 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Conditional Diffusion for Motion-Robust Retinal Temporal Laser Speckle Contrast Imaging
Apr 22, 2026Retinal laser speckle contrast imaging (LSCI) is a noninvasive optical modality for monitoring retinal blood flow dynamics. However, conventional temporal LSCI (tLSCI) reconstruction relies on sufficiently long speckle sequences to obtain stable temporal statistics, which makes it vulnerable to acquisition disturbances and limits effective temporal resolution. A physically informed reconstruction framework, termed RetinaDiff (Retinal Diffusion Model), is proposed for retinal tLSCI that is robust to motion and requires only a few frames. In RetinaDiff, registration based on phase correlation is first applied to stabilize the raw speckle sequence before contrast computation, reducing interframe misalignment so that fluctuations at each pixel primarily reflect true flow dynamics. This step provides a physics prior corrected for motion and a high quality multiframe tLSCI reference. Next, guided by the physics prior, a conditional diffusion model performs inverse reconstruction by jointly conditioning on the registered speckle sequence and the corrected prior. Experiments on data acquired with a retinal LSCI system developed in house show improved structural continuity and statistical stability compared with direct reconstruction from few frames and representative baselines. The framework also remains effective in a small number of extremely challenging cases, where both the direct 5-frame input and the conventional multiframe reconstruction are severely degraded. Overall, this work provides a practical and physically grounded route for reliable retinal tLSCI reconstruction from extremely limited frames. The source code and model weights will be publicly available at https://github.com/QianChen113/RetinaDiff.
RADA: Region-Aware Dual-encoder Auxiliary learning for Barely-supervised Medical Image Segmentation
Apr 13, 2026Deep learning has greatly advanced medical image segmentation, but its success relies heavily on fully supervised learning, which requires dense annotations that are costly and time-consuming for 3D volumetric scans. Barely-supervised learning reduces annotation burden by using only a few labeled slices per volume. Existing methods typically propagate sparse annotations to unlabeled slices through geometric continuity to generate pseudo-labels, but this strategy lacks semantic understanding, often resulting in low-quality pseudo-labels. Furthermore, medical image segmentation is inherently a pixel-level visual understanding task, where accuracy fundamentally depends on the quality of local, fine-grained visual features. Inspired by this, we propose RADA, a novel Region-Aware Dual-encoder Auxiliary learning pipeline which introduces a dual-encoder framework pre-trained on Alpha-CLIP to extract fine-grained, region-specific visual features from the original images and limited annotations. The framework combines image-level fine-grained visual features with text-level semantic guidance, providing region-aware semantic supervision that bridges image-level semantics and pixel-level segmentation. Integrated into a triple-view training framework, RADA achieves SOTA performance under extremely sparse annotation settings on LA2018, KiTS19 and LiTS, demonstrating robust generalization across diverse datasets.
Geometry-as-context: Modulating Explicit 3D in Scene-consistent Video Generation to Geometry Context
Feb 25, 2026Scene-consistent video generation aims to create videos that explore 3D scenes based on a camera trajectory. Previous methods rely on video generation models with external memory for consistency, or iterative 3D reconstruction and inpainting, which accumulate errors during inference due to incorrect intermediary outputs, non-differentiable processes, and separate models. To overcome these limitations, we introduce ``geometry-as-context". It iteratively completes the following steps using an autoregressive camera-controlled video generation model: (1) estimates the geometry of the current view necessary for 3D reconstruction, and (2) simulates and restores novel view images rendered by the 3D scene. Under this multi-task framework, we develop the camera gated attention module to enhance the model's capability to effectively leverage camera poses. During the training phase, text contexts are utilized to ascertain whether geometric or RGB images should be generated. To ensure that the model can generate RGB-only outputs during inference, the geometry context is randomly dropped from the interleaved text-image-geometry training sequence. The method has been tested on scene video generation with one-direction and forth-and-back trajectories. The results show its superiority over previous approaches in maintaining scene consistency and camera control.
Bridging Degradation Discrimination and Generation for Universal Image Restoration
Jan 31, 2026Universal image restoration is a critical task in low-level vision, requiring the model to remove various degradations from low-quality images to produce clean images with rich detail. The challenges lie in sampling the distribution of high-quality images and adjusting the outputs on the basis of the degradation. This paper presents a novel approach, Bridging Degradation discrimination and Generation (BDG), which aims to address these challenges concurrently. First, we propose the Multi-Angle and multi-Scale Gray Level Co-occurrence Matrix (MAS-GLCM) and demonstrate its effectiveness in performing fine-grained discrimination of degradation types and levels. Subsequently, we divide the diffusion training process into three distinct stages: generation, bridging, and restoration. The objective is to preserve the diffusion model's capability of restoring rich textures while simultaneously integrating the discriminative information from the MAS-GLCM into the restoration process. This enhances its proficiency in addressing multi-task and multi-degraded scenarios. Without changing the architecture, BDG achieves significant performance gains in all-in-one restoration and real-world super-resolution tasks, primarily evidenced by substantial improvements in fidelity without compromising perceptual quality. The code and pretrained models are provided in https://github.com/MILab-PKU/BDG.
Bridging Information Asymmetry: A Hierarchical Framework for Deterministic Blind Face Restoration
Jan 27, 2026Blind face restoration remains a persistent challenge due to the inherent ill-posedness of reconstructing holistic structures from severely constrained observations. Current generative approaches, while capable of synthesizing realistic textures, often suffer from information asymmetry -- the intrinsic disparity between the information-sparse low quality inputs and the information-dense high quality outputs. This imbalance leads to a one-to-many mapping, where insufficient constraints result in stochastic uncertainty and hallucinatory artifacts. To bridge this gap, we present \textbf{Pref-Restore}, a hierarchical framework that integrates discrete semantic logic with continuous texture generation to achieve deterministic, preference-aligned restoration. Our methodology fundamentally addresses this information disparity through two complementary strategies: (1) Augmenting Input Density: We employ an auto-regressive integrator to reformulate textual instructions into dense latent queries, injecting high-level semantic stability to constrain the degraded signals; (2) Pruning Output Distribution: We pioneer the integration of on-policy reinforcement learning directly into the diffusion restoration loop. By transforming human preferences into differentiable constraints, we explicitly penalize stochastic deviations, thereby sharpening the posterior distribution toward the desired high-fidelity outcomes. Extensive experiments demonstrate that Pref-Restore achieves state-of-the-art performance across synthetic and real-world benchmarks. Furthermore, empirical analysis confirms that our preference-aligned strategy significantly reduces solution entropy, establishing a robust pathway toward reliable and deterministic blind restoration.
AdaTok: Adaptive Token Compression with Object-Aware Representations for Efficient Multimodal LLMs
Nov 18, 2025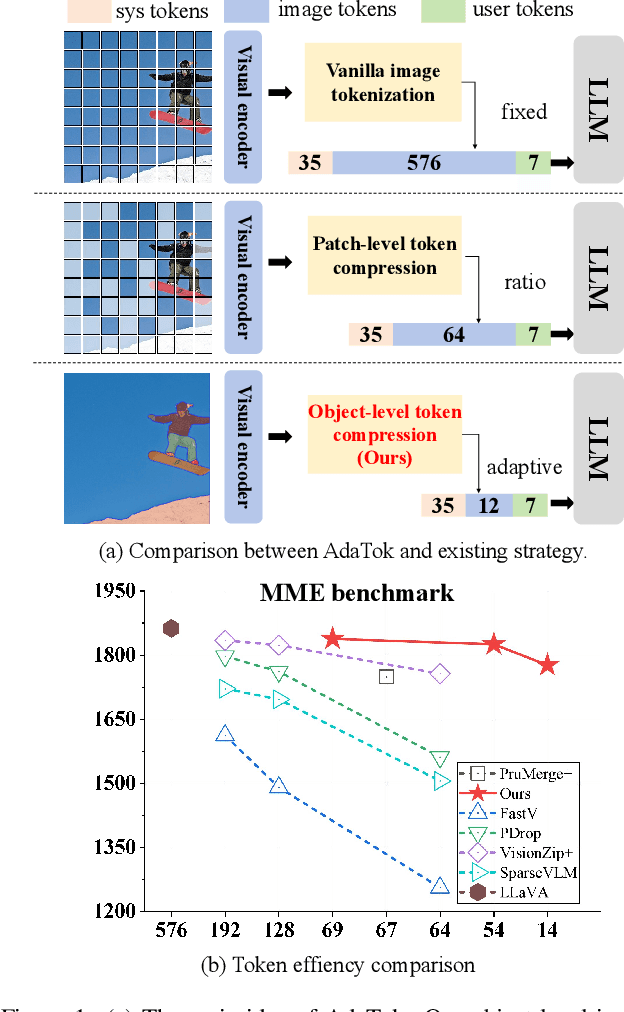
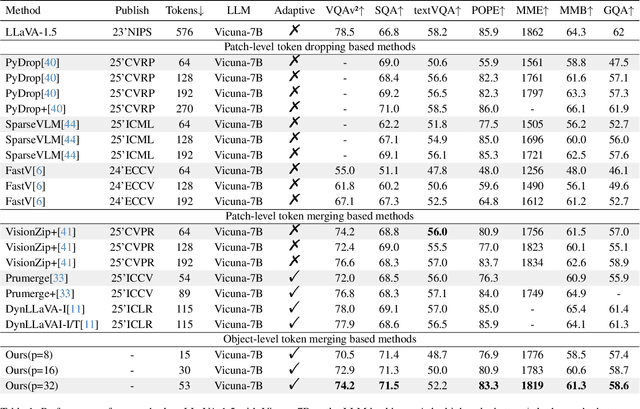
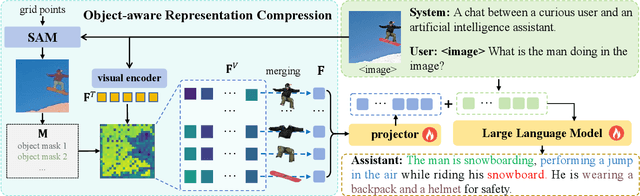
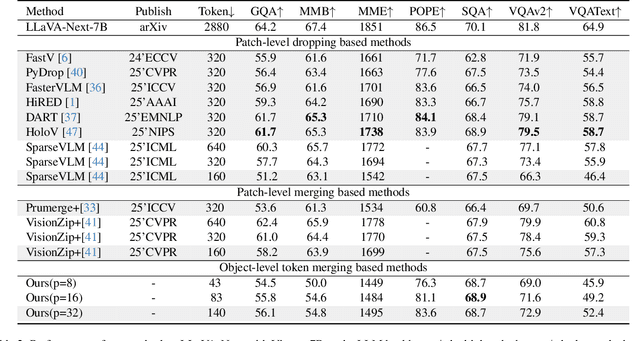
Multimodal Large Language Models (MLLMs) have demonstrated substantial value in unified text-image understanding and reasoning, primarily by converting images into sequences of patch-level tokens that align with their architectural paradigm. However, patch-level tokenization leads to a quadratic growth in image tokens, burdening MLLMs' understanding and reasoning with enormous computation and memory. Additionally, the traditional patch-wise scanning tokenization workflow misaligns with the human vision cognition system, further leading to hallucination and computational redundancy. To address this issue, we propose an object-level token merging strategy for Adaptive Token compression, revealing the consistency with human vision system. The experiments are conducted on multiple comprehensive benchmarks, which show that our approach averagely, utilizes only 10% tokens while achieving almost 96% of the vanilla model's performance. More extensive experimental results in comparison with relevant works demonstrate the superiority of our method in balancing compression ratio and performance. Our code will be available.
Omni-View: Unlocking How Generation Facilitates Understanding in Unified 3D Model based on Multiview images
Nov 10, 2025This paper presents Omni-View, which extends the unified multimodal understanding and generation to 3D scenes based on multiview images, exploring the principle that "generation facilitates understanding". Consisting of understanding model, texture module, and geometry module, Omni-View jointly models scene understanding, novel view synthesis, and geometry estimation, enabling synergistic interaction between 3D scene understanding and generation tasks. By design, it leverages the spatiotemporal modeling capabilities of its texture module responsible for appearance synthesis, alongside the explicit geometric constraints provided by its dedicated geometry module, thereby enriching the model's holistic understanding of 3D scenes. Trained with a two-stage strategy, Omni-View achieves a state-of-the-art score of 55.4 on the VSI-Bench benchmark, outperforming existing specialized 3D understanding models, while simultaneously delivering strong performance in both novel view synthesis and 3D scene generation.
Novel Extraction of Discriminative Fine-Grained Feature to Improve Retinal Vessel Segmentation
May 06, 2025Retinal vessel segmentation is a vital early detection method for several severe ocular diseases. Despite significant progress in retinal vessel segmentation with the advancement of Neural Networks, there are still challenges to overcome. Specifically, retinal vessel segmentation aims to predict the class label for every pixel within a fundus image, with a primary focus on intra-image discrimination, making it vital for models to extract more discriminative features. Nevertheless, existing methods primarily focus on minimizing the difference between the output from the decoder and the label, but ignore fully using feature-level fine-grained representations from the encoder. To address these issues, we propose a novel Attention U-shaped Kolmogorov-Arnold Network named AttUKAN along with a novel Label-guided Pixel-wise Contrastive Loss for retinal vessel segmentation. Specifically, we implement Attention Gates into Kolmogorov-Arnold Networks to enhance model sensitivity by suppressing irrelevant feature activations and model interpretability by non-linear modeling of KAN blocks. Additionally, we also design a novel Label-guided Pixel-wise Contrastive Loss to supervise our proposed AttUKAN to extract more discriminative features by distinguishing between foreground vessel-pixel pairs and background pairs. Experiments are conducted across four public datasets including DRIVE, STARE, CHASE_DB1, HRF and our private dataset. AttUKAN achieves F1 scores of 82.50%, 81.14%, 81.34%, 80.21% and 80.09%, along with MIoU scores of 70.24%, 68.64%, 68.59%, 67.21% and 66.94% in the above datasets, which are the highest compared to 11 networks for retinal vessel segmentation. Quantitative and qualitative results show that our AttUKAN achieves state-of-the-art performance and outperforms existing retinal vessel segmentation methods. Our code will be available at https://github.com/stevezs315/AttUKAN.
SuperCL: Superpixel Guided Contrastive Learning for Medical Image Segmentation Pre-training
Apr 20, 2025Medical image segmentation is a critical yet challenging task, primarily due to the difficulty of obtaining extensive datasets of high-quality, expert-annotated images. Contrastive learning presents a potential but still problematic solution to this issue. Because most existing methods focus on extracting instance-level or pixel-to-pixel representation, which ignores the characteristics between intra-image similar pixel groups. Moreover, when considering contrastive pairs generation, most SOTA methods mainly rely on manually setting thresholds, which requires a large number of gradient experiments and lacks efficiency and generalization. To address these issues, we propose a novel contrastive learning approach named SuperCL for medical image segmentation pre-training. Specifically, our SuperCL exploits the structural prior and pixel correlation of images by introducing two novel contrastive pairs generation strategies: Intra-image Local Contrastive Pairs (ILCP) Generation and Inter-image Global Contrastive Pairs (IGCP) Generation. Considering superpixel cluster aligns well with the concept of contrastive pairs generation, we utilize the superpixel map to generate pseudo masks for both ILCP and IGCP to guide supervised contrastive learning. Moreover, we also propose two modules named Average SuperPixel Feature Map Generation (ASP) and Connected Components Label Generation (CCL) to better exploit the prior structural information for IGCP. Finally, experiments on 8 medical image datasets indicate our SuperCL outperforms existing 12 methods. i.e. Our SuperCL achieves a superior performance with more precise predictions from visualization figures and 3.15%, 5.44%, 7.89% DSC higher than the previous best results on MMWHS, CHAOS, Spleen with 10% annotations. Our code will be released after acceptance.
Exploiting Inherent Class Label: Towards Robust Scribble Supervised Semantic Segmentation
Mar 18, 2025Scribble-based weakly supervised semantic segmentation leverages only a few annotated pixels as labels to train a segmentation model, presenting significant potential for reducing the human labor involved in the annotation process. This approach faces two primary challenges: first, the sparsity of scribble annotations can lead to inconsistent predictions due to limited supervision; second, the variability in scribble annotations, reflecting differing human annotator preferences, can prevent the model from consistently capturing the discriminative regions of objects, potentially leading to unstable predictions. To address these issues, we propose a holistic framework, the class-driven scribble promotion network, for robust scribble-supervised semantic segmentation. This framework not only utilizes the provided scribble annotations but also leverages their associated class labels to generate reliable pseudo-labels. Within the network, we introduce a localization rectification module to mitigate noisy labels and a distance perception module to identify reliable regions surrounding scribble annotations and pseudo-labels. In addition, we introduce new large-scale benchmarks, ScribbleCOCO and ScribbleCityscapes, accompanied by a scribble simulation algorithm that enables evaluation across varying scribble styles. Our method demonstrates competitive performance in both accuracy and robustness, underscoring its superiority over existing approaches. The datasets and the codes will be made publicly available.