 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Reasoning with Collaboration and Memory
Mar 07, 2025



We envision a continuous collaborative learning system where groups of LLM agents work together to solve reasoning problems, drawing on memory they collectively build to improve performance as they gain experience. This work establishes the foundations for such a system by studying the interoperability of chain-of-thought reasoning styles, multi-agent collaboration, and memory banks. Extending beyond the identical agents of self-consistency, we introduce varied-context agents with diverse exemplars and a summarizer agent in place of voting. We generate frozen and continuously learned memory banks of exemplars and pair them with fixed, random, and similarity-based retrieval mechanisms. Our systematic study reveals where various methods contribute to reasoning performance of two LLMs on three grounded reasoning tasks, showing that random exemplar selection can often beat more principled approaches, and in some tasks, inclusion of any exemplars serves only to distract both weak and strong models.
CI-Bench: Benchmarking Contextual Integrity of AI Assistants on Synthetic Data
Sep 20, 2024



Advances in generative AI point towards a new era of personalized applications that perform diverse tasks on behalf of users. While general AI assistants have yet to fully emerge, their potential to share personal data raises significant privacy challenges. This paper introduces CI-Bench, a comprehensive synthetic benchmark for evaluating the ability of AI assistants to protect personal information during model inference. Leveraging the Contextual Integrity framework, our benchmark enables systematic assessment of information flow across important context dimensions, including roles, information types, and transmission principles. We present a novel, scalable, multi-step synthetic data pipeline for generating natural communications, including dialogues and emails. Unlike previous work with smaller, narrowly focused evaluations, we present a novel, scalable, multi-step data pipeline that synthetically generates natural communications, including dialogues and emails, which we use to generate 44 thousand test samples across eight domains. Additionally, we formulate and evaluate a naive AI assistant to demonstrate the need for further study and careful training towards personal assistant tasks. We envision CI-Bench as a valuable tool for guiding future language model development, deployment, system design, and dataset construction, ultimately contributing to the development of AI assistants that align with users' privacy expectations.
Massively Scalable Inverse Reinforcement Learning in Google Maps
May 24, 2023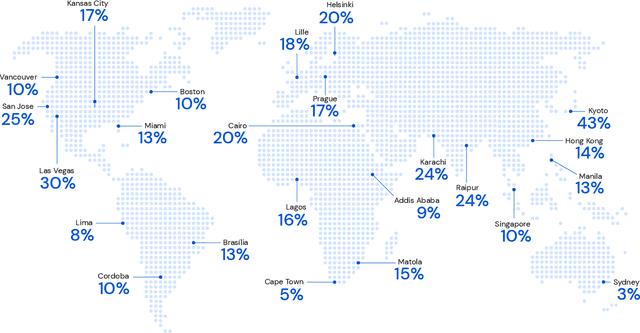
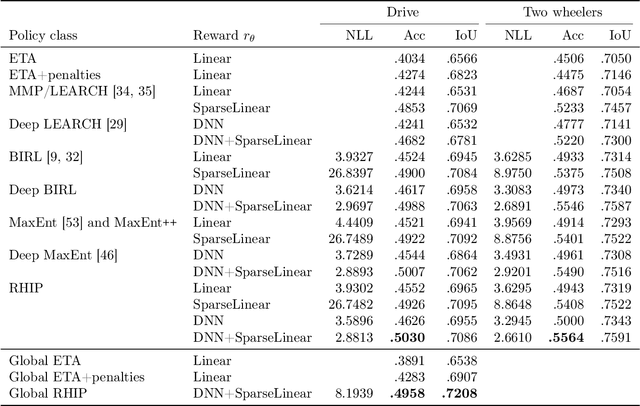
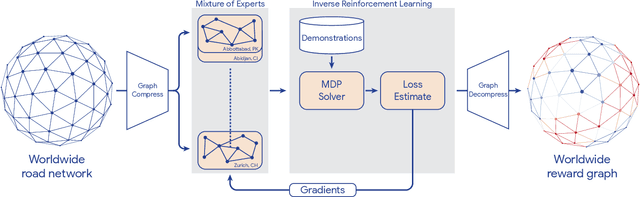

Optimizing for humans' latent preferences is a grand challenge in route recommendation, where globally-scalable solutions remain an open problem. Although past work created increasingly general solutions for the application of inverse reinforcement learning (IRL), these have not been successfully scaled to world-sized MDPs, large datasets, and highly parameterized models; respectively hundreds of millions of states, trajectories, and parameters. In this work, we surpass previous limitations through a series of advancements focused on graph compression, parallelization, and problem initialization based on dominant eigenvectors. We introduce Receding Horizon Inverse Planning (RHIP), which generalizes existing work and enables control of key performance trade-offs via its planning horizon. Our policy achieves a 16-24% improvement in global route quality, and, to our knowledge, represents the largest instance of IRL in a real-world setting to date. Our results show critical benefits to more sustainable modes of transportation (e.g. two-wheelers), where factors beyond journey time (e.g. route safety) play a substantial role. We conclude with ablations of key components, negative results on state-of-the-art eigenvalue solvers, and identify future opportunities to improve scalability via IRL-specific batching strategies.