 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Inherent Class Label: Towards Robust Scribble Supervised Semantic Segmentation
Mar 18, 2025Scribble-based weakly supervised semantic segmentation leverages only a few annotated pixels as labels to train a segmentation model, presenting significant potential for reducing the human labor involved in the annotation process. This approach faces two primary challenges: first, the sparsity of scribble annotations can lead to inconsistent predictions due to limited supervision; second, the variability in scribble annotations, reflecting differing human annotator preferences, can prevent the model from consistently capturing the discriminative regions of objects, potentially leading to unstable predictions. To address these issues, we propose a holistic framework, the class-driven scribble promotion network, for robust scribble-supervised semantic segmentation. This framework not only utilizes the provided scribble annotations but also leverages their associated class labels to generate reliable pseudo-labels. Within the network, we introduce a localization rectification module to mitigate noisy labels and a distance perception module to identify reliable regions surrounding scribble annotations and pseudo-labels. In addition, we introduce new large-scale benchmarks, ScribbleCOCO and ScribbleCityscapes, accompanied by a scribble simulation algorithm that enables evaluation across varying scribble styles. Our method demonstrates competitive performance in both accuracy and robustness, underscoring its superiority over existing approaches. The datasets and the codes will be made publicly available.
Modality-Projection Universal Model for Comprehensive Full-Body Medical Imaging Segmentation
Dec 26, 2024The integration of deep learning in medical imaging has shown great promise for enhancing diagnostic, therapeutic, and research outcomes. However, applying universal models across multiple modalities remains challenging due to the inherent variability in data characteristics. This study aims to introduce and evaluate a Modality Projection Universal Model (MPUM). MPUM employs a novel modality-projection strategy, which allows the model to dynamically adjust its parameters to optimize performance across different imaging modalities. The MPUM demonstrated superior accuracy in identifying anatomical structures, enabling precise quantification for improved clinical decision-making. It also identifies metabolic associations within the brain-body axis, advancing research on brain-body physiological correlations. Furthermore, MPUM's unique controller-based convolution layer enables visualization of saliency maps across all network layers, significantly enhancing the model's interpretability.
Don't Fear Peculiar Activation Functions: EUAF and Beyond
Jul 12, 2024



In this paper, we propose a new super-expressive activation function called the Parametric Elementary Universal Activation Function (PEUAF). We demonstrate the effectiveness of PEUAF through systematic and comprehensive experiments on various industrial and image datasets, including CIFAR10, Tiny-ImageNet, and ImageNet. Moreover, we significantly generalize the family of super-expressive activation functions, whose existence has been demonstrated in several recent works by showing that any continuous function can be approximated to any desired accuracy by a fixed-size network with a specific super-expressive activation function. Specifically, our work addresses two major bottlenecks in impeding the development of super-expressive activation functions: the limited identification of super-expressive functions, which raises doubts about their broad applicability, and their often peculiar forms, which lead to skepticism regarding their scalability and practicality in real-world applications.
FP-PET: Large Model, Multiple Loss And Focused Practice
Sep 22, 2023This study presents FP-PET, a comprehensive approach to medical image segmentation with a focus on CT and PET images. Utilizing a dataset from the AutoPet2023 Challenge, the research employs a variety of machine learning models, including STUNet-large, SwinUNETR, and VNet, to achieve state-of-the-art segmentation performance. The paper introduces an aggregated score that combines multiple evaluation metrics such as Dice score, false positive volume (FPV), and false negative volume (FNV) to provide a holistic measure of model effectiveness. The study also discusses the computational challenges and solutions related to model training, which was conducted on high-performance GPUs. Preprocessing and postprocessing techniques, including gaussian weighting schemes and morphological operations, are explored to further refine the segmentation output. The research offers valuable insights into the challenges and solutions for advanced medical image segmentation.
Ultrasonic Image's Annotation Removal: A Self-supervised Noise2Noise Approach
Jul 09, 2023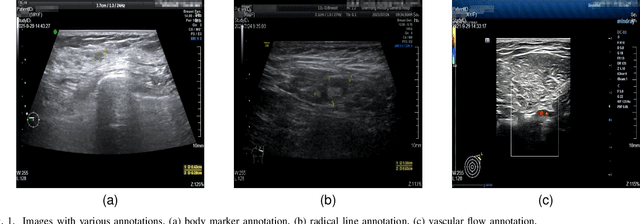
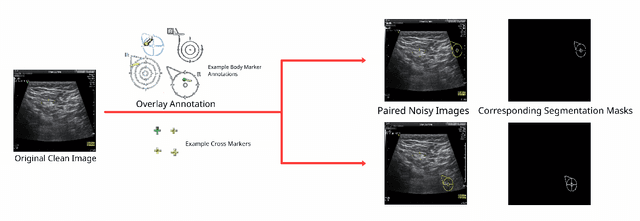
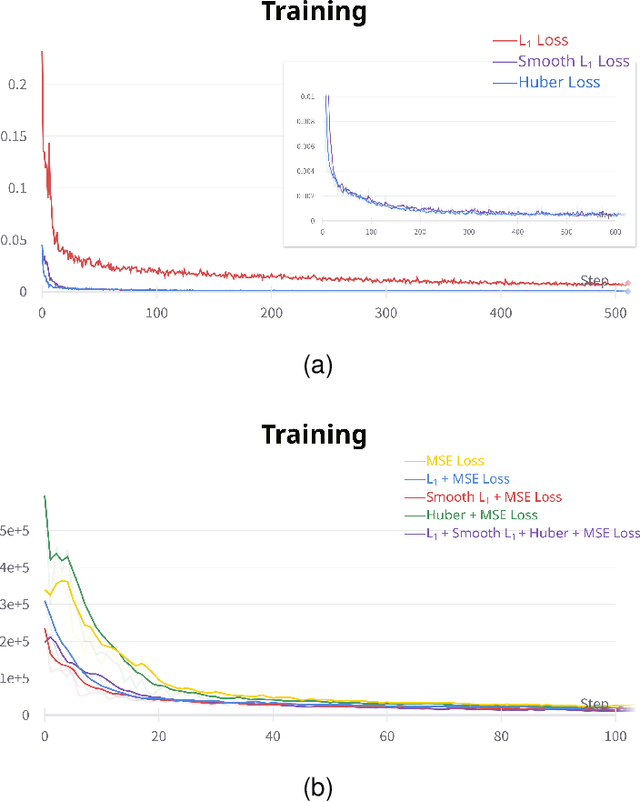
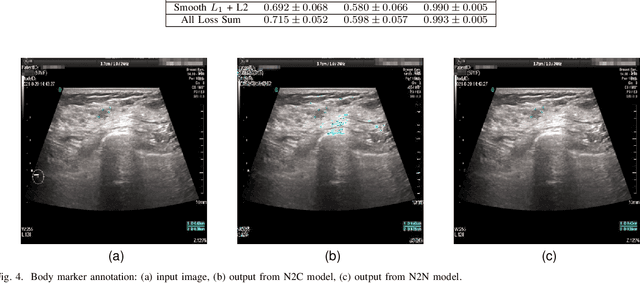
Accurately annotated ultrasonic images are vital components of a high-quality medical report. Hospitals often have strict guidelines on the types of annotations that should appear on imaging results. However, manually inspecting these images can be a cumbersome task. While a neural network could potentially automate the process, training such a model typically requires a dataset of paired input and target images, which in turn involves significant human labour. This study introduces an automated approach for detecting annotations in images. This is achieved by treating the annotations as noise, creating a self-supervised pretext task and using a model trained under the Noise2Noise scheme to restore the image to a clean state. We tested a variety of model structures on the denoising task against different types of annotation, including body marker annotation, radial line annotation, etc. Our results demonstrate that most models trained under the Noise2Noise scheme outperformed their counterparts trained with noisy-clean data pairs. The costumed U-Net yielded the most optimal outcome on the body marker annotation dataset, with high scores on segmentation precision and reconstruction similarity. We released our code at https://github.com/GrandArth/UltrasonicImage-N2N-Approach.
Label-noise-tolerant medical image classification via self-attention and self-supervised learning
Jun 16, 2023Deep neural networks (DNNs) have been widely applied in medical image classification and achieve remarkable classification performance. These achievements heavily depend on large-scale accurately annotated training data. However, label noise is inevitably introduced in the medical image annotation, as the labeling process heavily relies on the expertise and experience of annotators. Meanwhile, DNNs suffer from overfitting noisy labels, degrading the performance of models. Therefore, in this work, we innovatively devise noise-robust training approach to mitigate the adverse effects of noisy labels in medical image classification. Specifically, we incorporate contrastive learning and intra-group attention mixup strategies into the vanilla supervised learning. The contrastive learning for feature extractor helps to enhance visual representation of DNNs. The intra-group attention mixup module constructs groups and assigns self-attention weights for group-wise samples, and subsequently interpolates massive noisy-suppressed samples through weighted mixup operation. We conduct comparative experiments on both synthetic and real-world noisy medical datasets under various noise levels. Rigorous experiments validate that our noise-robust method with contrastive learning and attention mixup can effectively handle with label noise, and is superior to state-of-the-art methods. An ablation study also shows that both components contribute to boost model performance. The proposed method demonstrates its capability of curb label noise and has certain potential toward real-world clinic applications.