 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Targeted Therapy Resistance in Non-Small Cell Lung Cancer Using Multimodal Machine Learning
Mar 31, 2025Lung cancer is the primary cause of cancer death globally, with non-small cell lung cancer (NSCLC) emerging as its most prevalent subtype. Among NSCLC patients, approximately 32.3% have mutations in the epidermal growth factor receptor (EGFR) gene. Osimertinib, a third-generation EGFR-tyrosine kinase inhibitor (TKI), has demonstrated remarkable efficacy in the treatment of NSCLC patients with activating and T790M resistance EGFR mutations. Despite its established efficacy, drug resistance poses a significant challenge for patients to fully benefit from osimertinib. The absence of a standard tool to accurately predict TKI resistance, including that of osimertinib, remains a critical obstacle. To bridge this gap, in this study, we developed an interpretable multimodal machine learning model designed to predict patient resistance to osimertinib among late-stage NSCLC patients with activating EGFR mutations, achieving a c-index of 0.82 on a multi-institutional dataset. This machine learning model harnesses readily available data routinely collected during patient visits and medical assessments to facilitate precision lung cancer management and informed treatment decisions. By integrating various data types such as histology images, next generation sequencing (NGS) data, demographics data, and clinical records, our multimodal model can generate well-informed recommendations. Our experiment results also demonstrated the superior performance of the multimodal model over single modality models (c-index 0.82 compared with 0.75 and 0.77), thus underscoring the benefit of combining multiple modalities in patient outcome prediction.
Improving Colorectal Cancer Screening and Risk Assessment through Predictive Modeling on Medical Images and Records
Oct 13, 2024



Colonoscopy screening is an effective method to find and remove colon polyps before they can develop into colorectal cancer (CRC). Current follow-up recommendations, as outlined by the U.S. Multi-Society Task Force for individuals found to have polyps, primarily rely on histopathological characteristics, neglecting other significant CRC risk factors. Moreover, the considerable variability in colorectal polyp characterization among pathologists poses challenges in effective colonoscopy follow-up or surveillance. The evolution of digital pathology and recent advancements in deep learning provide a unique opportunity to investigate the added benefits of including the additional medical record information and automatic processing of pathology slides using computer vision techniques in the calculation of future CRC risk. Leveraging the New Hampshire Colonoscopy Registry's extensive dataset, many with longitudinal colonoscopy follow-up information, we adapted our recently developed transformer-based model for histopathology image analysis in 5-year CRC risk prediction. Additionally, we investigated various multimodal fusion techniques, combining medical record information with deep learning derived risk estimates. Our findings reveal that training a transformer model to predict intermediate clinical variables contributes to enhancing 5-year CRC risk prediction performance, with an AUC of 0.630 comparing to direct prediction. Furthermore, the fusion of imaging and non-imaging features, while not requiring manual inspection of microscopy images, demonstrates improved predictive capabilities for 5-year CRC risk comparing to variables extracted from colonoscopy procedure and microscopy findings. This study signifies the potential of integrating diverse data sources and advanced computational techniques in transforming the accuracy and effectiveness of future CRC risk assessments.
A Petri Dish for Histopathology Image Analysis
Jan 29, 2021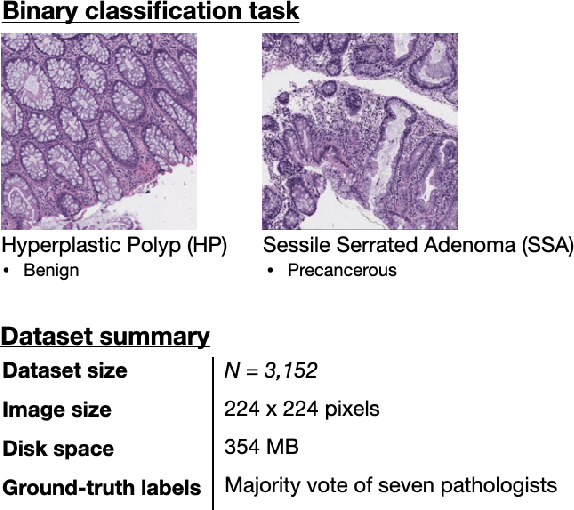
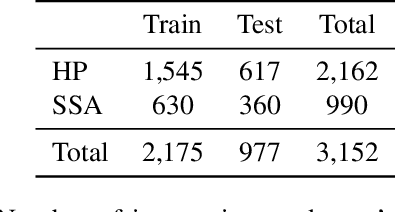
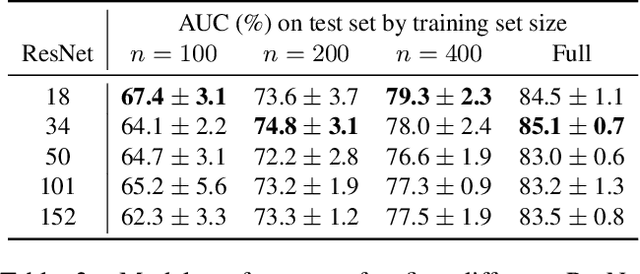
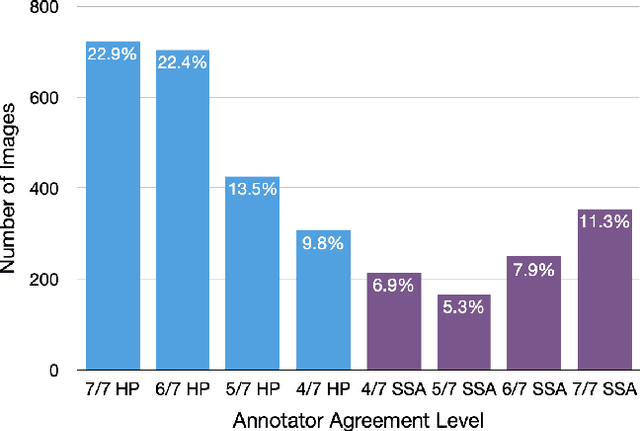
With the rise of deep learning, there has been increased interest in using neural networks for histopathology image analysis, a field that investigates the properties of biopsy or resected specimens that are traditionally manually examined under a microscope by pathologists. In histopathology image analysis, however, challenges such as limited data, costly annotation, and processing high-resolution and variable-size images create a high barrier of entry and make it difficult to quickly iterate over model designs. Throughout scientific history, many significant research directions have leveraged small-scale experimental setups as petri dishes to efficiently evaluate exploratory ideas, which are then validated in large-scale applications. For instance, the Drosophila fruit fly in genetics and MNIST in computer vision are well-known petri dishes. In this paper, we introduce a minimalist histopathology image analysis dataset (MHIST), an analogous petri dish for histopathology image analysis. MHIST is a binary classification dataset of 3,152 fixed-size images of colorectal polyps, each with a gold-standard label determined by the majority vote of seven board-certified gastrointestinal pathologists and annotator agreement level. MHIST occupies less than 400 MB of disk space, and a ResNet-18 baseline can be trained to convergence on MHIST in just 6 minutes using 3.5 GB of memory on a NVIDIA RTX 3090. As example use cases, we use MHIST to study natural questions such as how dataset size, network depth, transfer learning, and high-disagreement examples affect model performance. By introducing MHIST, we hope to not only help facilitate the work of current histopathology imaging researchers, but also make histopathology image analysis more accessible to the general computer vision community. Our dataset is available at https://bmirds.github.io/MHIST.
Learn like a Pathologist: Curriculum Learning by Annotator Agreement for Histopathology Image Classification
Sep 29, 2020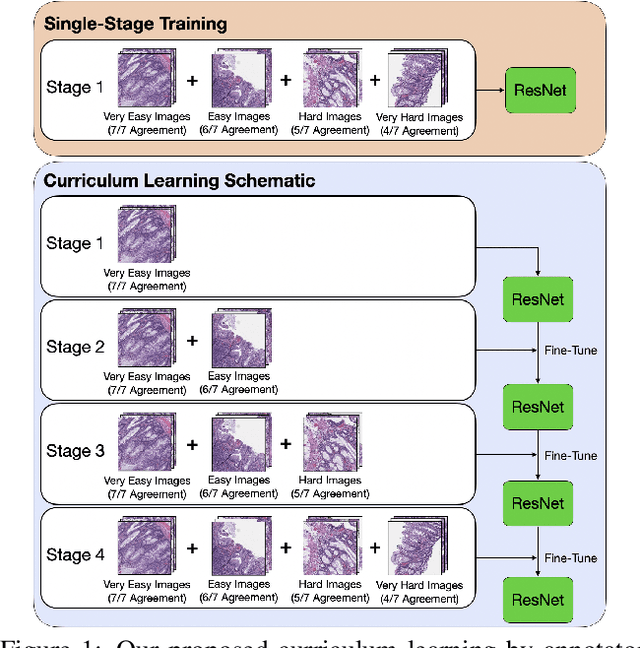
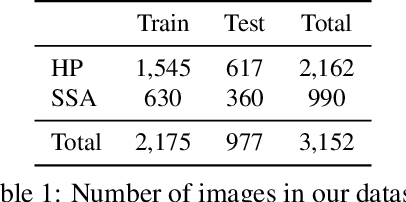
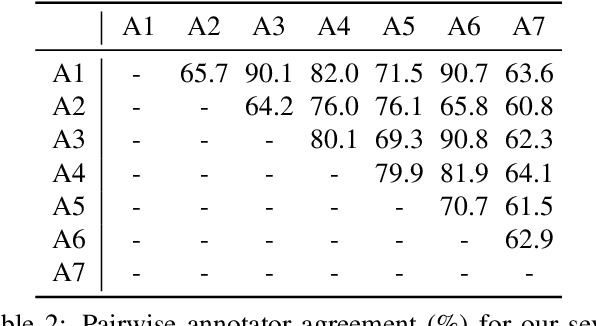
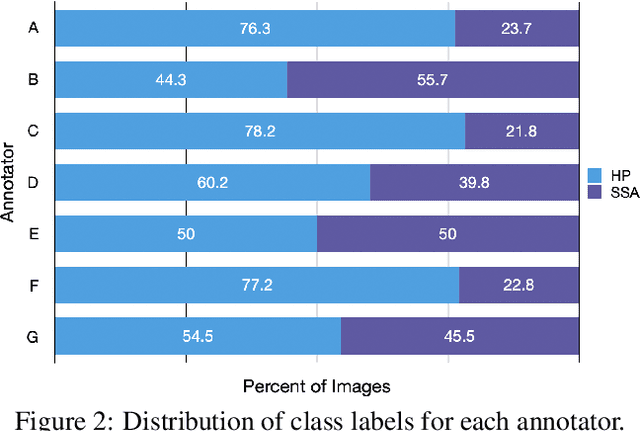
Applying curriculum learning requires both a range of difficulty in data and a method for determining the difficulty of examples. In many tasks, however, satisfying these requirements can be a formidable challenge. In this paper, we contend that histopathology image classification is a compelling use case for curriculum learning. Based on the nature of histopathology images, a range of difficulty inherently exists among examples, and, since medical datasets are often labeled by multiple annotators, annotator agreement can be used as a natural proxy for the difficulty of a given example. Hence, we propose a simple curriculum learning method that trains on progressively-harder images as determined by annotator agreement. We evaluate our hypothesis on the challenging and clinically-important task of colorectal polyp classification. Whereas vanilla training achieves an AUC of 83.7% for this task, a model trained with our proposed curriculum learning approach achieves an AUC of 88.2%, an improvement of 4.5%. Our work aims to inspire researchers to think more creatively and rigorously when choosing contexts for applying curriculum learning.
Difficulty Translation in Histopathology Images
Apr 27, 2020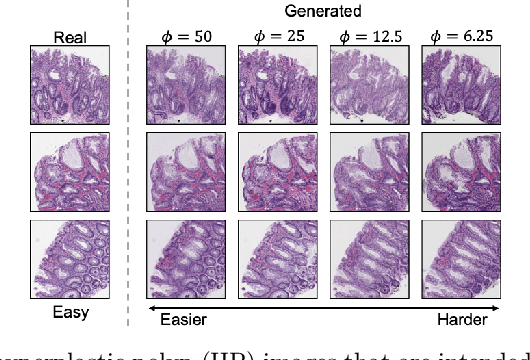

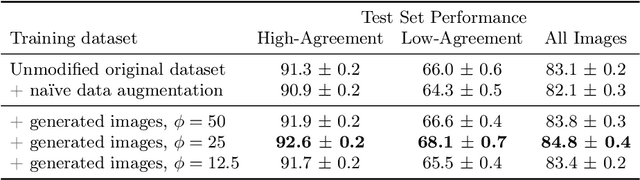
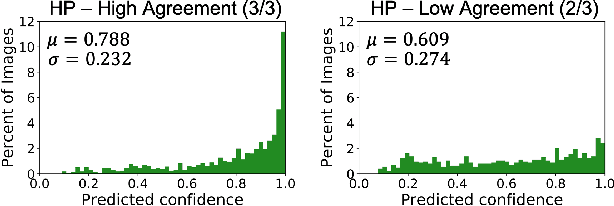
The unique nature of histopathology images opens the door to domain-specific formulations of image translation models. We propose a difficulty translation model that modifies colorectal histopathology images to become more challenging to classify. Our model comprises a scorer, which provides an output confidence to measure the difficulty of images, and an image translator, which learns to translate images from easy-to-classify to hard-to-classify using a training set defined by the scorer. We present three findings. First, generated images were indeed harder to classify for both human pathologists and machine learning classifiers than their corresponding source images. Second, image classifiers trained with generated images as augmented data performed better on both easy and hard images from an independent test set. Finally, human annotator agreement and our model's measure of difficulty correlated strongly, implying that for future work requiring human annotator agreement, the confidence score of a machine learning classifier could be used instead as a proxy.
Generative Image Translation for Data Augmentation in Colorectal Histopathology Images
Oct 13, 2019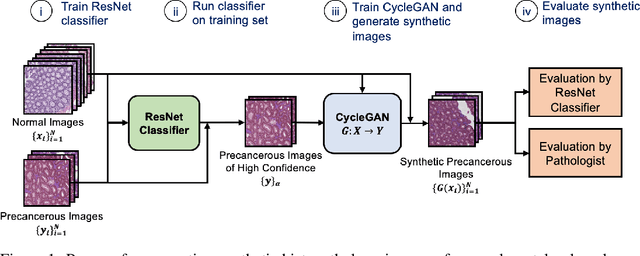
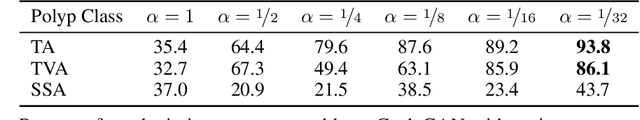
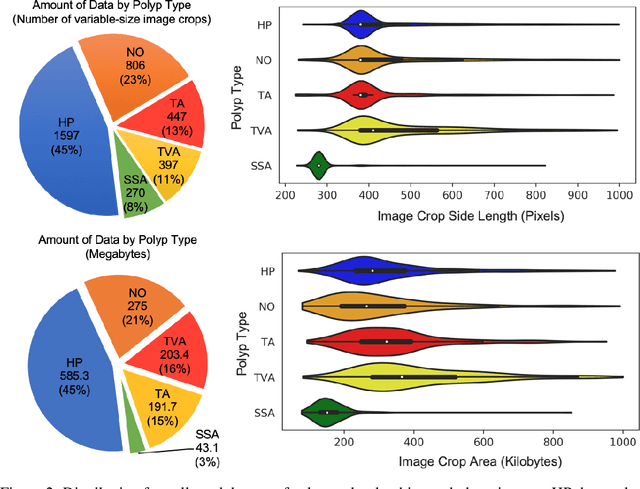
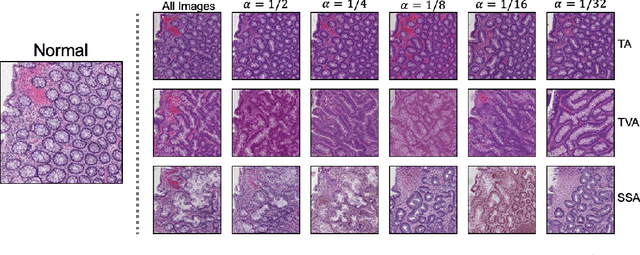
We present an image translation approach to generate augmented data for mitigating data imbalances in a dataset of histopathology images of colorectal polyps, adenomatous tumors that can lead to colorectal cancer if left untreated. By applying cycle-consistent generative adversarial networks (CycleGANs) to a source domain of normal colonic mucosa images, we generate synthetic colorectal polyp images that belong to diagnostically less common polyp classes. Generated images maintain the general structure of their source image but exhibit adenomatous features that can be enhanced with our proposed filtration module, called Path-Rank-Filter. We evaluate the quality of generated images through Turing tests with four gastrointestinal pathologists, finding that at least two of the four pathologists could not identify generated images at a statistically significant level. Finally, we demonstrate that using CycleGAN-generated images to augment training data improves the AUC of a convolutional neural network for detecting sessile serrated adenomas by over 10%, suggesting that our approach might warrant further research for other histopathology image classification tasks.
Finding a Needle in the Haystack: Attention-Based Classification of High Resolution Microscopy Images
Nov 20, 2018

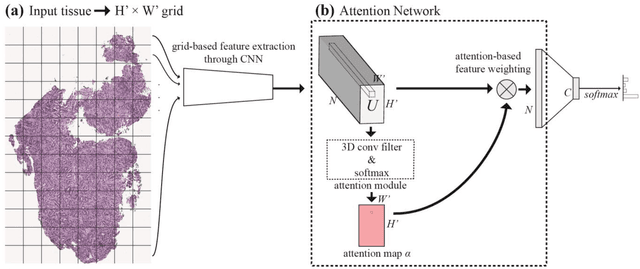
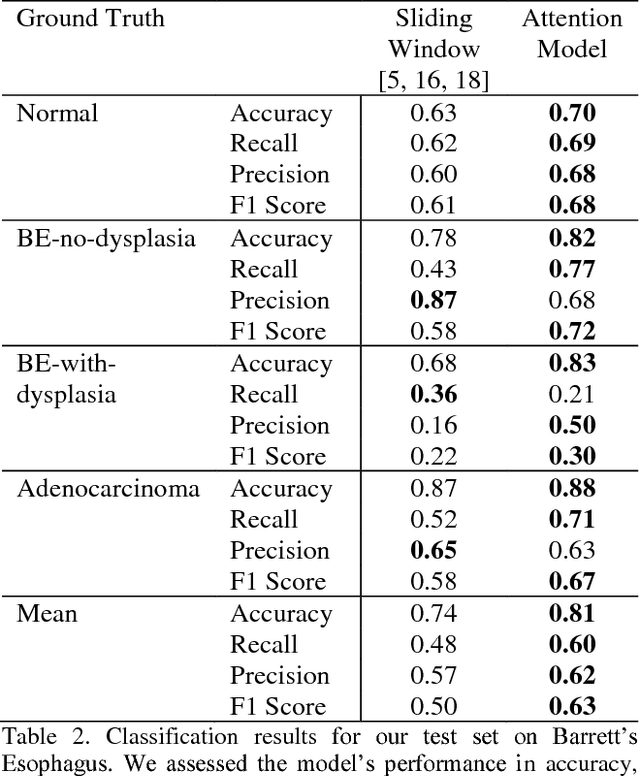
Deep learning for classification of microscopy images is challenging because whole-slide images are high resolution. Due to the large size of these images, they cannot be transferred into GPU memory, so there are currently no end-to-end deep learning architectures for their analysis. Existing work has used a sliding window for crop classification, followed by a heuristic to determine the label for the whole slide. This pipeline is not efficient or robust, however, because crops are analyzed independently of their neighbors and the decisive features for classifying a whole slide are only found in a few regions of interest. In this paper, we present an attention-based model for classification of high resolution microscopy images. Our model dynamically finds regions of interest from a wide-view, then identifies characteristic patterns in those regions for whole-slide classification. This approach is analogous to how pathologists examine slides under the microscope and is the first to generalize the attention mechanism to high resolution images. Furthermore, our model does not require bounding box annotations for the regions of interest and is trainable end-to-end with flexible input. We evaluated our model on a microscopy dataset of Barrett's Esophagus images, and the results showed that our approach outperforms the current state-of-the-art sliding window method by a large margin.