 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Mortgage Default with Machine Learning: AutoML, Class Imbalance, and Leakage Control
Jan 27, 2026Mortgage default prediction is a core task in financial risk management, and machine learning models are increasingly used to estimate default probabilities and provide interpretable signals for downstream decisions. In real-world mortgage datasets, however, three factors frequently undermine evaluation validity and deployment reliability: ambiguity in default labeling, severe class imbalance, and information leakage arising from temporal structure and post-event variables. We compare multiple machine learning approaches for mortgage default prediction using a real-world loan-level dataset, with emphasis on leakage control and imbalance handling. We employ leakage-aware feature selection, a strict temporal split that constrains both origination and reporting periods, and controlled downsampling of the majority class. Across multiple positive-to-negative ratios, performance remains stable, and an AutoML approach (AutoGluon) achieves the strongest AUROC among the models evaluated. An extended and pedagogical version of this work will appear as a book chapter.
MFAI: A Scalable Bayesian Matrix Factorization Approach to Leveraging Auxiliary Information
Mar 05, 2023In various practical situations, matrix factorization methods suffer from poor data quality, such as high data sparsity and low signal-to-noise ratio (SNR). Here we consider a matrix factorization problem by utilizing auxiliary information, which is massively available in real applications, to overcome the challenges caused by poor data quality. Unlike existing methods that mainly rely on simple linear models to combine auxiliary information with the main data matrix, we propose to integrate gradient boosted trees in the probabilistic matrix factorization framework to effectively leverage auxiliary information (MFAI). Thus, MFAI naturally inherits several salient features of gradient boosted trees, such as the capability of flexibly modeling nonlinear relationships, and robustness to irrelevant features and missing values in auxiliary information. The parameters in MAFI can be automatically determined under the empirical Bayes framework, making it adaptive to the utilization of auxiliary information and immune to overfitting. Moreover, MFAI is computationally efficient and scalable to large-scale datasets by exploiting variational inference. We demonstrate the advantages of MFAI through comprehensive numerical results from simulation studies and real data analysis. Our approach is implemented in the R package mfair available at https://github.com/YangLabHKUST/mfair.
SDQ: Stochastic Differentiable Quantization with Mixed Precision
Jun 17, 2022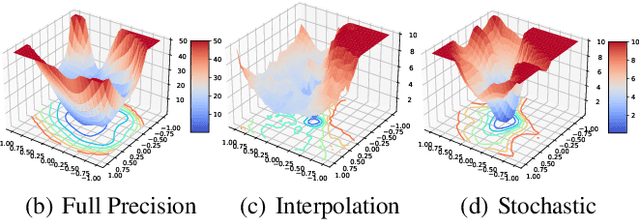
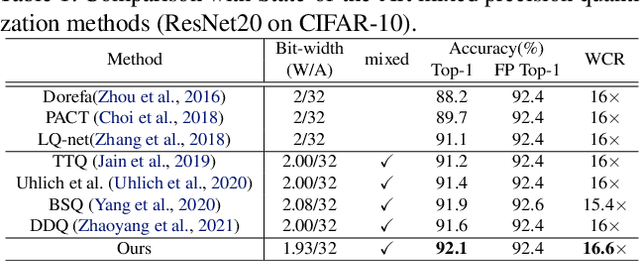
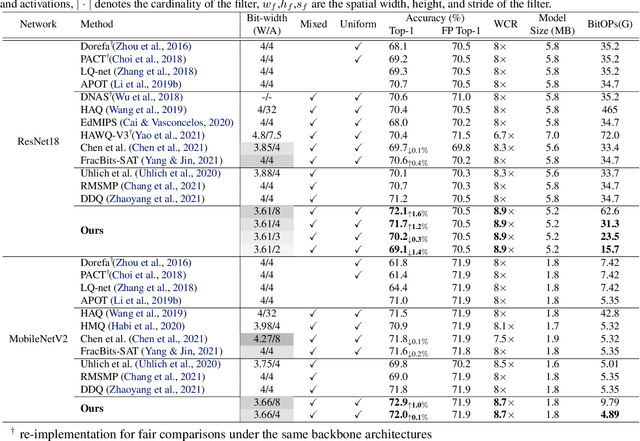
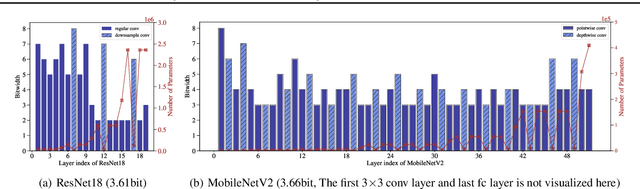
In order to deploy deep models in a computationally efficient manner, model quantization approaches have been frequently used. In addition, as new hardware that supports mixed bitwidth arithmetic operations, recent research on mixed precision quantization (MPQ) begins to fully leverage the capacity of representation by searching optimized bitwidths for different layers and modules in a network. However, previous studies mainly search the MPQ strategy in a costly scheme using reinforcement learning, neural architecture search, etc., or simply utilize partial prior knowledge for bitwidth assignment, which might be biased and sub-optimal. In this work, we present a novel Stochastic Differentiable Quantization (SDQ) method that can automatically learn the MPQ strategy in a more flexible and globally-optimized space with smoother gradient approximation. Particularly, Differentiable Bitwidth Parameters (DBPs) are employed as the probability factors in stochastic quantization between adjacent bitwidth choices. After the optimal MPQ strategy is acquired, we further train our network with entropy-aware bin regularization and knowledge distillation. We extensively evaluate our method for several networks on different hardware (GPUs and FPGA) and datasets. SDQ outperforms all state-of-the-art mixed or single precision quantization with a lower bitwidth and is even better than the full-precision counterparts across various ResNet and MobileNet families, demonstrating the effectiveness and superiority of our method.