 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCN-CELEB: a challenging Chinese speaker recognition dataset
Paper and Code
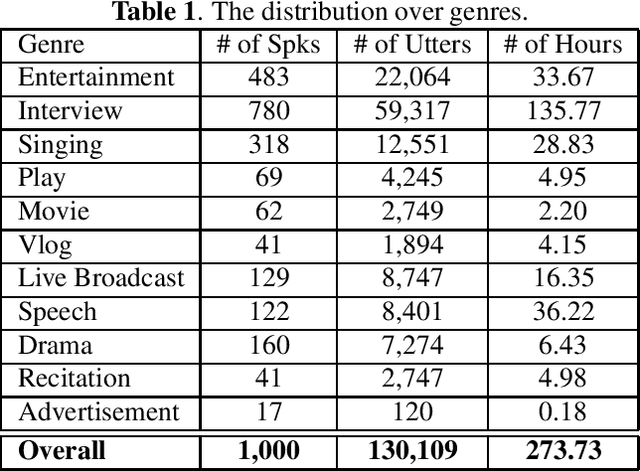
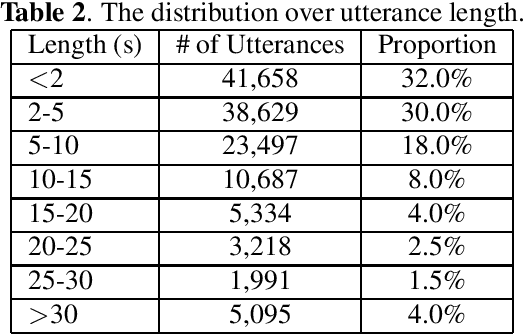
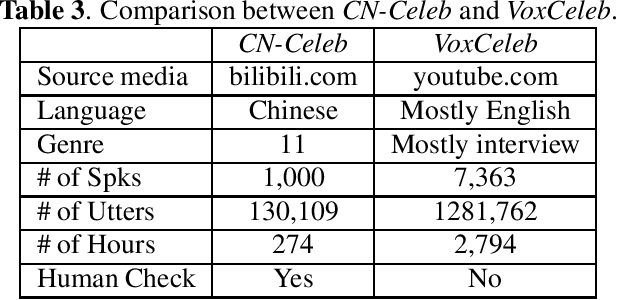

Recently, researchers set an ambitious goal of conducting speaker recognition in unconstrained conditions where the variations on ambient, channel and emotion could be arbitrary. However, most publicly available datasets are collected under constrained environments, i.e., with little noise and limited channel variation. These datasets tend to deliver over optimistic performance and do not meet the request of research on speaker recognition in unconstrained conditions. In this paper, we present CN-Celeb, a large-scale speaker recognition dataset collected `in the wild'. This dataset contains more than 130,000 utterances from 1,000 Chinese celebrities, and covers 11 different genres in real world. Experiments conducted with two state-of-the-art speaker recognition approaches (i-vector and x-vector) show that the performance on CN-Celeb is far inferior to the one obtained on VoxCeleb, a widely used speaker recognition dataset. This result demonstrates that in real-life conditions, the performance of existing techniques might be much worse than it was thought. Our database is free for researchers and can be downloaded from http://project.cslt.org.