 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Imagination of Text: A Novel Framework for Text-to-image Person Retrieval via Exploring the Power of Words
Paper and Code
Jul 18, 2023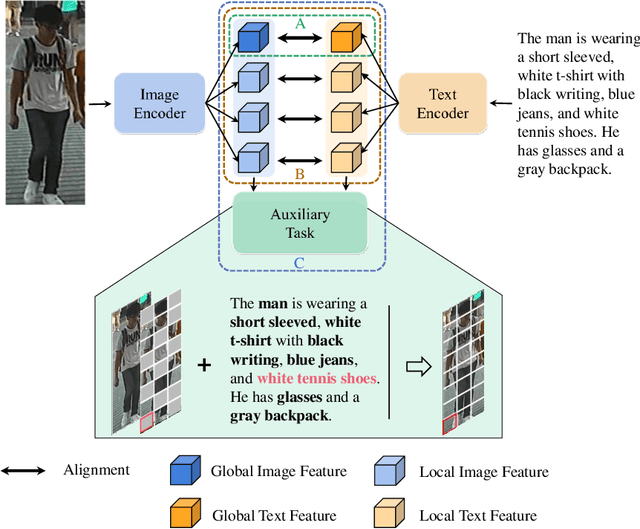
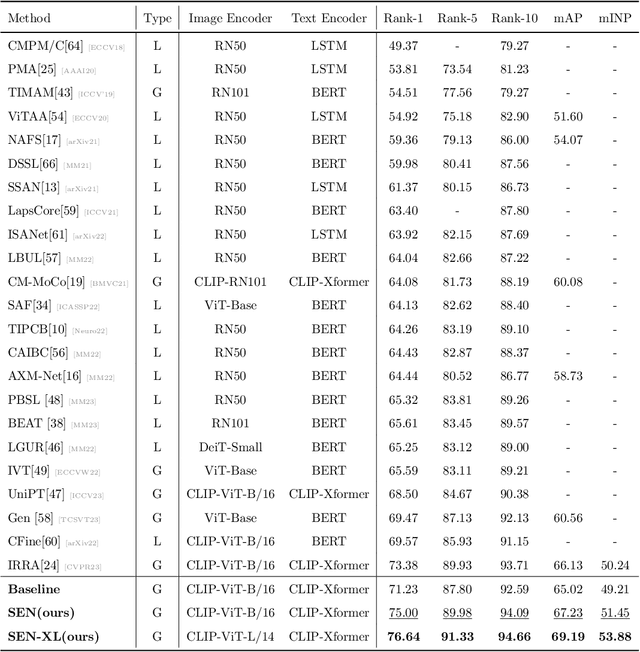
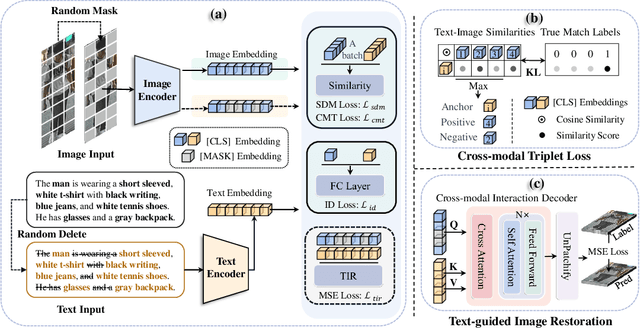
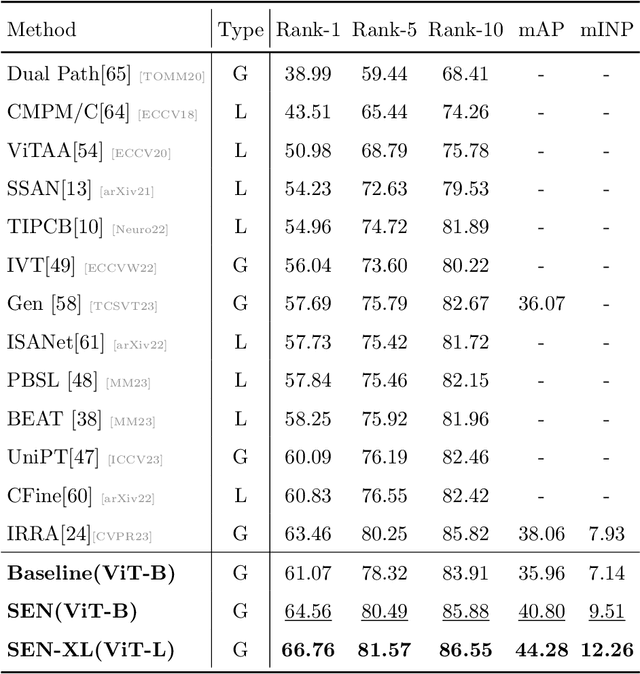
The goal of Text-to-image person retrieval is to retrieve person images from a large gallery that match the given textual descriptions. The main challenge of this task lies in the significant differences in information representation between the visual and textual modalities. The textual modality conveys abstract and precise information through vocabulary and grammatical structures, while the visual modality conveys concrete and intuitive information through images. To fully leverage the expressive power of textual representations, it is essential to accurately map abstract textual descriptions to specific images. To address this issue, we propose a novel framework to Unleash the Imagination of Text (UIT) in text-to-image person retrieval, aiming to fully explore the power of words in sentences. Specifically, the framework employs the pre-trained full CLIP model as a dual encoder for the images and texts , taking advantage of prior cross-modal alignment knowledge. The Text-guided Image Restoration auxiliary task is proposed with the aim of implicitly mapping abstract textual entities to specific image regions, facilitating alignment between textual and visual embeddings. Additionally, we introduce a cross-modal triplet loss tailored for handling hard samples, enhancing the model's ability to distinguish minor differences. To focus the model on the key components within sentences, we propose a novel text data augmentation technique. Our proposed methods achieve state-of-the-art results on three popular benchmark datasets, and the source code will be made publicly available shortly.