 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Renaissance of Expert Systems: Optical Recognition of Printed Chinese Jianpu Musical Scores with Lyrics
Dec 15, 2025Large-scale optical music recognition (OMR) research has focused mainly on Western staff notation, leaving Chinese Jianpu (numbered notation) and its rich lyric resources underexplored. We present a modular expert-system pipeline that converts printed Jianpu scores with lyrics into machine-readable MusicXML and MIDI, without requiring massive annotated training data. Our approach adopts a top-down expert-system design, leveraging traditional computer-vision techniques (e.g., phrase correlation, skeleton analysis) to capitalize on prior knowledge, while integrating unsupervised deep-learning modules for image feature embeddings. This hybrid strategy strikes a balance between interpretability and accuracy. Evaluated on The Anthology of Chinese Folk Songs, our system massively digitizes (i) a melody-only collection of more than 5,000 songs (> 300,000 notes) and (ii) a curated subset with lyrics comprising over 1,400 songs (> 100,000 notes). The system achieves high-precision recognition on both melody (note-wise F1 = 0.951) and aligned lyrics (character-wise F1 = 0.931).
An Interpretable Multi-Plane Fusion Framework With Kolmogorov-Arnold Network Guided Attention Enhancement for Alzheimer's Disease Diagnosis
Aug 08, 2025Alzheimer's disease (AD) is a progressive neurodegenerative disorder that severely impairs cognitive function and quality of life. Timely intervention in AD relies heavily on early and precise diagnosis, which remains challenging due to the complex and subtle structural changes in the brain. Most existing deep learning methods focus only on a single plane of structural magnetic resonance imaging (sMRI) and struggle to accurately capture the complex and nonlinear relationships among pathological regions of the brain, thus limiting their ability to precisely identify atrophic features. To overcome these limitations, we propose an innovative framework, MPF-KANSC, which integrates multi-plane fusion (MPF) for combining features from the coronal, sagittal, and axial planes, and a Kolmogorov-Arnold Network-guided spatial-channel attention mechanism (KANSC) to more effectively learn and represent sMRI atrophy features. Specifically, the proposed model enables parallel feature extraction from multiple anatomical planes, thus capturing more comprehensive structural information. The KANSC attention mechanism further leverages a more flexible and accurate nonlinear function approximation technique, facilitating precise identification and localization of disease-related abnormalities. Experiments on the ADNI dataset confirm that the proposed MPF-KANSC achieves superior performance in AD diagnosis. Moreover, our findings provide new evidence of right-lateralized asymmetry in subcortical structural changes during AD progression, highlighting the model's promising interpretability.
Exploring the Acoustics of the Chinese Transverse Flute (dizi)
Sep 07, 2024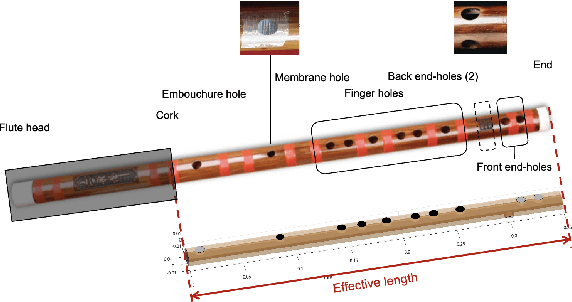
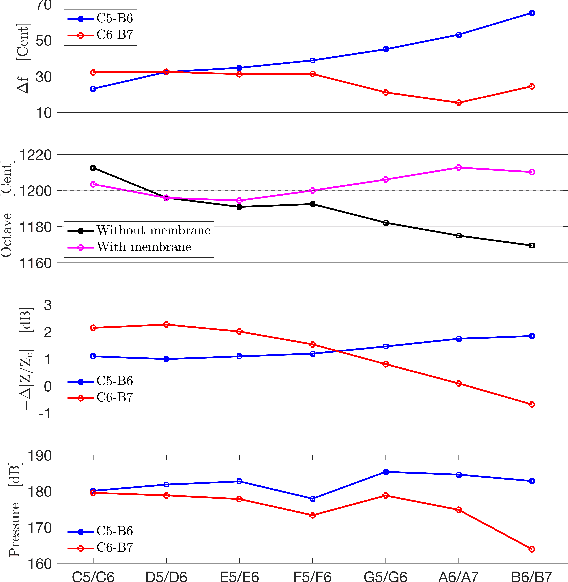
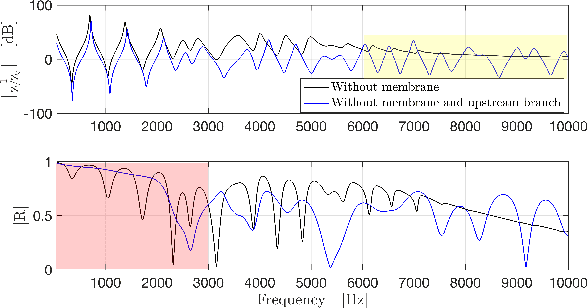

We investigate the acoustical characteristics of the Chinese transverse flute, the dizi, employing input impedance measurements, modeling and analysis. The input impedances for various fingerings of a bangdi in the key of F, a particular type of the dizi, are measured and compared to models using both the transfer matrix method and the Transfer Matrix Method with external Interaction (TMMI). In order to get more accurate modeling results, we provide specific transfer matrices for the unique components of the dizi, such as back end-holes, membrane hole and upstream branch. The matching volume length correction for holes drilled in a thick wall is also derived. Comparative analysis of modeling and measurement data validates the improved accuracy of TMMI, confirming the influence of radiated sound from closely spaced toneholes.
Reducing Barriers to the Use of Marginalised Music Genres in AI
Jul 18, 2024AI systems for high quality music generation typically rely on extremely large musical datasets to train the AI models. This creates barriers to generating music beyond the genres represented in dominant datasets such as Western Classical music or pop music. We undertook a 4 month international research project summarised in this paper to explore the eXplainable AI (XAI) challenges and opportunities associated with reducing barriers to using marginalised genres of music with AI models. XAI opportunities identified included topics of improving transparency and control of AI models, explaining the ethics and bias of AI models, fine tuning large models with small datasets to reduce bias, and explaining style-transfer opportunities with AI models. Participants in the research emphasised that whilst it is hard to work with small datasets such as marginalised music and AI, such approaches strengthen cultural representation of underrepresented cultures and contribute to addressing issues of bias of deep learning models. We are now building on this project to bring together a global International Responsible AI Music community and invite people to join our network.
Proceedings of The first international workshop on eXplainable AI for the Arts (XAIxArts)
Oct 10, 2023This first international workshop on explainable AI for the Arts (XAIxArts) brought together a community of researchers in HCI, Interaction Design, AI, explainable AI (XAI), and digital arts to explore the role of XAI for the Arts. Workshop held at the 15th ACM Conference on Creativity and Cognition (C&C 2023).
A Holistic Evaluation of Piano Sound Quality
Oct 07, 2023
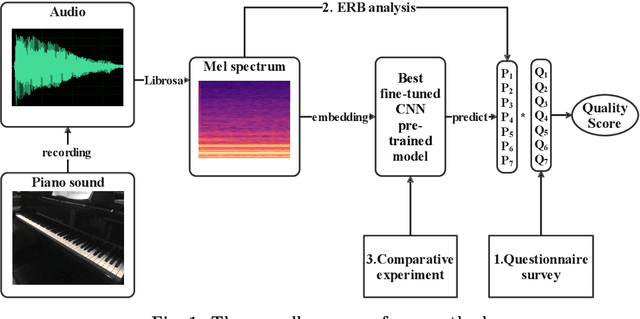

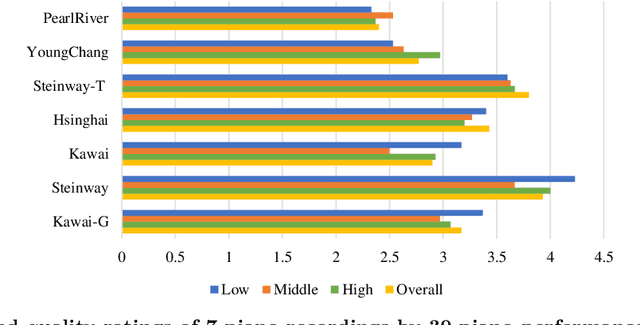
This paper aims to develop a holistic evaluation method for piano sound quality to assist in purchasing decisions. Unlike previous studies that focused on the effect of piano performance techniques on sound quality, this study evaluates the inherent sound quality of different pianos. To derive quality evaluation systems, the study uses subjective questionnaires based on a piano sound quality dataset. The method selects the optimal piano classification models by comparing the fine-tuning results of different pre-training models of Convolutional Neural Networks (CNN). To improve the interpretability of the models, the study applies Equivalent Rectangular Bandwidth (ERB) analysis. The results reveal that musically trained individuals are better able to distinguish between the sound quality differences of different pianos. The best fine-tuned CNN pre-trained backbone achieves a high accuracy of 98.3\% as the piano classifier. However, the dataset is limited, and the audio is sliced to increase its quantity, resulting in a lack of diversity and balance, so we use focal loss to reduce the impact of data imbalance. To optimize the method, the dataset will be expanded, or few-shot learning techniques will be employed in future research.
Learning Singing From Speech
Dec 20, 2019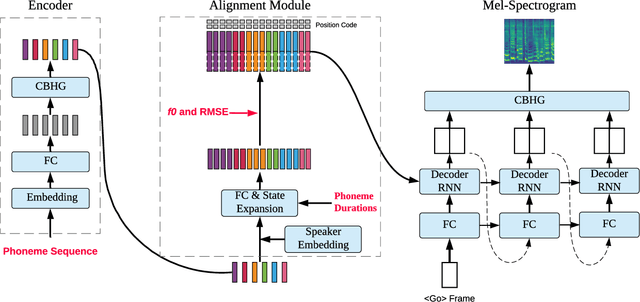
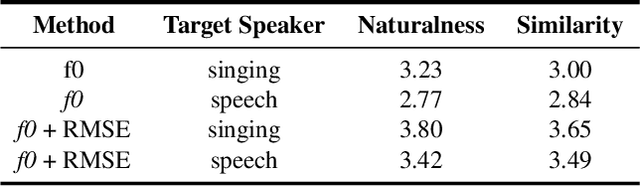
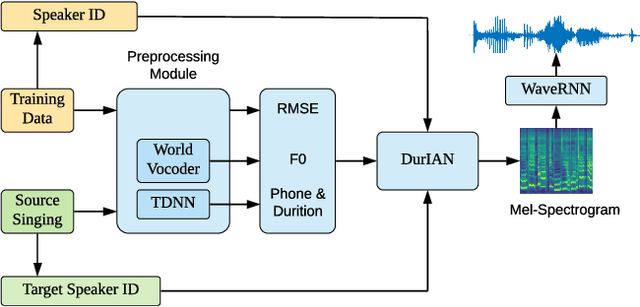
We propose an algorithm that is capable of synthesizing high quality target speaker's singing voice given only their normal speech samples. The proposed algorithm first integrate speech and singing synthesis into a unified framework, and learns universal speaker embeddings that are shareable between speech and singing synthesis tasks. Specifically, the speaker embeddings learned from normal speech via the speech synthesis objective are shared with those learned from singing samples via the singing synthesis objective in the unified training framework. This makes the learned speaker embedding a transferable representation for both speaking and singing. We evaluate the proposed algorithm on singing voice conversion task where the content of original singing is covered with the timbre of another speaker's voice learned purely from their normal speech samples. Our experiments indicate that the proposed algorithm generates high-quality singing voices that sound highly similar to target speaker's voice given only his or her normal speech samples. We believe that proposed algorithm will open up new opportunities for singing synthesis and conversion for broader users and applications.