 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCMusic: An Open and Diverse Database for Chinese Music Information Retrieval Research
Mar 24, 2025Data are crucial in various computer-related fields, including music information retrieval (MIR), an interdisciplinary area bridging computer science and music. This paper introduces CCMusic, an open and diverse database comprising multiple datasets specifically designed for tasks related to Chinese music, highlighting our focus on this culturally rich domain. The database integrates both published and unpublished datasets, with steps taken such as data cleaning, label refinement, and data structure unification to ensure data consistency and create ready-to-use versions. We conduct benchmark evaluations for all datasets using a unified evaluation framework developed specifically for this purpose. This publicly available framework supports both classification and detection tasks, ensuring standardized and reproducible results across all datasets. The database is hosted on HuggingFace and ModelScope, two open and multifunctional data and model hosting platforms, ensuring ease of accessibility and usability.
* 17 pages, 18 figures
Semi-Supervised Self-Learning Enhanced Music Emotion Recognition
Oct 29, 2024

Music emotion recognition (MER) aims to identify the emotions conveyed in a given musical piece. But currently in the field of MER, the available public datasets have limited sample sizes. Recently, segment-based methods for emotion-related tasks have been proposed, which train backbone networks on shorter segments instead of entire audio clips, thereby naturally augmenting training samples without requiring additional resources. Then, the predicted segment-level results are aggregated to obtain the entire song prediction. The most commonly used method is that segment inherits the label of the clip containing it, but music emotion is not constant during the whole clip. Doing so will introduce label noise and make the training overfit easily. To handle the noisy label issue, we propose a semi-supervised self-learning (SSSL) method, which can differentiate between samples with correct and incorrect labels in a self-learning manner, thus effectively utilizing the augmented segment-level data. Experiments on three public emotional datasets demonstrate that the proposed method can achieve better or comparable performance.
CLaMP 2: Multimodal Music Information Retrieval Across 101 Languages Using Large Language Models
Oct 17, 2024



Challenges in managing linguistic diversity and integrating various musical modalities are faced by current music information retrieval systems. These limitations reduce their effectiveness in a global, multimodal music environment. To address these issues, we introduce CLaMP 2, a system compatible with 101 languages that supports both ABC notation (a text-based musical notation format) and MIDI (Musical Instrument Digital Interface) for music information retrieval. CLaMP 2, pre-trained on 1.5 million ABC-MIDI-text triplets, includes a multilingual text encoder and a multimodal music encoder aligned via contrastive learning. By leveraging large language models, we obtain refined and consistent multilingual descriptions at scale, significantly reducing textual noise and balancing language distribution. Our experiments show that CLaMP 2 achieves state-of-the-art results in both multilingual semantic search and music classification across modalities, thus establishing a new standard for inclusive and global music information retrieval.
A Holistic Evaluation of Piano Sound Quality
Oct 07, 2023
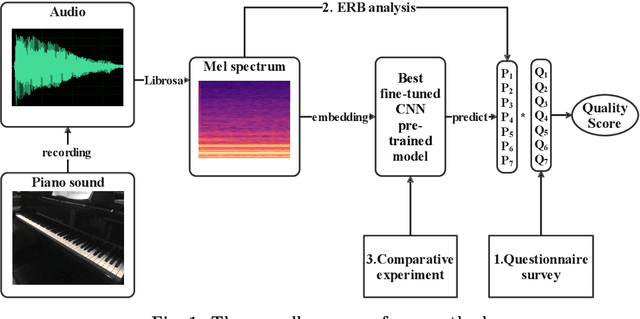

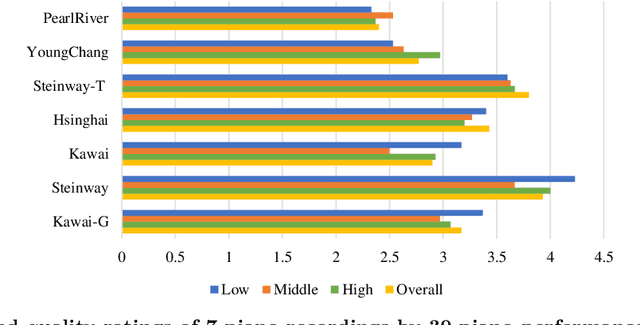
This paper aims to develop a holistic evaluation method for piano sound quality to assist in purchasing decisions. Unlike previous studies that focused on the effect of piano performance techniques on sound quality, this study evaluates the inherent sound quality of different pianos. To derive quality evaluation systems, the study uses subjective questionnaires based on a piano sound quality dataset. The method selects the optimal piano classification models by comparing the fine-tuning results of different pre-training models of Convolutional Neural Networks (CNN). To improve the interpretability of the models, the study applies Equivalent Rectangular Bandwidth (ERB) analysis. The results reveal that musically trained individuals are better able to distinguish between the sound quality differences of different pianos. The best fine-tuned CNN pre-trained backbone achieves a high accuracy of 98.3\% as the piano classifier. However, the dataset is limited, and the audio is sliced to increase its quantity, resulting in a lack of diversity and balance, so we use focal loss to reduce the impact of data imbalance. To optimize the method, the dataset will be expanded, or few-shot learning techniques will be employed in future research.
WikiMT++ Dataset Card
Sep 23, 2023WikiMT++ is an expanded and refined version of WikiMusicText (WikiMT), featuring 1010 curated lead sheets in ABC notation. To expand application scenarios of WikiMT, we add both objective (album, lyrics, video) and subjective emotion (12 emotion adjectives) and emo\_4q (Russell 4Q) attributes, enhancing its usability for music information retrieval, conditional music generation, automatic composition, and emotion classification, etc. Additionally, CLaMP is implemented to correct the attributes inherited from WikiMT to reduce errors introduced during original data collection and enhance the accuracy and completeness of our dataset.