 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailored Federated Learning: Leveraging Direction Regulation & Knowledge Distillation
Sep 29, 2024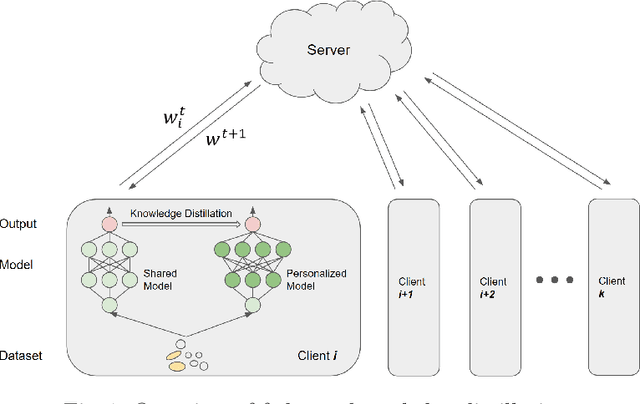
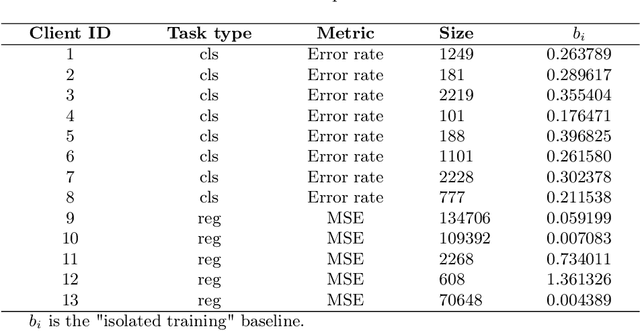
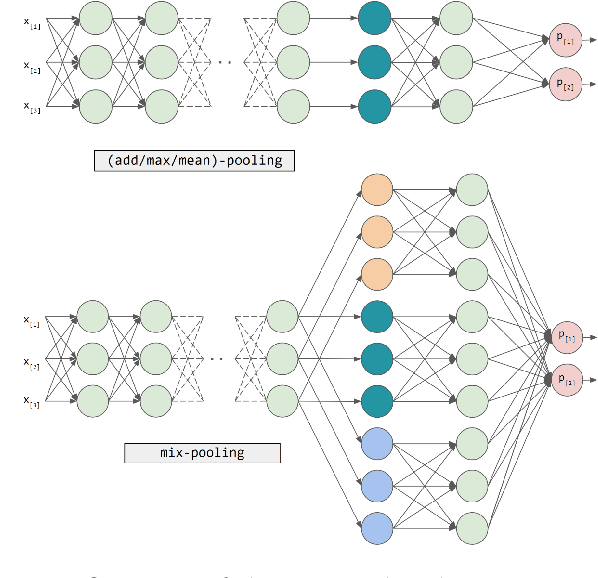
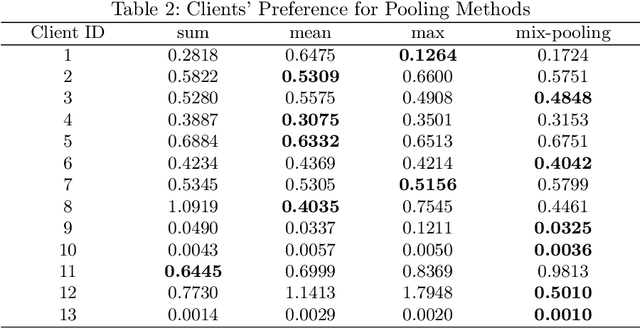
Federated learning (FL) has emerged as a transformative training paradigm, particularly invaluable in privacy-sensitive domains like healthcare. However, client heterogeneity in data, computing power, and tasks poses a significant challenge. To address such a challenge, we propose an FL optimization algorithm that integrates model delta regularization, personalized models, federated knowledge distillation, and mix-pooling. Model delta regularization optimizes model updates centrally on the server, efficiently updating clients with minimal communication costs. Personalized models and federated knowledge distillation strategies are employed to tackle task heterogeneity effectively. Additionally, mix-pooling is introduced to accommodate variations in the sensitivity of readout operations. Experimental results demonstrate the remarkable accuracy and rapid convergence achieved by model delta regularization. Additionally, the federated knowledge distillation algorithm notably improves FL performance, especially in scenarios with diverse data. Moreover, mix-pooling readout operations provide tangible benefits for clients, showing the effectiveness of our proposed methods.
Molecular Generative Adversarial Network with Multi-Property Optimization
Mar 29, 2024



Deep generative models, such as generative adversarial networks (GANs), have been employed for $de~novo$ molecular generation in drug discovery. Most prior studies have utilized reinforcement learning (RL) algorithms, particularly Monte Carlo tree search (MCTS), to handle the discrete nature of molecular representations in GANs. However, due to the inherent instability in training GANs and RL models, along with the high computational cost associated with MCTS sampling, MCTS RL-based GANs struggle to scale to large chemical databases. To tackle these challenges, this study introduces a novel GAN based on actor-critic RL with instant and global rewards, called InstGAN, to generate molecules at the token-level with multi-property optimization. Furthermore, maximized information entropy is leveraged to alleviate the mode collapse. The experimental results demonstrate that InstGAN outperforms other baselines, achieves comparable performance to state-of-the-art models, and efficiently generates molecules with multi-property optimization. The source code will be released upon acceptance of the paper.
A Visual Interpretation-Based Self-Improved Classification System Using Virtual Adversarial Training
Sep 03, 2023



The successful application of large pre-trained models such as BERT in natural language processing has attracted more attention from researchers. Since the BERT typically acts as an end-to-end black box, classification systems based on it usually have difficulty in interpretation and low robustness. This paper proposes a visual interpretation-based self-improving classification model with a combination of virtual adversarial training (VAT) and BERT models to address the above problems. Specifically, a fine-tuned BERT model is used as a classifier to classify the sentiment of the text. Then, the predicted sentiment classification labels are used as part of the input of another BERT for spam classification via a semi-supervised training manner using VAT. Additionally, visualization techniques, including visualizing the importance of words and normalizing the attention head matrix, are employed to analyze the relevance of each component to classification accuracy. Moreover, brand-new features will be found in the visual analysis, and classification performance will be improved. Experimental results on Twitter's tweet dataset demonstrate the effectiveness of the proposed model on the classification task. Furthermore, the ablation study results illustrate the effect of different components of the proposed model on the classification results.
Gathering an even number of robots in an odd ring without global multiplicity detection
Jun 17, 2012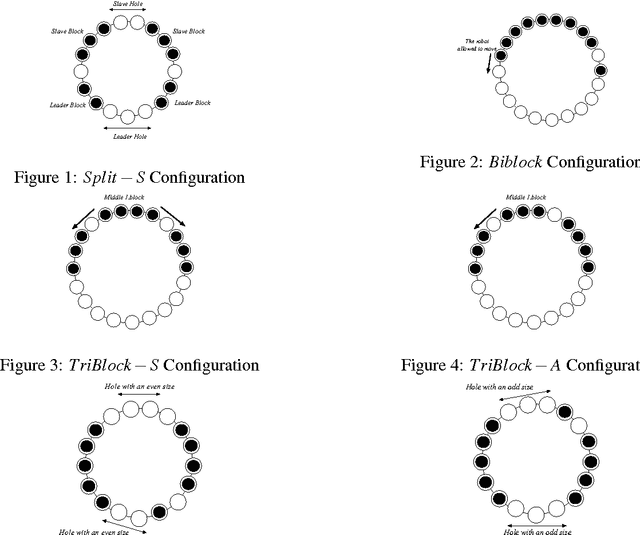
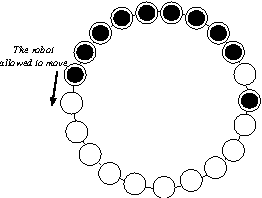
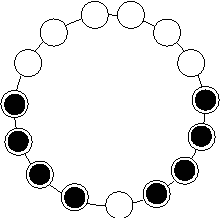
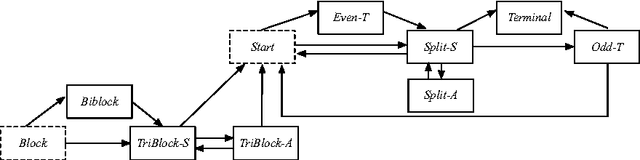
We propose a gathering protocol for an even number of robots in a ring-shaped network that allows symmetric but not periodic configurations as initial configurations, yet uses only local weak multiplicity detection. Robots are assumed to be anonymous and oblivious, and the execution model is the non- atomic CORDA model with asynchronous fair scheduling. In our scheme, the number of robots k must be greater than 8, the number of nodes n on a network must be odd and greater than k+3. The running time of our protocol is O(n2) asynchronous rounds.