 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUFO: Enhancing Diffusion-Based Video Generation with a Uniform Frame Organizer
Dec 12, 2024
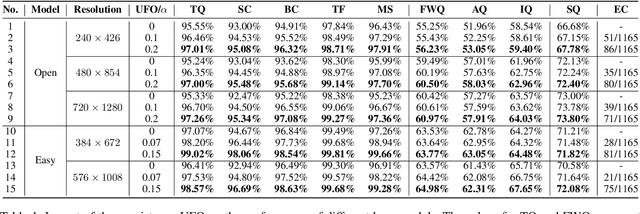
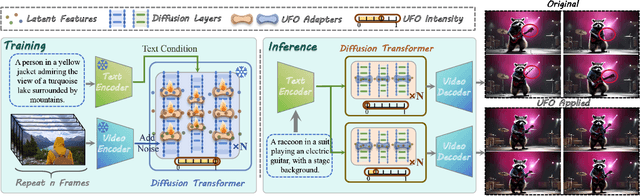
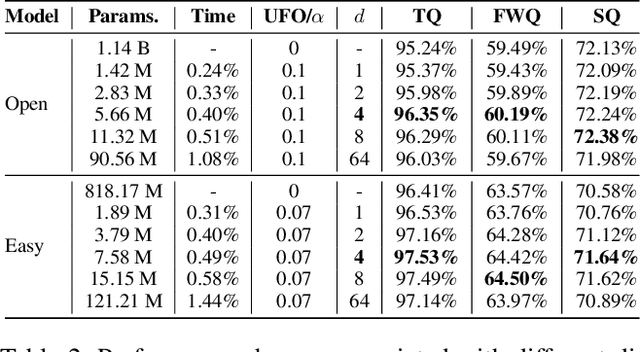
Recently, diffusion-based video generation models have achieved significant success. However, existing models often suffer from issues like weak consistency and declining image quality over time. To overcome these challenges, inspired by aesthetic principles, we propose a non-invasive plug-in called Uniform Frame Organizer (UFO), which is compatible with any diffusion-based video generation model. The UFO comprises a series of adaptive adapters with adjustable intensities, which can significantly enhance the consistency between the foreground and background of videos and improve image quality without altering the original model parameters when integrated. The training for UFO is simple, efficient, requires minimal resources, and supports stylized training. Its modular design allows for the combination of multiple UFOs, enabling the customization of personalized video generation models. Furthermore, the UFO also supports direct transferability across different models of the same specification without the need for specific retraining. The experimental results indicate that UFO effectively enhances video generation quality and demonstrates its superiority in public video generation benchmarks. The code will be publicly available at https://github.com/Delong-liu-bupt/UFO.
MindShot: Brain Decoding Framework Using Only One Image
May 24, 2024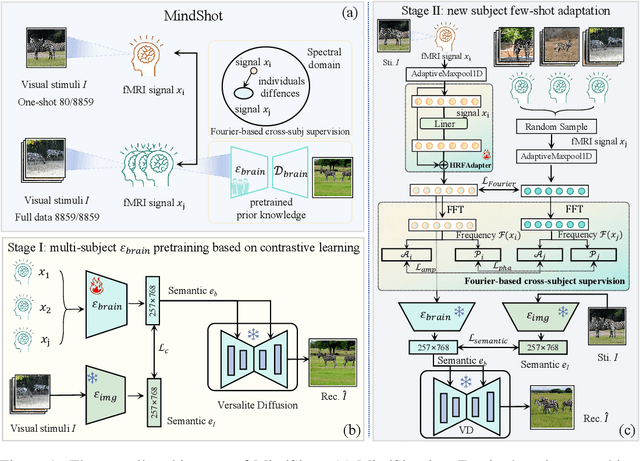
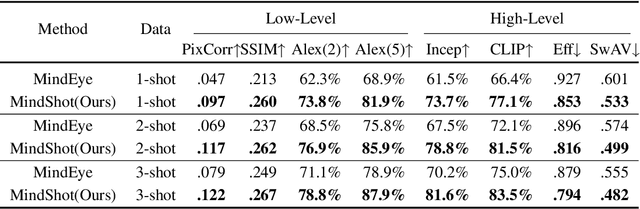
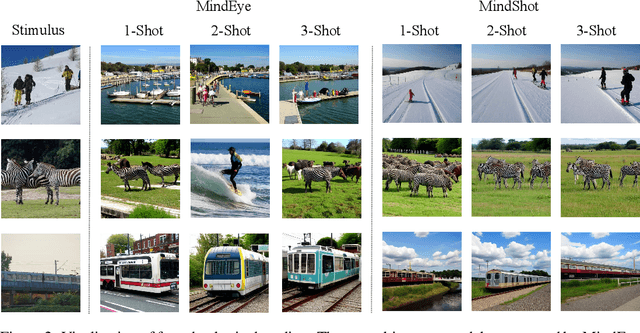
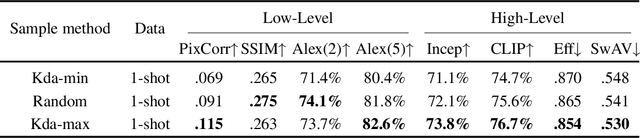
Brain decoding, which aims at reconstructing visual stimuli from brain signals, primarily utilizing functional magnetic resonance imaging (fMRI), has recently made positive progress. However, it is impeded by significant challenges such as the difficulty of acquiring fMRI-image pairs and the variability of individuals, etc. Most methods have to adopt the per-subject-per-model paradigm, greatly limiting their applications. To alleviate this problem, we introduce a new and meaningful task, few-shot brain decoding, while it will face two inherent difficulties: 1) the scarcity of fMRI-image pairs and the noisy signals can easily lead to overfitting; 2) the inadequate guidance complicates the training of a robust encoder. Therefore, a novel framework named MindShot, is proposed to achieve effective few-shot brain decoding by leveraging cross-subject prior knowledge. Firstly, inspired by the hemodynamic response function (HRF), the HRF adapter is applied to eliminate unexplainable cognitive differences between subjects with small trainable parameters. Secondly, a Fourier-based cross-subject supervision method is presented to extract additional high-level and low-level biological guidance information from signals of other subjects. Under the MindShot, new subjects and pretrained individuals only need to view images of the same semantic class, significantly expanding the model's applicability. Experimental results demonstrate MindShot's ability of reconstructing semantically faithful images in few-shot scenarios and outperforms methods based on the per-subject-per-model paradigm. The promising results of the proposed method not only validate the feasibility of few-shot brain decoding but also provide the possibility for the learning of large models under the condition of reducing data dependence.
MLS-Track: Multilevel Semantic Interaction in RMOT
Apr 18, 2024
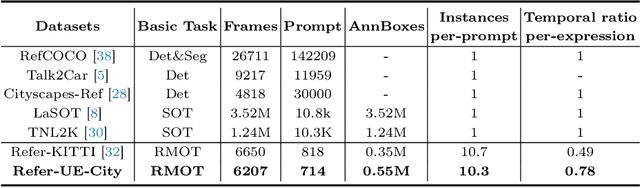
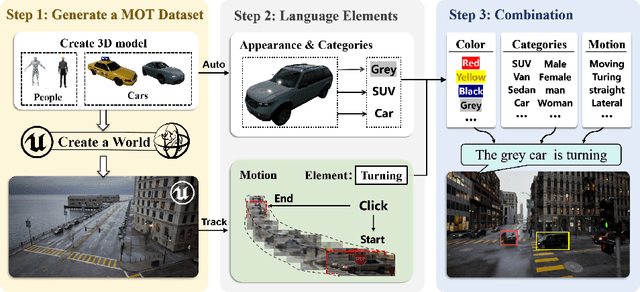
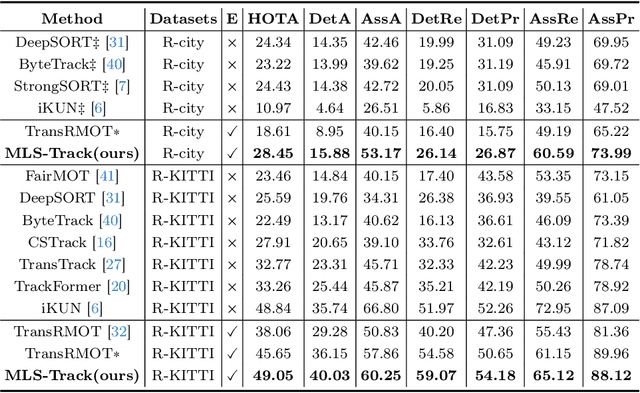
The new trend in multi-object tracking task is to track objects of interest using natural language. However, the scarcity of paired prompt-instance data hinders its progress. To address this challenge, we propose a high-quality yet low-cost data generation method base on Unreal Engine 5 and construct a brand-new benchmark dataset, named Refer-UE-City, which primarily includes scenes from intersection surveillance videos, detailing the appearance and actions of people and vehicles. Specifically, it provides 14 videos with a total of 714 expressions, and is comparable in scale to the Refer-KITTI dataset. Additionally, we propose a multi-level semantic-guided multi-object framework called MLS-Track, where the interaction between the model and text is enhanced layer by layer through the introduction of Semantic Guidance Module (SGM) and Semantic Correlation Branch (SCB). Extensive experiments on Refer-UE-City and Refer-KITTI datasets demonstrate the effectiveness of our proposed framework and it achieves state-of-the-art performance. Code and datatsets will be available.
Word for Person: Zero-shot Composed Person Retrieval
Nov 25, 2023



Searching for specific person has great security value and social benefits, and it often involves a combination of visual and textual information. Conventional person retrieval methods, whether image-based or text-based, usually fall short in effectively harnessing both types of information, leading to the loss of accuracy. In this paper, a whole new task called Composed Person Retrieval (CPR) is proposed to jointly utilize both image and text information for target person retrieval. However, the supervised CPR must depend on very costly manual annotation dataset, while there are currently no available resources. To mitigate this issue, we firstly introduce the Zero-shot Composed Person Retrieval (ZS-CPR), which leverages existing domain-related data to resolve the CPR problem without reliance on expensive annotations. Secondly, to learn ZS-CPR model, we propose a two-stage learning framework, Word4Per, where a lightweight Textual Inversion Network (TINet) and a text-based person retrieval model based on fine-tuned Contrastive Language-Image Pre-training (CLIP) network are learned without utilizing any CPR data. Thirdly, a finely annotated Image-Text Composed Person Retrieval dataset (ITCPR) is built as the benchmark to assess the performance of the proposed Word4Per framework. Extensive experiments under both Rank-1 and mAP demonstrate the effectiveness of Word4Per for the ZS-CPR task, surpassing the comparative methods by over 10%. The code and ITCPR dataset will be publicly available at https://github.com/Delong-liu-bupt/Word4Per.
Boundary-Refined Prototype Generation: A General End-to-End Paradigm for Semi-Supervised Semantic Segmentation
Jul 19, 2023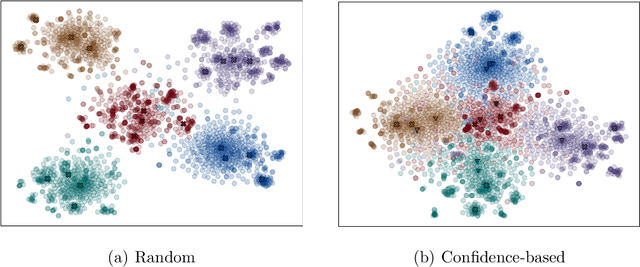
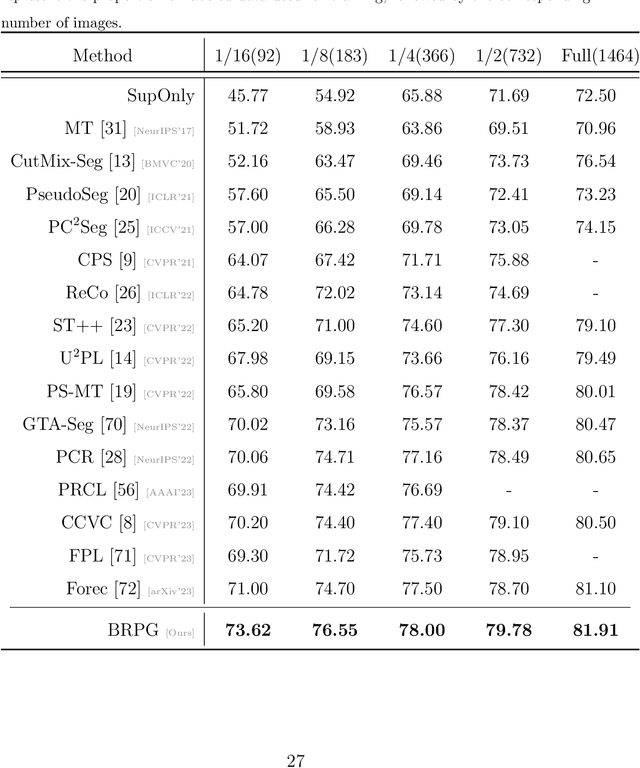
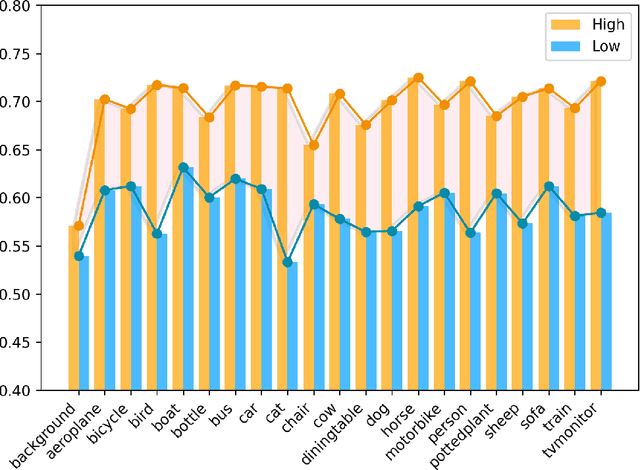
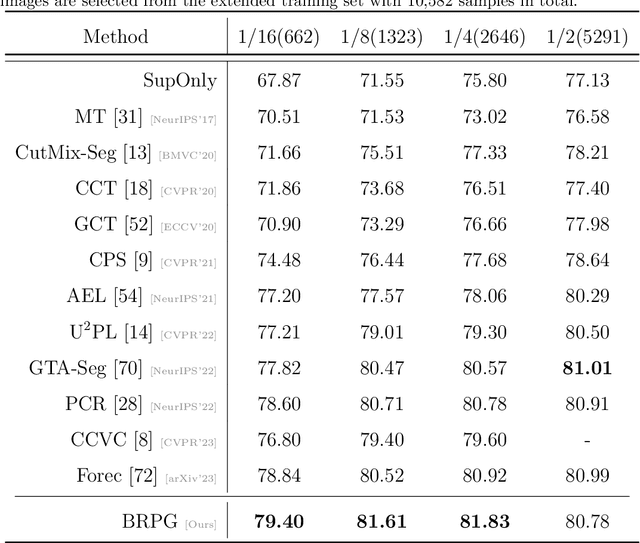
Prototype-based classification is a classical method in machine learning, and recently it has achieved remarkable success in semi-supervised semantic segmentation. However, the current approach isolates the prototype initialization process from the main training framework, which appears to be unnecessary. Furthermore, while the direct use of K-Means algorithm for prototype generation has considered rich intra-class variance, it may not be the optimal solution for the classification task. To tackle these problems, we propose a novel boundary-refined prototype generation (BRPG) method, which is incorporated into the whole training framework. Specifically, our approach samples and clusters high- and low-confidence features separately based on a confidence threshold, aiming to generate prototypes closer to the class boundaries. Moreover, an adaptive prototype optimization strategy is introduced to make prototype augmentation for categories with scattered feature distributions. Extensive experiments on the PASCAL VOC 2012 and Cityscapes datasets demonstrate the superiority and scalability of the proposed method, outperforming the current state-of-the-art approaches. The code is available at xxxxxxxxxxxxxx.
Unleashing the Imagination of Text: A Novel Framework for Text-to-image Person Retrieval via Exploring the Power of Words
Jul 18, 2023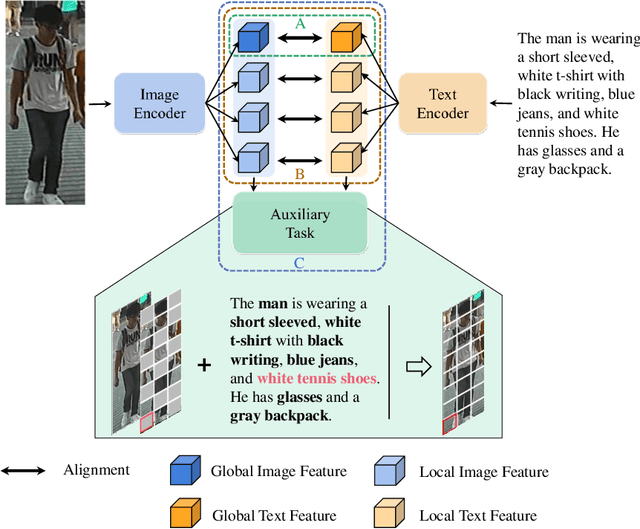
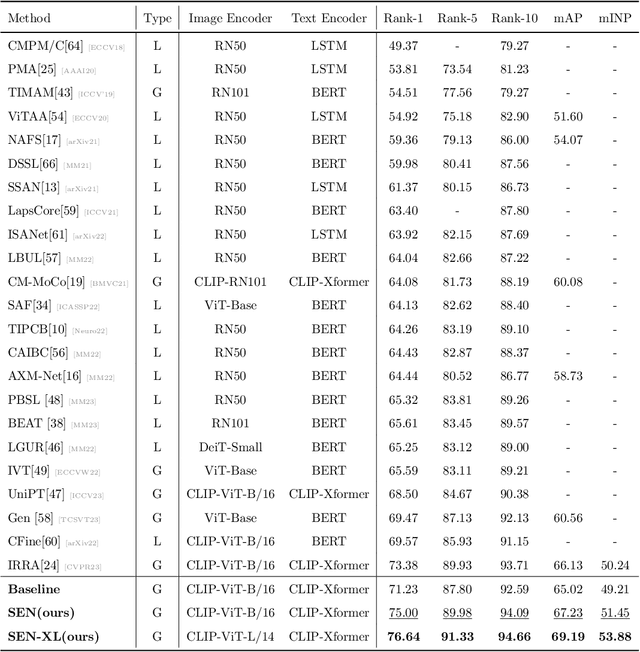
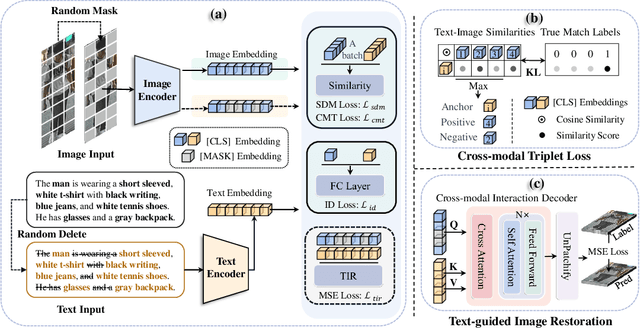
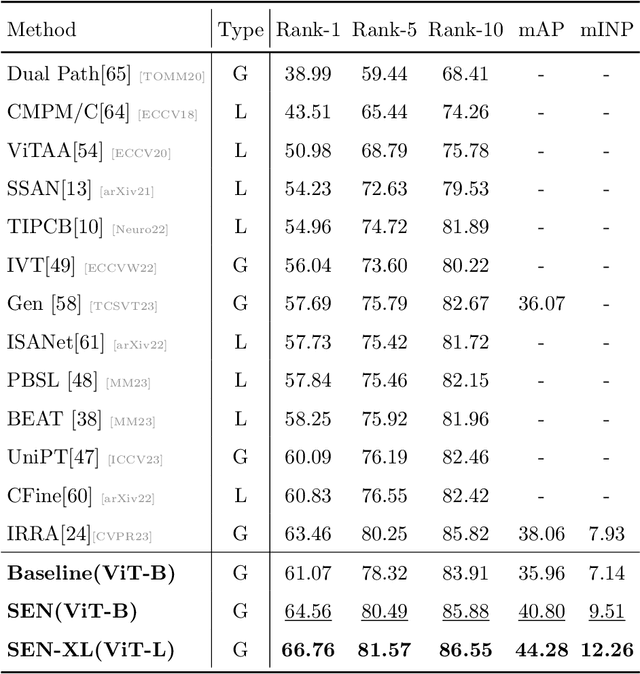
The goal of Text-to-image person retrieval is to retrieve person images from a large gallery that match the given textual descriptions. The main challenge of this task lies in the significant differences in information representation between the visual and textual modalities. The textual modality conveys abstract and precise information through vocabulary and grammatical structures, while the visual modality conveys concrete and intuitive information through images. To fully leverage the expressive power of textual representations, it is essential to accurately map abstract textual descriptions to specific images. To address this issue, we propose a novel framework to Unleash the Imagination of Text (UIT) in text-to-image person retrieval, aiming to fully explore the power of words in sentences. Specifically, the framework employs the pre-trained full CLIP model as a dual encoder for the images and texts , taking advantage of prior cross-modal alignment knowledge. The Text-guided Image Restoration auxiliary task is proposed with the aim of implicitly mapping abstract textual entities to specific image regions, facilitating alignment between textual and visual embeddings. Additionally, we introduce a cross-modal triplet loss tailored for handling hard samples, enhancing the model's ability to distinguish minor differences. To focus the model on the key components within sentences, we propose a novel text data augmentation technique. Our proposed methods achieve state-of-the-art results on three popular benchmark datasets, and the source code will be made publicly available shortly.
OpenDriver: an open-road driver state detection dataset
Apr 09, 2023



In modern society, road safety relies heavily on the psychological and physiological state of drivers. Negative factors such as fatigue, drowsiness, and stress can impair drivers' reaction time and decision making abilities, leading to an increased incidence of traffic accidents. Among the numerous studies for impaired driving detection, wearable physiological measurement is a real-time approach to monitoring a driver's state. However, currently, there are few driver physiological datasets in open road scenarios and the existing datasets suffer from issues such as poor signal quality, small sample sizes, and short data collection periods. Therefore, in this paper, a large-scale multimodal driving dataset for driver impairment detection and biometric data recognition is designed and described. The dataset contains two modalities of driving signals: six-axis inertial signals and electrocardiogram (ECG) signals, which were recorded while over one hundred drivers were following the same route through open roads during several months. Both the ECG signal sensor and the six-axis inertial signal sensor are installed on a specially designed steering wheel cover, allowing for data collection without disturbing the driver. Additionally, electrodermal activity (EDA) signals were also recorded during the driving process and will be integrated into the presented dataset soon. Future work can build upon this dataset to advance the field of driver impairment detection. New methods can be explored for integrating other types of biometric signals, such as eye tracking, to further enhance the understanding of driver states. The insights gained from this dataset can also inform the development of new driver assistance systems, promoting safer driving practices and reducing the risk of traffic accidents. The OpenDriver dataset will be publicly available soon.
1st Workshop on Maritime Computer Vision 2023: Challenge Results
Nov 28, 2022

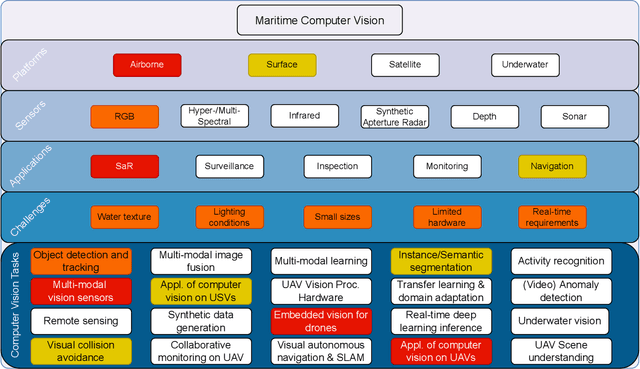
The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.