 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackground-aware Classification Activation Map for Weakly Supervised Object Localization
Dec 29, 2021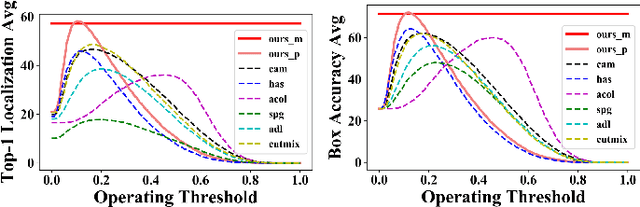
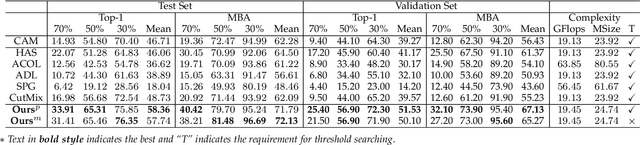

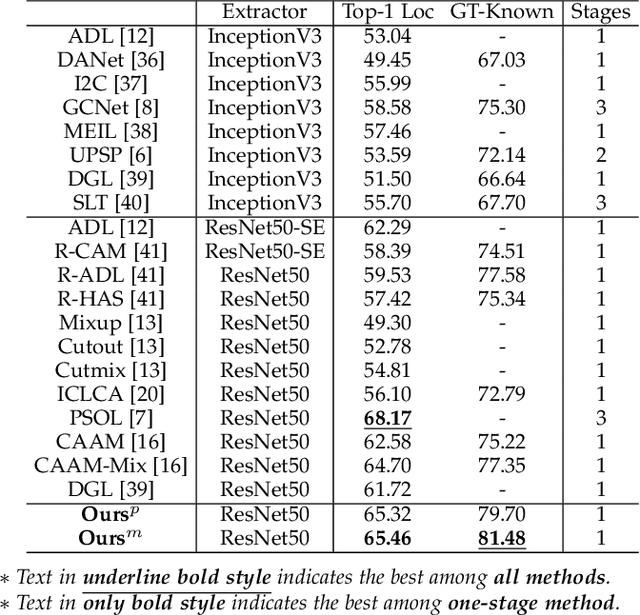
Weakly supervised object localization (WSOL) relaxes the requirement of dense annotations for object localization by using image-level classification masks to supervise its learning process. However, current WSOL methods suffer from excessive activation of background locations and need post-processing to obtain the localization mask. This paper attributes these issues to the unawareness of background cues, and propose the background-aware classification activation map (B-CAM) to simultaneously learn localization scores of both object and background with only image-level labels. In our B-CAM, two image-level features, aggregated by pixel-level features of potential background and object locations, are used to purify the object feature from the object-related background and to represent the feature of the pure-background sample, respectively. Then based on these two features, both the object classifier and the background classifier are learned to determine the binary object localization mask. Our B-CAM can be trained in end-to-end manner based on a proposed stagger classification loss, which not only improves the objects localization but also suppresses the background activation. Experiments show that our B-CAM outperforms one-stage WSOL methods on the CUB-200, OpenImages and VOC2012 datasets.
A Label Management Mechanism for Retinal Fundus Image Classification of Diabetic Retinopathy
Jun 23, 2021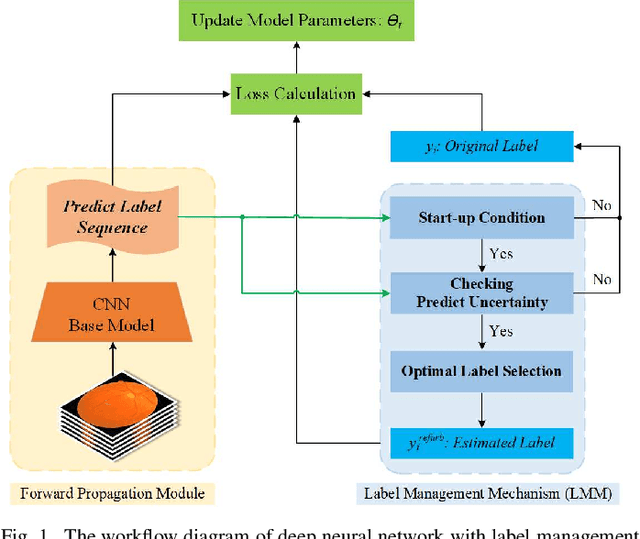
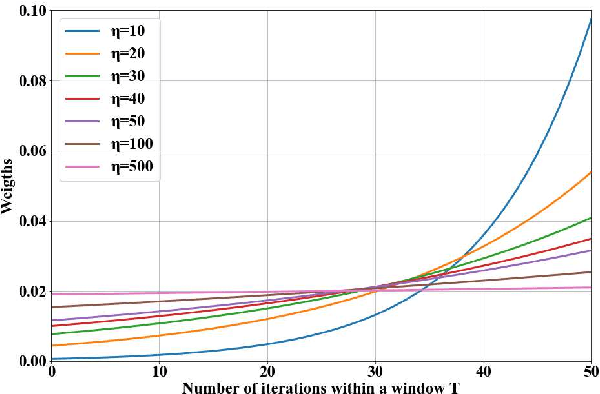
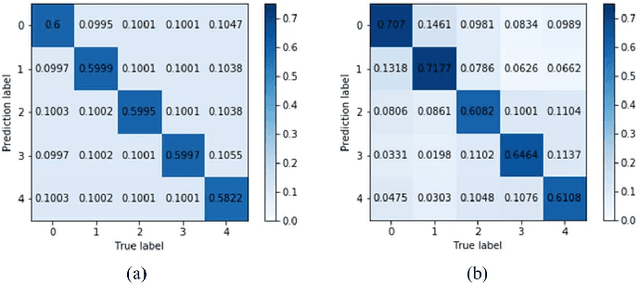
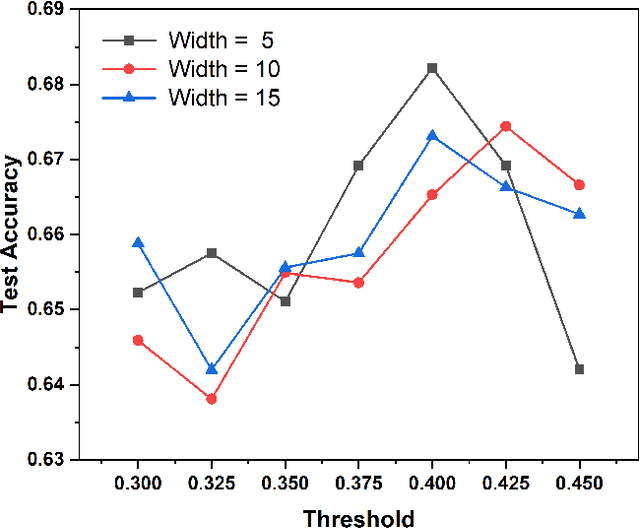
Diabetic retinopathy (DR) remains the most prevalent cause of vision impairment and irreversible blindness in the working-age adults. Due to the renaissance of deep learning (DL), DL-based DR diagnosis has become a promising tool for the early screening and severity grading of DR. However, training deep neural networks (DNNs) requires an enormous amount of carefully labeled data. Noisy label data may be introduced when labeling plenty of data, degrading the performance of models. In this work, we propose a novel label management mechanism (LMM) for the DNN to overcome overfitting on the noisy data. LMM utilizes maximum posteriori probability (MAP) in the Bayesian statistic and time-weighted technique to selectively correct the labels of unclean data, which gradually purify the training data and improve classification performance. Comprehensive experiments on both synthetic noise data (Messidor \& our collected DR dataset) and real-world noise data (ANIMAL-10N) demonstrated that LMM could boost performance of models and is superior to three state-of-the-art methods.