 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailored Federated Learning: Leveraging Direction Regulation & Knowledge Distillation
Paper and Code
Sep 29, 2024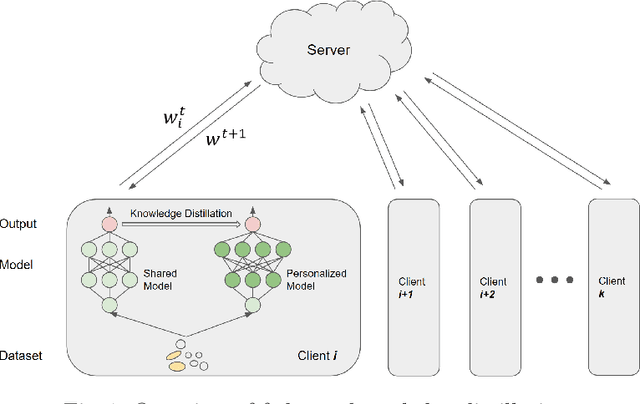
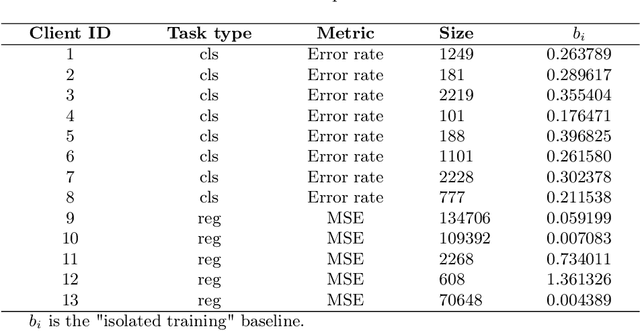
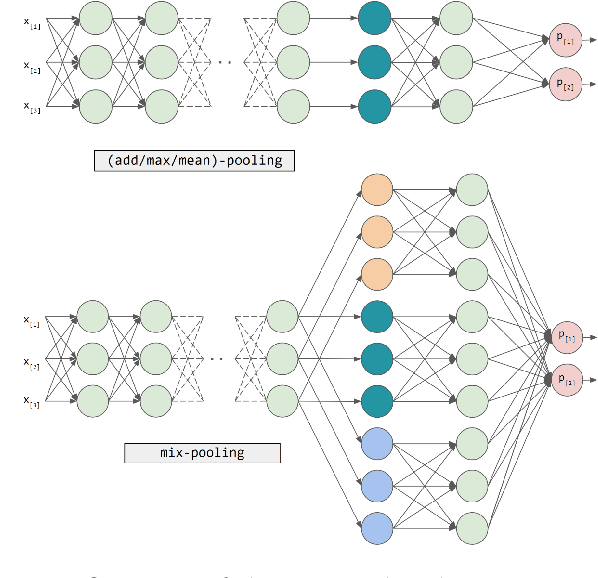
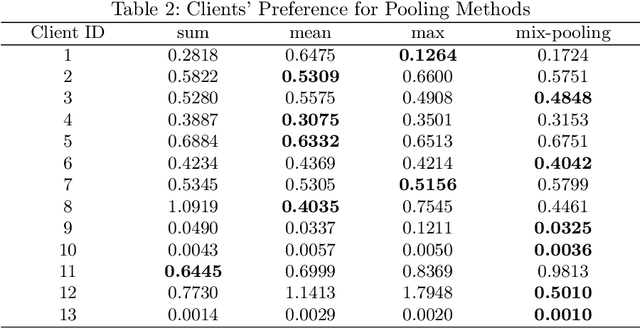
Federated learning (FL) has emerged as a transformative training paradigm, particularly invaluable in privacy-sensitive domains like healthcare. However, client heterogeneity in data, computing power, and tasks poses a significant challenge. To address such a challenge, we propose an FL optimization algorithm that integrates model delta regularization, personalized models, federated knowledge distillation, and mix-pooling. Model delta regularization optimizes model updates centrally on the server, efficiently updating clients with minimal communication costs. Personalized models and federated knowledge distillation strategies are employed to tackle task heterogeneity effectively. Additionally, mix-pooling is introduced to accommodate variations in the sensitivity of readout operations. Experimental results demonstrate the remarkable accuracy and rapid convergence achieved by model delta regularization. Additionally, the federated knowledge distillation algorithm notably improves FL performance, especially in scenarios with diverse data. Moreover, mix-pooling readout operations provide tangible benefits for clients, showing the effectiveness of our proposed methods.