 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Deep Representation Learning for Event-Enhanced Visual Autonomous Perception: the eAP Dataset
Mar 17, 2026Recent visual autonomous perception systems achieve remarkable performances with deep representation learning. However, they fail in scenarios with challenging illumination.While event cameras can mitigate this problem, there is a lack of a large-scale dataset to develop event-enhanced deep visual perception models in autonomous driving scenes. To address the gap, we present the eAP (event-enhanced Autonomous Perception) dataset, the largest dataset with event cameras for autonomous perception. We demonstrate how eAP can facilitate the study of different autonomous perception tasks, including 3D vehicle detection and object time-to-contact (TTC) estimation, through deep representation learning. Based on eAP, we demonstrate the ffrst successful use of events to improve a popular 3D vehicle detection network in challenging illumination scenarios. eAP also enables a devoted study of the representation learning problem of object TTC estimation. We show how a geometryaware representation learning framework leads to the best eventbased object TTC estimation network that operates at 200 FPS. The dataset, code, and pre-trained models will be made publicly available for future research.
Learning better representations for crowded pedestrians in offboard LiDAR-camera 3D tracking-by-detection
May 21, 2025Perceiving pedestrians in highly crowded urban environments is a difficult long-tail problem for learning-based autonomous perception. Speeding up 3D ground truth generation for such challenging scenes is performance-critical yet very challenging. The difficulties include the sparsity of the captured pedestrian point cloud and a lack of suitable benchmarks for a specific system design study. To tackle the challenges, we first collect a new multi-view LiDAR-camera 3D multiple-object-tracking benchmark of highly crowded pedestrians for in-depth analysis. We then build an offboard auto-labeling system that reconstructs pedestrian trajectories from LiDAR point cloud and multi-view images. To improve the generalization power for crowded scenes and the performance for small objects, we propose to learn high-resolution representations that are density-aware and relationship-aware. Extensive experiments validate that our approach significantly improves the 3D pedestrian tracking performance towards higher auto-labeling efficiency. The code will be publicly available at this HTTP URL.
A Multi-Modal Deep Learning Framework for Pan-Cancer Prognosis
Jan 13, 2025Prognostic task is of great importance as it closely related to the survival analysis of patients, the optimization of treatment plans and the allocation of resources. The existing prognostic models have shown promising results on specific datasets, but there are limitations in two aspects. On the one hand, they merely explore certain types of modal data, such as patient histopathology WSI and gene expression analysis. On the other hand, they adopt the per-cancer-per-model paradigm, which means the trained models can only predict the prognostic effect of a single type of cancer, resulting in weak generalization ability. In this paper, a deep-learning based model, named UMPSNet, is proposed. Specifically, to comprehensively understand the condition of patients, in addition to constructing encoders for histopathology images and genomic expression profiles respectively, UMPSNet further integrates four types of important meta data (demographic information, cancer type information, treatment protocols, and diagnosis results) into text templates, and then introduces a text encoder to extract textual features. In addition, the optimal transport OT-based attention mechanism is utilized to align and fuse features of different modalities. Furthermore, a guided soft mixture of experts (GMoE) mechanism is introduced to effectively address the issue of distribution differences among multiple cancer datasets. By incorporating the multi-modality of patient data and joint training, UMPSNet outperforms all SOTA approaches, and moreover, it demonstrates the effectiveness and generalization ability of the proposed learning paradigm of a single model for multiple cancer types. The code of UMPSNet is available at https://github.com/binging512/UMPSNet.
OpenDriver: an open-road driver state detection dataset
Apr 09, 2023



In modern society, road safety relies heavily on the psychological and physiological state of drivers. Negative factors such as fatigue, drowsiness, and stress can impair drivers' reaction time and decision making abilities, leading to an increased incidence of traffic accidents. Among the numerous studies for impaired driving detection, wearable physiological measurement is a real-time approach to monitoring a driver's state. However, currently, there are few driver physiological datasets in open road scenarios and the existing datasets suffer from issues such as poor signal quality, small sample sizes, and short data collection periods. Therefore, in this paper, a large-scale multimodal driving dataset for driver impairment detection and biometric data recognition is designed and described. The dataset contains two modalities of driving signals: six-axis inertial signals and electrocardiogram (ECG) signals, which were recorded while over one hundred drivers were following the same route through open roads during several months. Both the ECG signal sensor and the six-axis inertial signal sensor are installed on a specially designed steering wheel cover, allowing for data collection without disturbing the driver. Additionally, electrodermal activity (EDA) signals were also recorded during the driving process and will be integrated into the presented dataset soon. Future work can build upon this dataset to advance the field of driver impairment detection. New methods can be explored for integrating other types of biometric signals, such as eye tracking, to further enhance the understanding of driver states. The insights gained from this dataset can also inform the development of new driver assistance systems, promoting safer driving practices and reducing the risk of traffic accidents. The OpenDriver dataset will be publicly available soon.
SDQ: Stochastic Differentiable Quantization with Mixed Precision
Jun 17, 2022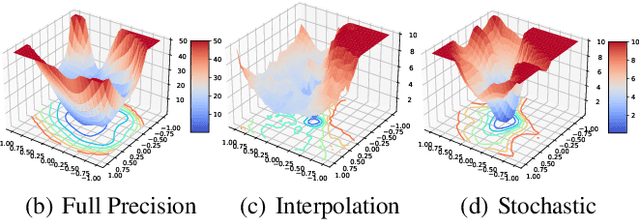
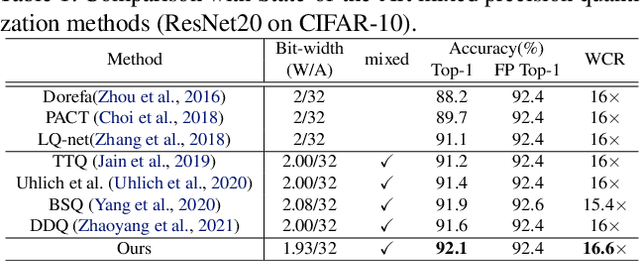
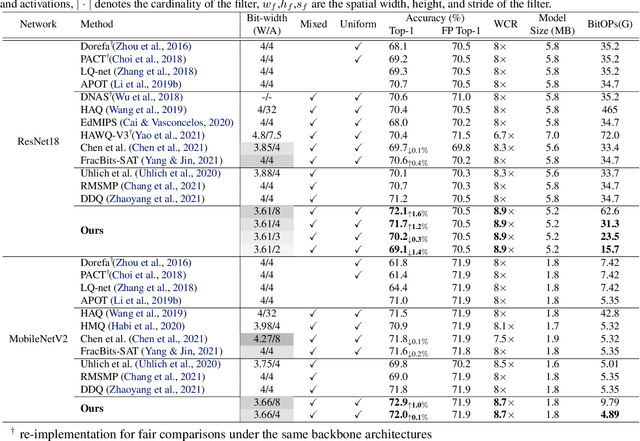
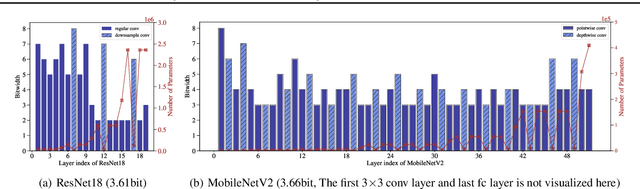
In order to deploy deep models in a computationally efficient manner, model quantization approaches have been frequently used. In addition, as new hardware that supports mixed bitwidth arithmetic operations, recent research on mixed precision quantization (MPQ) begins to fully leverage the capacity of representation by searching optimized bitwidths for different layers and modules in a network. However, previous studies mainly search the MPQ strategy in a costly scheme using reinforcement learning, neural architecture search, etc., or simply utilize partial prior knowledge for bitwidth assignment, which might be biased and sub-optimal. In this work, we present a novel Stochastic Differentiable Quantization (SDQ) method that can automatically learn the MPQ strategy in a more flexible and globally-optimized space with smoother gradient approximation. Particularly, Differentiable Bitwidth Parameters (DBPs) are employed as the probability factors in stochastic quantization between adjacent bitwidth choices. After the optimal MPQ strategy is acquired, we further train our network with entropy-aware bin regularization and knowledge distillation. We extensively evaluate our method for several networks on different hardware (GPUs and FPGA) and datasets. SDQ outperforms all state-of-the-art mixed or single precision quantization with a lower bitwidth and is even better than the full-precision counterparts across various ResNet and MobileNet families, demonstrating the effectiveness and superiority of our method.
Stereo Neural Vernier Caliper
Mar 26, 2022

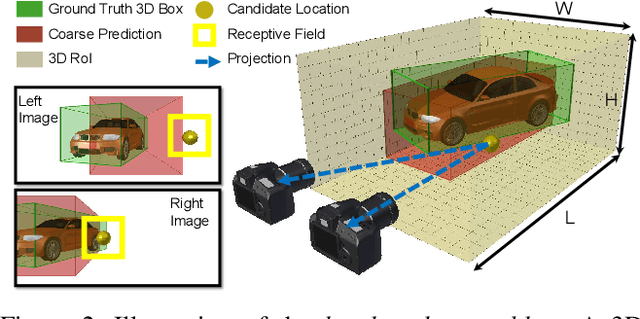

We propose a new object-centric framework for learning-based stereo 3D object detection. Previous studies build scene-centric representations that do not consider the significant variation among outdoor instances and thus lack the flexibility and functionalities that an instance-level model can offer. We build such an instance-level model by formulating and tackling a local update problem, i.e., how to predict a refined update given an initial 3D cuboid guess. We demonstrate how solving this problem can complement scene-centric approaches in (i) building a coarse-to-fine multi-resolution system, (ii) performing model-agnostic object location refinement, and (iii) conducting stereo 3D tracking-by-detection. Extensive experiments demonstrate the effectiveness of our approach, which achieves state-of-the-art performance on the KITTI benchmark. Code and pre-trained models are available at https://github.com/Nicholasli1995/SNVC.
Joint stereo 3D object detection and implicit surface reconstruction
Nov 25, 2021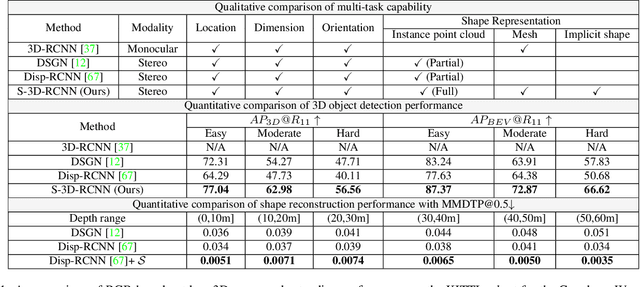
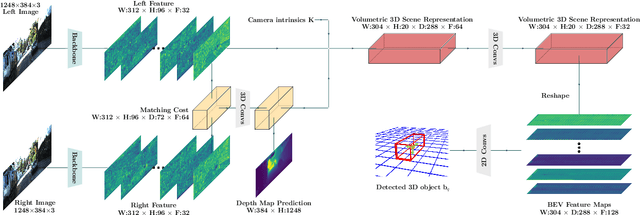
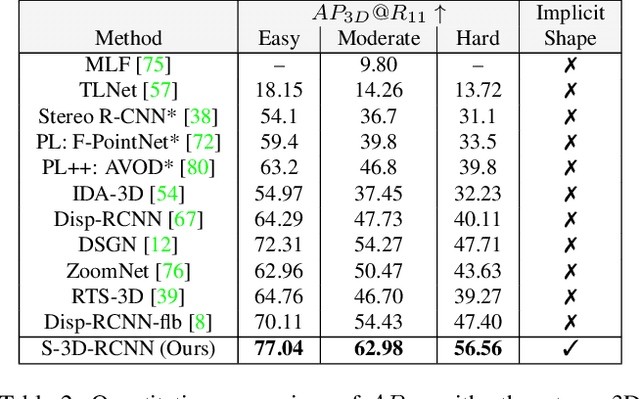
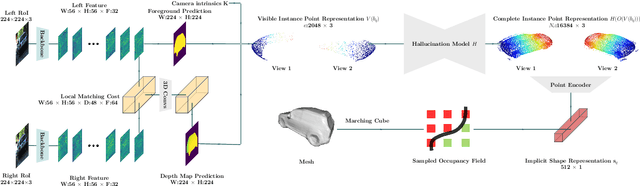
We present the first learning-based framework for category-level 3D object detection and implicit shape estimation based on a pair of stereo RGB images in the wild. Traditional stereo 3D object detection approaches describe the detected objects only with 3D bounding boxes and cannot infer their full surface geometry, which makes creating a realistic outdoor immersive experience difficult. In contrast, we propose a new model S-3D-RCNN that can perform precise localization as well as provide a complete and resolution-agnostic shape description for the detected objects. We first decouple the estimation of object coordinate systems from shape reconstruction using a global-local framework. We then propose a new instance-level network that addresses the unseen surface hallucination problem by extracting point-based representations from stereo region-of-interests, and infers implicit shape codes with predicted complete surface geometry. Extensive experiments validate our approach's superior performance using existing and new metrics on the KITTI benchmark. Code and pre-trained models will be available at this https URL.
How Do Adam and Training Strategies Help BNNs Optimization?
Jun 21, 2021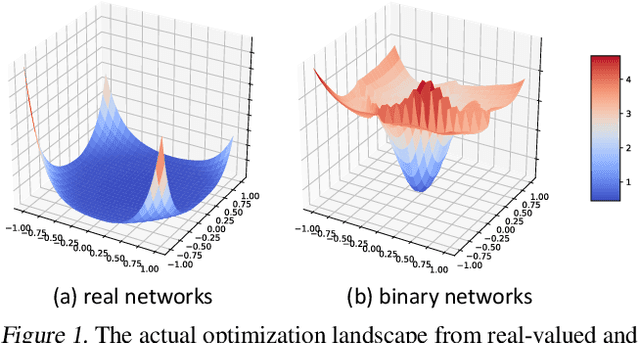


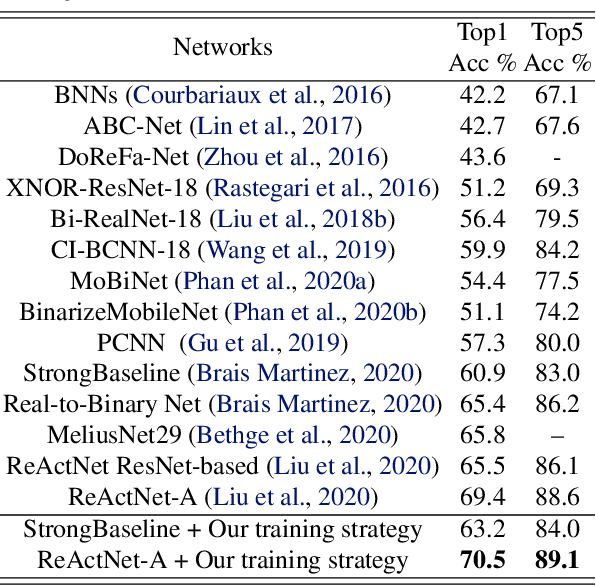
The best performing Binary Neural Networks (BNNs) are usually attained using Adam optimization and its multi-step training variants. However, to the best of our knowledge, few studies explore the fundamental reasons why Adam is superior to other optimizers like SGD for BNN optimization or provide analytical explanations that support specific training strategies. To address this, in this paper we first investigate the trajectories of gradients and weights in BNNs during the training process. We show the regularization effect of second-order momentum in Adam is crucial to revitalize the weights that are dead due to the activation saturation in BNNs. We find that Adam, through its adaptive learning rate strategy, is better equipped to handle the rugged loss surface of BNNs and reaches a better optimum with higher generalization ability. Furthermore, we inspect the intriguing role of the real-valued weights in binary networks, and reveal the effect of weight decay on the stability and sluggishness of BNN optimization. Through extensive experiments and analysis, we derive a simple training scheme, building on existing Adam-based optimization, which achieves 70.5% top-1 accuracy on the ImageNet dataset using the same architecture as the state-of-the-art ReActNet while achieving 1.1% higher accuracy. Code and models are available at https://github.com/liuzechun/AdamBNN.
Exploring Intermediate Representation for Monocular Vehicle Pose Estimation
Nov 17, 2020



We present a new learning-based approach to recover egocentric 3D vehicle pose from a single RGB image. In contrast to previous works that directly map from local appearance to 3D angles, we explore a progressive approach by extracting meaningful Intermediate Geometrical Representations (IGRs) for 3D pose estimation. We design a deep model that transforms perceived intensities to IGRs, which are mapped to a 3D representation encoding object orientation in the camera coordinate system. To fulfill our goal, we need to specify what IGRs to use and how to learn them more effectively. We answer the former question by designing an interpolated cuboid representation that derives from primitive 3D annotation readily. The latter question motivates us to incorporate geometry knowledge by designing a new loss function based on a projective invariant. This loss function allows unlabeled data to be used in the training stage which is validated to improve representation learning. Our system outperforms previous monocular RGB-based methods for joint vehicle detection and pose estimation on the KITTI benchmark, achieving performance even comparable to stereo methods. Code and pre-trained models will be available at the project website.
GSNet: Joint Vehicle Pose and Shape Reconstruction with Geometrical and Scene-aware Supervision
Jul 26, 2020

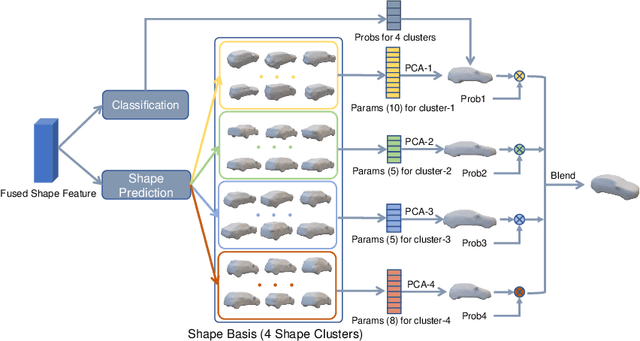

We present a novel end-to-end framework named as GSNet (Geometric and Scene-aware Network), which jointly estimates 6DoF poses and reconstructs detailed 3D car shapes from single urban street view. GSNet utilizes a unique four-way feature extraction and fusion scheme and directly regresses 6DoF poses and shapes in a single forward pass. Extensive experiments show that our diverse feature extraction and fusion scheme can greatly improve model performance. Based on a divide-and-conquer 3D shape representation strategy, GSNet reconstructs 3D vehicle shape with great detail (1352 vertices and 2700 faces). This dense mesh representation further leads us to consider geometrical consistency and scene context, and inspires a new multi-objective loss function to regularize network training, which in turn improves the accuracy of 6D pose estimation and validates the merit of jointly performing both tasks. We evaluate GSNet on the largest multi-task ApolloCar3D benchmark and achieve state-of-the-art performance both quantitatively and qualitatively. Project page is available at https://lkeab.github.io/gsnet/.