrained Transformer
Apr 10, 2024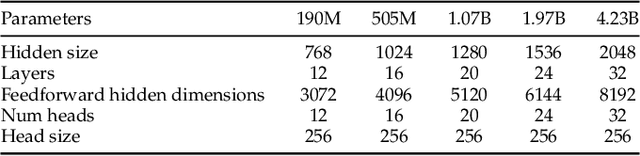

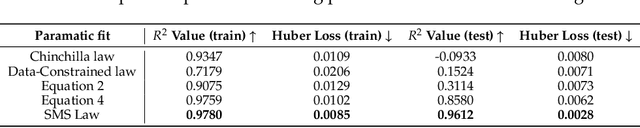
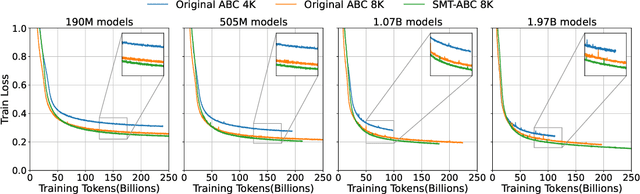
In this paper, we explore the application of Large Language Models (LLMs) to the pre-training of music. While the prevalent use of MIDI in music modeling is well-established, our findings suggest that LLMs are inherently more compatible with ABC Notation, which aligns more closely with their design and strengths, thereby enhancing the model's performance in musical composition. To address the challenges associated with misaligned measures from different tracks during generation, we propose the development of a Synchronized Multi-Track ABC Notation (SMT-ABC Notation), which aims to preserve coherence across multiple musical tracks. Our contributions include a series of models capable of handling up to 8192 tokens, covering 90% of the symbolic music data in our training set. Furthermore, we explore the implications of the Symbolic Music Scaling Law (SMS Law) on model performance. The results indicate a promising direction for future research in music generation, offering extensive resources for community-led research through our open-source contributions.
Beyond Language Models: Byte Models are Digital World Simulators
Feb 29, 2024

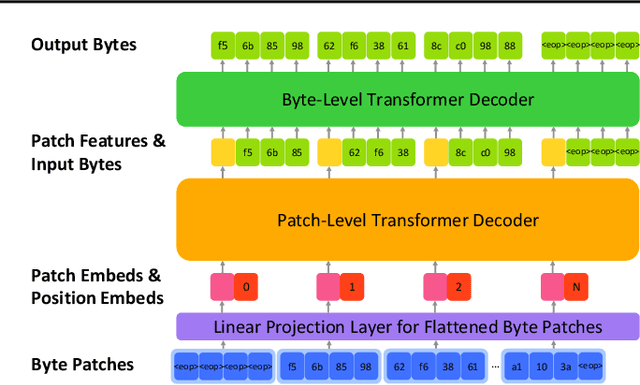

Traditional deep learning often overlooks bytes, the basic units of the digital world, where all forms of information and operations are encoded and manipulated in binary format. Inspired by the success of next token prediction in natural language processing, we introduce bGPT, a model with next byte prediction to simulate the digital world. bGPT matches specialized models in performance across various modalities, including text, audio, and images, and offers new possibilities for predicting, simulating, and diagnosing algorithm or hardware behaviour. It has almost flawlessly replicated the process of converting symbolic music data, achieving a low error rate of 0.0011 bits per byte in converting ABC notation to MIDI format. In addition, bGPT demonstrates exceptional capabilities in simulating CPU behaviour, with an accuracy exceeding 99.99% in executing various operations. Leveraging next byte prediction, models like bGPT can directly learn from vast binary data, effectively simulating the intricate patterns of the digital world.
ChatMusician: Understanding and Generating Music Intrinsically with LLM
Feb 25, 2024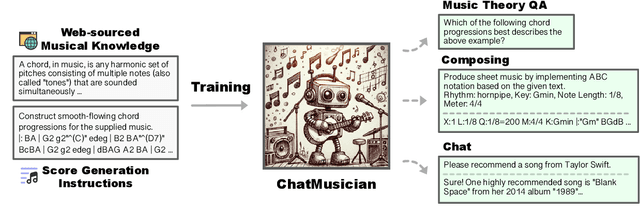
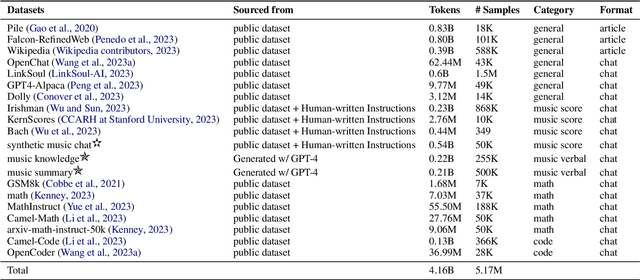


While Large Language Models (LLMs) demonstrate impressive capabilities in text generation, we find that their ability has yet to be generalized to music, humanity's creative language. We introduce ChatMusician, an open-source LLM that integrates intrinsic musical abilities. It is based on continual pre-training and finetuning LLaMA2 on a text-compatible music representation, ABC notation, and the music is treated as a second language. ChatMusician can understand and generate music with a pure text tokenizer without any external multi-modal neural structures or tokenizers. Interestingly, endowing musical abilities does not harm language abilities, even achieving a slightly higher MMLU score. Our model is capable of composing well-structured, full-length music, conditioned on texts, chords, melodies, motifs, musical forms, etc, surpassing GPT-4 baseline. On our meticulously curated college-level music understanding benchmark, MusicTheoryBench, ChatMusician surpasses LLaMA2 and GPT-3.5 on zero-shot setting by a noticeable margin. Our work reveals that LLMs can be an excellent compressor for music, but there remains significant territory to be conquered. We release our 4B token music-language corpora MusicPile, the collected MusicTheoryBench, code, model and demo in GitHub.
A Holistic Evaluation of Piano Sound Quality
Oct 07, 2023
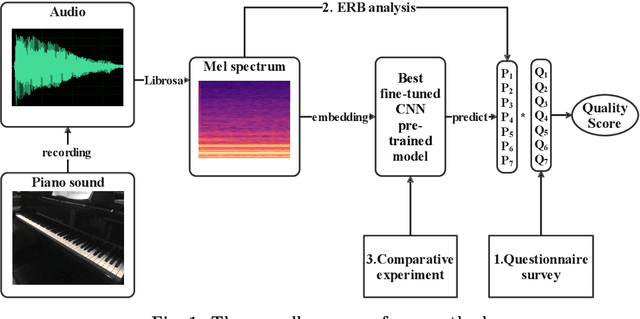

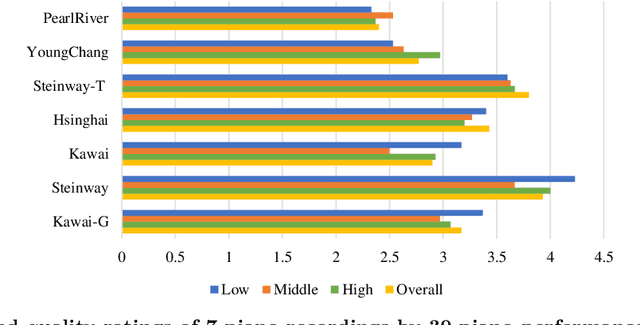
This paper aims to develop a holistic evaluation method for piano sound quality to assist in purchasing decisions. Unlike previous studies that focused on the effect of piano performance techniques on sound quality, this study evaluates the inherent sound quality of different pianos. To derive quality evaluation systems, the study uses subjective questionnaires based on a piano sound quality dataset. The method selects the optimal piano classification models by comparing the fine-tuning results of different pre-training models of Convolutional Neural Networks (CNN). To improve the interpretability of the models, the study applies Equivalent Rectangular Bandwidth (ERB) analysis. The results reveal that musically trained individuals are better able to distinguish between the sound quality differences of different pianos. The best fine-tuned CNN pre-trained backbone achieves a high accuracy of 98.3\% as the piano classifier. However, the dataset is limited, and the audio is sliced to increase its quantity, resulting in a lack of diversity and balance, so we use focal loss to reduce the impact of data imbalance. To optimize the method, the dataset will be expanded, or few-shot learning techniques will be employed in future research.